
XML e JSON
Un XML è un file di testo che ha lo scopo di fornire informazione in forma strutturata. Esso nasce insieme al World Wide Web con lo scopo di fornire un formato per l’invio di dati utilizzando il protocollo http. Il tipo di informazione per cui è pensato XML è di tipo formale e strutturato, ed è stato progettato tenendo conto di trasportare contenuti come il risultato di query di database SQL, fogli Excel (anche annidati), ma anche la serializzazione di oggetti di linguaggi ad alto livello, come Java, come anche la descrizione di interfacce per API, come ad esempio SOAP.
XML non è un linguaggio utilizzato per dare istruzioni alla macchina, ma per descrivere il dato. La sua utilità consiste da una parte nel fatto di essere leggibile dall’uomo, dall’altra dal fatto di avere delle caratteristiche che lo rendono validabile sintatticamente e semanticamente da strumenti automatici, e quindi poter permettere ad un sistema automatico (cioè ad un software) di estrarre (e volendo anche di inserire) porzioni di informazione.
I file XML sono documenti con una struttura gerarchica, dove i singoli componenti (detti elementi) sono annidati uno dentro l’altro a partire da un elemento radice (root element). La struttura che viene a formare un XML è a tutti gli effetti un albero, graficamente rappresentabile come tale.
Vediamo un esempio di struttura:
<paragrafo>
<frase>
Sono una frase
</frase>
<frase>
Sono una frase
</frase>
<frase>
Sono una frase
</frase>
</paragrafo> Struttura corrispondente:
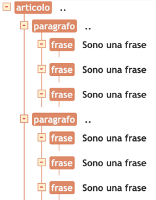
Le regole sintattiche
Un XML è un documento che descrive un albero i cui nodi sono elementi, che sono definiti da tag e possono contenere altri elementi definiti tramite tag.
Un tag ha seguente forma:
<tagName attr1="value1" attr2="value2>…</tagName>
Un elemento contiene quindi un contenuto, cioè uno o più elementi, e degli attributi, contenuti nella definizione del tag. Il tag deve essere sempre chiuso alla fine.
E’ prevista poi una sintassi abbreviata per gli elementi vuoti. Esempio:
<miotag/>
Più in generale le regole sintattiche sono queste:
- Una struttura di elementi organizzata ad albero;
- Un solo elemento radice;
- I tag aperti devono avere il corrispondente tag di chiusura;
- La nidificazione deve essere corretta (va chiuso un tag interno prima di chiuderne uno esterno);
- Si devono rispettare maiuscole e minuscole;
- Non sono ammessi spazi;
- I tag iniziano con una lettera o _ e possono contenere lettere, numeri, ., _ e -;
- Gli attributi sono definiti nella forma sopra indicata.
- Un documento comincia con la definizione del formato xml, della versione e del tipo di encoding (l’encoding è il set di caratteri utilizzato).
Vediamo un esempio più completo.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>Per rappresentare un XML all’interno di un altro si usa la struttura CDATA nel seguente modo:
<code>
<![CDATA[
<book>
<title>
My title
</title>
</book>
]]>
</code>I seguenti caratteri speciali che fanno parte di XML vanno poi codificati secondo la seguente tabella:
| Entità | Codifica |
| & | & |
| < | < |
| > | > |
| “ | " |
| ‘ | ' |
Infine è possibile commentare un XML con il seguente tag speciale:
<!-- This is a comment -->
Esistono strumenti automatici per la validazione formale degli XML per verificarne la struttura sintattica.
Documenti che rispettano queste regole vengono detti “ben formati” (well-formed).
Regole semantiche
Un XML oltre che una validazione sintattica, necessaria per essere analizzato da uno strumento automatico, può avere una validazione semantica. Ciò vuol dire che ha una grammatica, cioè un insieme di regole che identificano quali sono i tag validi e i relativi attributi, e che struttura annidata può avere l’albero degli elementi.
Le grammatiche sono definite in documenti speciali, che possono essere in formato XML Schema (qui non analizzato) o DTD, che vedremo qui sotto.
Se un documento XML è compatibile con una determinata grammatica (che sia XML Schema o DTD) si dice che è valido per quello schema. Anche in questo caso la validazione può essere effettuata da strumenti automatici.
La necessità di un documento di definizione è duplice: da una parte permette di verificare se la compilazione automatica dell’XML segue le regole semantiche, dall’altra permette al sistema che possiede la grammatica di generare o interpretare XML ed estrarre quindi informazione utile.
DTD
Il sistema di grammatica più semplice, il DTD, si basa su una documento che definisce una lista di tag. Questo documento può essere interno al file XML (quindi la grammatica è integrata nel documento stesso) oppure richiamato esternamente, in un file separato.
Ha la seguente sintassi (notare che non è in formato XML semanticamente corretto):
<!DOCTYPE element [declarations]>
Dove element è il root element dell’XML e [declarations] sono le dichiarazioni dei nodi-tag e dei relativi attributi.
Ciascun tag è quindi definito nel seguente modo:
<!ELEMENT tagName (tag1,tag2,…)>
Dove l’elemento tagName rappresenta il nome del tag e gli elementi contenuti nelle parentesi sono i tag figli.
I figli possono avere un modificatore che ne indica la molteplicità:
? per indicare 0 o 1 elemento
+ per indicare 1 o più elementi
* per indicare 0 o più elementi
Quindi ad esempio:
<!ELEMENT bookstore (book*)>
indica un tag che si chiama “bookstore” che può avere 0 o più nodi figli di tipo book.
<!ELEMENT book (title+, author+, year+, price+)>
Indica che l’elemento “book” dovrà avere almeno un nodo figlio di ciascuno dei tipi indicati.
Gli elementi foglia che infine non contengono sottoelementi si indicano nel seguente modo:
<!ELEMENT year (#PCDATA)>
Indica che il contenuto del tag sarà di fomato testo.
Un elemento può essere foglia e non deve contenere nulla:
<!ELEMENT image EMPTY>
E’ possibile definire elementi senza imporre una specifica grammatica per il loro contenuto.
<!ELEMENT content ANY>
Gli attributi invece sono definiti nel seguente modo:
<!ATTLIST tag
attr1 type modifier
attr2 type modifier >
Dove all’elemento tag corrisponde l’attributo attr, con type che può essere CDATA (cioè testo libero), oppure NMTOKEN (testo senza spazi) oppure una sequenza di valori alternativi (vedi sotto). Il modifier indica invece se un attributo è obbligatorio (#REQUIRED), facoltativo (#IMPLIED) o fisso (#FIXED).
Qualche esempio:
<!ATTLIST article author CDATA #IMPLIED>
Indica che l’elemento article ha un attributo author con valore testo libero ed è facoltativo.
<!ATTLIST manufacturer company NMTOKEN #FIXED “Google”>
Per attributi con valore fisso definito in modo esplicito.
Ad esempio l’XML della pagina precedente può essere qui definito:
<?xml encoding="UTF-8"?>
<!ELEMENT bookstore (book)+>
<!ELEMENT book (title,author,year,price)>
<!ATTLIST book
category NMTOKEN #REQUIRED>
<!ELEMENT title (#PCDATA)>
<!ATTLIST title
lang NMTOKEN #REQUIRED>
<!ELEMENT author (#PCDATA)>
<!ELEMENT year (#PCDATA)>
<!ELEMENT price (#PCDATA)>Interrogazione di XML
Una volta creati file XML sintatticamente e semanticamente corretti, è possibile utilizzarli per memorizzare informazione, da salvare su filesystem e/o da inviare ad un destinatario.
Il soggetto che legge un file XML, dopo averlo validato, può quindi utilizzarlo per estrarre informazione. Questa attività viene chiamata parsing. Esistono software specifici che si occupano di parsing di XML, trasformando quindi il file di testo in un modello dati in memoria. Sono quindi previste specifiche API per l’interrogazione di un file XML, di cui le due più importanti sono:
- XPath: è un linguaggio di query che viene utilizzato per interrogare ed individuare nodi all’interno di un file XML. Ha una sintassi basata sul concetto di “path expression” e concepisce quindi l’XML come se fosse un filesystem, e il linguaggio stesso struttura le sue espressioni come se fossero URL. E’ quindi possibile interrogare l’XML come se fosse un filesystem, e indicando il nodo di interesse proprio come un path (“/bookstore/book/title”). Sono previste query per richiedere uno specifico nodo di una lista (ad esempio “/bookstore/*[1]” richiede il primo libro).
- DOM: il “Document Object Model” ha un approccio differente, perché trasforma l’XML in una gerarchia di oggetti, con quindi proprietà e caratteristiche, e metodi per l’accesso ai dati. In realtà il DOM non nasce per XML ma per HTML (HTML nasce contestualmente e come costola di XML), e per permettere a Javascript di accedere alle risorse della pagina, ma poi successivamente alla formalizzazione delle specifiche del DOM (con EcmaScript 4 – noto come Javascript – nello standard del 1999, poi esteso nel 2009 con ES5, e nel 2015 con ES6). Tuttavia il meccanismo del DOM è stato portato su XML e permette quindi di interrogare e modificare documenti XML.
JSON
JSON (JavaScript Object Notation) è un formato di scambio dati basato su documenti di testo leggibili dall’uomo, nativo per Javascript ma che è realizzabile in qualsiasi linguaggio. Linguaggi come Java, C#, PHP, Swift, Python ed altri supportano nativamente JSON come formato di scambio dati, la cui sintassi di base è facilmente comprensibile a qualsiasi programmatore di linguaggio C o derivati.
JSON si basa su:
- Object
{
name: value,
...
name: value
}- Array:
[value, … value]Dove name è una stringa, e value è una qualsiasi struttura valida.
- Value:
| Nome | Valore |
| string | Sequenza alfanumerica tra apici singoli o doppi. Sono previsti codici di escape per gestire caratteri speciali |
| number | Numero sia intero che decimale |
| object | Oggetto sopra descritto |
| array | Array sopra descritto |
| true|false | Valore booleano |
| null | Oggetto vuoto |
Esempi:
———————————————————————-
{
“name”: “Mario”,
“lastName”: “Rossi”
}———————————————————————-
{
"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}
}———————————————————————-
[
{
color: "red",
value: "#f00"
},
{
color: "green",
value: "#0f0"
},
{
color: "blue",
value: "#00f"
},
{
color: "cyan",
value: "#0ff"
},
{
color: "magenta",
value: "#f0f"
},
{
color: "yellow",
value: "#ff0"
},
{
color: "black",
value: "#000"
}
]