
Web Server e Web Applications
Prima del World Wide Web
Internet nasce nel 1983 a partire dalla rete ARPANet (una rete militare USA usata anche a fini di ricerca). Essa si basa su un insieme di protocolli di rete sviluppati a partire da uno standard internazionale chiamato “Modello OSI” che organizza la rete come un sistema a strati, dove gli strati inferiori forniscono connettività a basso livello (reti cablate, reti wifi, cellulari, satellitari, ecc.) agli strati superiori, che a loro volta forniscono servizi alle applicazioni software, come la posta, lo scambio files, lo streaming, i social, ecc. Questi protocolli nel mondo Internet vengono chiamati “stack TCP/IP” dal nome dei due più importanti.
Internet negli anni ’80 è una rete principalmente utilizzata in ambito accademico e scientifico e consente un insieme di servizi di informazione e comunicazione come Usenet, FTP, mail, Telnet, che consentono una comunicazione testuale e di scambio documenti che si globalizza raggiungendo i cinque continenti, pur essendo diffusa maggiormente in America settentrionale e in Europa, anche se resta principalmente una rete che collega università centri di ricerca e organizzazioni governative, fisicamente connesse con cavi dedicati e utilizzata da una minoranza di esperti qualificati per scambiare informazioni di tipo scientifico/economico/amministrativo.
Internet, nonostante la diffusione dei personal computer già negli anni 80, non raggiungeva le case e le persone a causa di due tipi di problemi: la mancanza di connessioni che raggiungessero le abitazioni e il fatto che non esistevano modi semplici per condividere informazioni e documenti.
Il primo problema venne inizialmente risolto con la diffusione del modem telefonico, un dispositivo che sfruttava la rete telefonica tradizionale per connettere due computer. I modem ebbero una enorme diffusione dalla fine degli anni 80, e divennero di massa negli anni 90, fino all’avvento di linee dedicate come l’ADSL e successivamente (anni 2000) la fibra ottica.
Riguardo al secondo problema già alla fine degli anni 80 era già sentita l’esigenza di sviluppare un qualche tipo di “sistema informativo globale” in grado di trasmettere notizie, scambiare conoscenza e cultura, condividere esperienze, ecc. attraverso strumenti digitali. Ad esempio in Italia già a fine anni 80 era diffuso un sistema chiamato Televideo, che consentiva attraverso la televisione di leggere notizie.
Mancava però una tecnologia che unisse la connessione casalinga ad un sistema informativo globale.
Il World Wide Web
Nel 1991 un informatico del CERN, Tim Berners Lee[1], concepisce una nuova tecnologia in grado di risolvere definitivamente il problema del sistema informativo. La sua idea era quella di usare un sistema di ipertesti, ovvero di documenti in grado di contenere collegamenti ad altri documenti, e che questi non fossero disponibili su un unico computer, ma che esistesse un sistema di server univocamente identificati nella rete tramite non indirizzi IP, ma veri e propri identificativi univoci.
Progettò quindi un nuovo protocollo, chiamato HTTP (Hypertext Transport Protocol), in grado di permettere uno scambio di richieste e risposte tra un client ed un server tramite documenti testuali. I server HTTP sono quindi server che mettono a disposizione ai client dei documenti di testo in un nuovo formato dati, HTML, un linguaggio di markup che permette di mostrare testi formattati contenenti immagini e collegamenti ad altre immagini, ognuna caratterizzata da un identificatore unico. Ogni documento ha un proprio identificatore unico, chiamato URL, che definisce univocamente una specifica pagina o risorsa, non solo nel server web, ma nell’intera rete Internet.
Lato client è previsto un programma, detto browser, dove L’utente deve solo digitare la URL, mentre il browser fa tutto il resto: richiede la decodifica della URL (ad un servizio chiamato DNS) in un indirizzo IP, avvia la chiamata HTTP, riceve la risposta HTML, trasforma l’HTML in testo formattato (render) e poi carica (sempre tramite URL e chiamate HTTP) i documenti collegati, come le immagini o altro ancora. La pagina che vediamo pronta per essere vista è in realtà frutto di molteplici chiamate al server (o a più server) per ottenere tutti gli elementi che la compongono (detti anche “asset”).
Nel modello concettuale di Berners Lee, il server è chiamato sito, la URL stessa viene chiamata “indirizzo“, e la schermata corrente viene chiamata “pagina“, e nella pagina oltre a testo ed immagini sono presenti opportuni collegamenti (detti “ancore” o “link“) per accedere, con un click e secondo il meccanismo dell’ipertesto[2], ad altre “pagine”, tramite caricamento da browser che riesegue tutta la procedura da capo caricando una nuova pagina HTML e i suoi allegati.
Siccome la URL è un riferimento globale ad una risorsa, essa può fare riferimento ad una pagina dello stesso sito (link interno) o su un altro host remoto (link esterno). Questo rende possibile collegare una pagina di un sito a pagine di altri siti, dove qualsiasi pagina può connettersi all’indirizzo di altre pagine come se fosse tutto parte di un unico sistema di informazione globale. L’idea di Tim Berners Lee era infatti quella di creare una “ragnatela” di siti collegati tra loro, da cui appunto il termine “World Wide Web” (la “ragnatela globale”) su cui si basa oggi quasi tutta la struttura informativa della rete Internet.
L’invenzione dl Tim Berners Lee apre le porte alla diffusione di massa di Internet, e quindi a veri investimenti infrastrutturali ed allo sviluppo dei modem, e poi delle reti fisse e mobili. Il Web infatti diventa sin dall’inizio luogo virtuale dove diffondere informazioni, notizie, siti istituzionali, approfondimenti, ma anche diventare vetrina per le attività commerciali e di comunicazione.
Siti dinamici e web application
Come visto, nella sua concezione iniziale il server web http è concepito come un software che accetta richieste HTTP, poi in base alla URL reperisce nel file system la risorsa richiesta (la pagina html), la carica e la restituisce nel body della risposta http. La pagina html è una pagina statica già preparata in anticipo e pronta per essere inviata. Sono previste le form nell’HTML che permettono all’utente di inviare alcune informazioni tramite modulo, ma queste vengono memorizzate in files sul server per essere poi elaborati da altri software esterni al server web in un secondo momento.
Qui viene mostrato il modello concettuale.
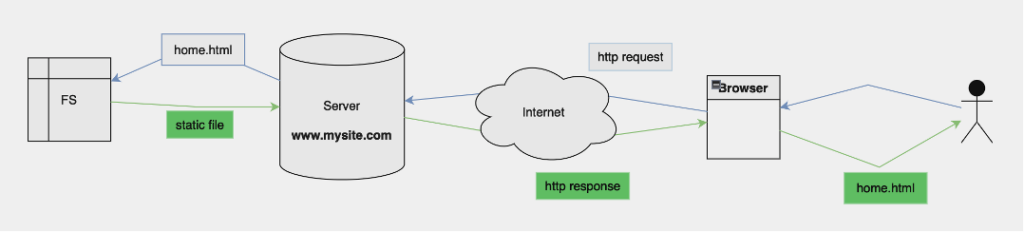
Questo modello di web viene chiamato “statico” perché non prevede una risposta dinamica sulla base di input utente. Le pagine ed i contenuti sono preparati in anticipo, e restano gli stessi e una limitata interattività, e non esiste alcuna sicurezza o riservatezza sui dati. Non era quindi possibile interagire, comunicare, caricare propri contenuti. Il web nella sua prima diffusione restava uno strumento di consultazione passiva, dove al massimo si potevano inviare informazioni non in tempo reale.
Intorno alla fine degli anni ’90 si cerca di risolvere questo problema con l’introduzione del concetto di sito web dinamico (noto col termine di marketing “web 2.0“). In questo modello il server web riceve la chiamata http, ma anzichè caricare una risorsa statica dal file system, passa la richiesta ad una web application che produce, al momento, una pagina html di risposta. La web application è una vera e propria applicazione, con un input ed un output gestiti in tempo reale, che elabora la richiesta e produce la risorsa richiesta dal web server al momento. Qui lo schema concettuale:
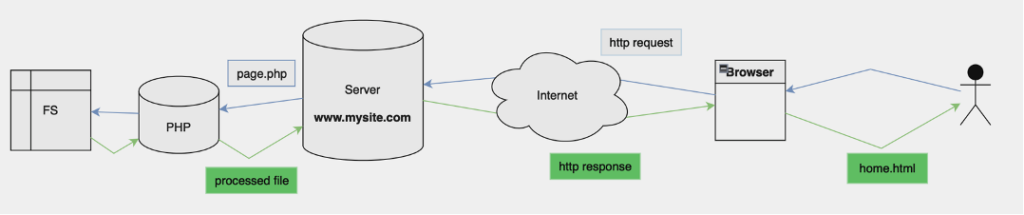
Per capire come funziona useremo il modello che fina da subito si è imposto, ovvero quello di PHP (“PHP: Hypertext Preprocessor”), che a lungo è stato ed è tuttora il principale sistema di gestione delle pagine dinamiche, poi replicato con JSP/Tomcat (Java), e ASP.NET (C#) ed altri linguaggi. In questo modello la pagina che si trova nel filesystem (che viene predisposta dal programmatore) è in un file sorgente che contiene codice misto PHP e HTML, detta “pagina PHP”.
Qui un esempio di pagina PHP:
Pagina PHP
<!DOCTYPE html>
<html>
<body>
<h1>My static title</h1>
<div>
<?php
$saluto="Hello world";
echo $saluto;
?>
</div>
</body>
</html>Questo codice viene elaborato da un interprete PHP che lato server genera una pagina HTML a partire dalle istruzioni PHP. La pagina che viene generata è quindi sempre in HTML e viene inviata tramite HTTP Response al browser.
Pagina HTML
<!DOCTYPE html>
<html>
<body>
<h1>My static title</h1>
<div>
Hello world
</div>
</body>
</html>Siccome si usa un linguaggio di programmazione ad alto livello (PHP è derivato dal linguaggio C) è ovviamente possibile scrivere applicazioni anche complesse che sono in grado di prelevare informazioni da database, altri servizi internet, filesystem, leggere le form in tempo reale, e quindi elaborare e gestire informazione e comunicazione. La applicazione server (application server) si ricorda segue un modello uno-a-molti, e quindi permette di gestire la comunicazione e la condivisione in tempo reale tra molti utenti, aprendo quindi enormi possibilità nella costruzione di un Internet condiviso.
Per il browser questo processo è del tutto trasparente: esso riceve infatti una pagina html e si comporta allo stesso identico modo che nel web statico, in effetti per il browser non è importante come viene generata la pagina web. Ma lato server cambia tutto, perché grazie alla programmazione di una Web Application “dietro” al Web Server diventa possibile:
– inserire contenuti dinamici: il linguaggio lato server può svolgere operazioni tipiche di un linguaggio ad alto livello, come accedere a risorse dati e predisporre pagine web collegate a questi dati. Pensiamo ad esempio ad un sito web che fornisce informazioni meteo, o ad un sito web che mostra dati di Borsa.
– creare interattività: è possibile analizzare le form ricevute e processarle, inviare informazioni in tempo reale, gestire agiornamenti, ecc.; L’utente può partecipare quindi a forum online, inviare testi ed immagini, condividere contenuti. E’ possibile quindi creare reti sociali.
– gestire sicurezza e sessioni: si possono inviare codici univoci al singolo client per garantire continuità tra più chiamate dello stesso utente, e quindi creare sessioni riservate e specifiche per il singolo utente (ad esempio posta elettronica o home banking).
Grazie al Web 2.0 la comunicazione diventa bidirezionale e molti a molti e rende possibile la possibilità per gli utenti a contribuire allo sviluppo dei contenuti su Internet, oltre a rendere possibili un grande numero di applicazioni, come i social network, gli ecommerce, la collaborazione professionale e non, la condivisione di scienza, cultura, svago, ecc. a livello globale tramite un accesso non controllato dall’alto, almeno in linea teorica. Il web dinamico è una delle più diffuse architetture, e pur avendo avuto nel tempo varie evoluzioni, che vedremo, rimane uno dei capisaldi della progettazione web odierna.
PHP in particolare è ancora oggi (nelle sue evoluzioni) il linguaggio di programmazione più diffuso del web, quello che ha dato vita al web moderno, coi social network (Facebook), gli ecommerce (Amazon ma anche la quasi totalità degli altri siti di ecommerce), i blog (WordPress), e i CMS (come Joomla o Drupal, prodotti che consentono a chiunque di creare un proprio sito dinamico), ed infine i siti di forum di discussione (VBullettin). Java e .NET sono invece più utilizzati dalle grandi aziende per offrire servizi web più legato a servizi aziendali, come le banche o le telecomunicazioni.
Vedremo nella prossima lezione, come a questo modello si affianca ed in alcuni casi viene sostituito, quelli dei Web Services.
[1] Il primo browser sperimentale, Mosaic, è in realtà del 1993, e il primo browser utente è Netscape Navigator, del 1994.
[2] Un ipertesto è un insieme di documenti collegati tra loro. Il collegamento avviene tramite opportune parole o frasi opportunamente marcate, che contengono il riferimento ad un’altra pagina. L’ipertesto è quindi un grafo (una struttura connessa di nodi) orientato (i collegamenti sono direzionali) ciclico (è possibile direttamente o indirettamente tornare alla pagina iniziale).
[3] Un grafo orientato ciclico è un grafo dove gli archi sono orientati, ed è eventualmente possibile tornare saltando da un nodo all’altro al nodo di partenza.