
Sistemi operativi concorrenti
Il paradigma sequenziale
Secondo il teorema di Böhm-Jacopini per poter realizzare qualsiasi algoritmo è sufficiente avere a disposizione una macchina con un set di istruzioni che comprenda soltanto operazioni sequenziali, aritmetico-logiche e di iterazione.
Nell’immagine un esempio di programma che riunisce in se tutte e tre le strutture.
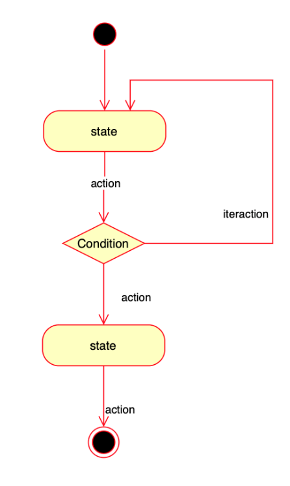
Questo modello di esecuzione viene chiamato “sequenziale” in quanto consiste in una lista di istruzioni che vengono impartite al computer in modalità sequenziale, ovvero una dietro l’altra (anche in caso di scelta, cambia solo l’ordine di esecuzione). Nella macchina di Von Neumann l’esecuzione di un programma consiste quindi nella realizzazione di un task tramite un processo che esegue una sequenza di istruzioni che sono elaborate dalla cpu. La sequenza di istruzioni da eseguire è chiamata coda di istruzioni.

Questo paradigma di programmazione è valido per molte applicazioni ancora oggi. Il programmatore scrive l’applicazione sapendo che verrà eseguito un flusso di istruzioni che userà una memoria logica dedicata (con stack ed heap) ed avrà il controllo delle periferiche di input ed output.
Il paradigma concorrente
Bohm-Jacopini fecero i loro studi negli anni 60. La macchina di Von Neumann è degli anni 40. Questi modelli si adattavano ad uno schema tradizionale, con una CPU, una memoria, ed un sistema operativo che eseguiva un solo programma alla volta.
Questo modello è stato messo in discussione a partire dagli anni 70.
Partiamo prima di tutto dal fatto che con l’invenzione del microprocessore e dei semiconduttori, l’informatica comincia ad avere uno sviluppo lato hardware sempre più veloce, al punto tale che Gordon Moore (fondatore di Intel) enunciò la famosa “legge di Moore”: la potenza di calcolo di un computer raddoppia ogni 18 mesi e quadruplica ogni 3 anni. Questa legge non ha una validità scientifica ma fu incredibilmente confermata per ben 40 anni di storia dell’informatica (dal 1970 al 2010 circa, oggi la curva ha ridotto la sua pendenza) col risultato che oggi i computer sono milioni di volte più veloci rispetto agli anni 70.
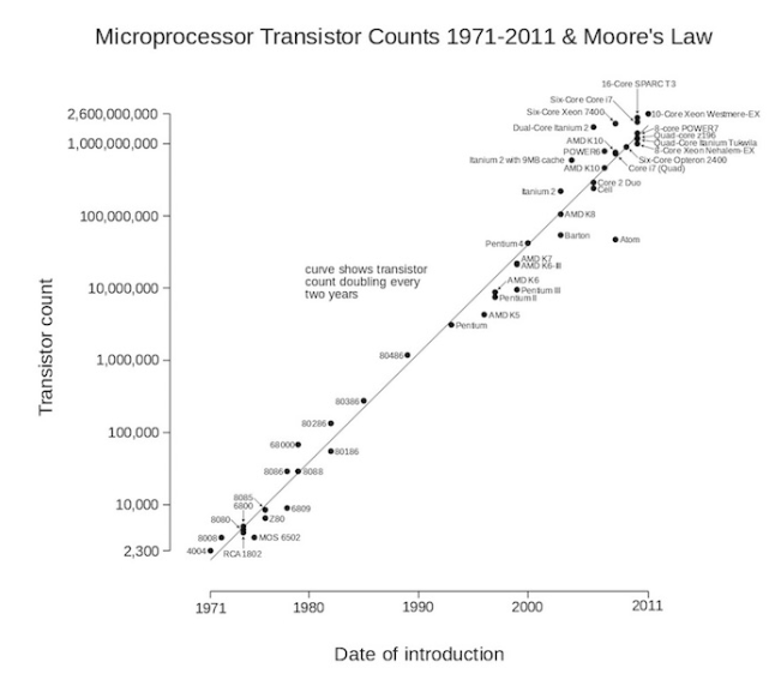
Di fronte a questo gigantesco incremento di potenza sono state rese via via possibili applicazioni pratiche impensabili all’epoca di Bohm-Jacopini:
- è diventato possibile sfruttare un singolo processore anziché per un solo programma ed utente alla volta per essere usato in modalità multiutente, sia localmente, sia – con lo sviluppo di Internet – da remoto, con più utenti in grado di richiedere servizi e attività da una singola macchina, nello stesso momento.
- sono state rese possibili interfacce grafiche visuali dove un utente su un singolo computer può visualizzare in finestra diverse applicazioni contemporaneamente e quindi svolgere più azioni in contemporanea.
Questo è stato reso possibile proprio grazie al fatto che processori sempre più potenti non solo permettevano applicazioni più complesse (es. multimediali, grafiche, connesse ad internet, ecc.) ma che con un solo processo/utente alla volta si sprecava gran parte del tempo di CPU.
Un programma interattivo eseguito sequenzialmente usa in modo poco efficiente le risorse della cpu, perché questa, rimanendo in attesa delle azioni dell’utente, rimane inutilizzata la maggior parte del tempo. Con un sistema operativo invece in grado di coordinare più processi allo stesso tempo, è invece possibile far eseguire in contemporanea più applicazioni, sfruttando quindi cpu memoria e le altre risorse in modo più efficiente ed efficace.
I sistemi operativi moderni (a partire dai primi anni 70) hanno quindi introdotto un sistema di gestione delle applicazioni in esecuzione che rende possibile la loro esecuzione in contemporanea nella stessa macchina, in attività indipendenti e contemporaneee.
Le applicazioni in un normale pc desktop sono la forma più immediatamente riconoscibile di questo paradigma concorrente. Esse svolgono task indipendenti (ad esempio word processor, foglio di calcolo, navigazione internet) anche se in contemporanea. Esse sono scritte ancora come se avessero il pieno controllo del computer, ed è il sistema operativo a gestire la concorrenza, ovvero lo sfruttamento delle risorse. Lo stesso si può dire anche su tutti i dispositivi introdotti successivamente, come gli smartphone ed i table, dove -in linea generale- si ha una app in primo piano e le altre sono sospese in attesa di essere richiamate (ma possono comunque svolgere alcuni task, come per esempio accettare notifiche, aggiornarsi, salvare la posizione GPS, ecc.). Vedremo in processi e risorse come questo avviene in dettaglio, ma il principio di funzionamento di queste applicazioni consiste nel suddividere il tempo di cpu in unità di tempo, dette quanti, e concedere questi quanti, a turno, alle applicazioni. La velocità dei processori è tali da creare l’illusione, per l’utente, che le applicazioni funzionino in contemporanea, ma in realtà c’è sempre una coda di esecuzione. Come detto vedremo questo meccanismo in dettaglio.
In conclusione il paradigma concorrente si basa sull’esistenza di tanti processi sequenziali che agiscono in un regime, coordinati da un sistema operativo concorrente.
Il paradigma parallelo
Con l’introduzione dei sistemi multiprocessore, dove cioè sono presenti più cpu, ha reso possibile rendere ancora più efficienti i sistemi concorrenti, in quanto più processori in contemporanea permette di combinare sia il frazionamento per quanti di tempo, sia l’esecuzione contemporanea su più processori di processi differenti, migliorando enormemente le prestazioni dei computer.
Ma i processori paralleli hanno permesso anche di migliorare le prestazioni delle singole applicazioni, finora scritte seguendo il paradigma sequenziale (una sola coda di istruzioni).
Col paradigma parallelo il programmatore scrive quindi il programma spezzando le attività finora scritte in sequenza in più sotto-attività parallele che sono eseguite in modo indipendente e contemporaneo ed i cui risultati possono essere combinati al termine. Proviamo a capirlo con un esempio, come la ricerca di una determinata parola chiave in un testo. Nel paradigma sequenziale eseguiamo un ciclo su tutte le parole del testo, impiegando un tempo proporzionale alla lunghezza del testo stesso. Abbiamo una sola cpu a disposizione, e il tempo di esecuzione di questo task dipende solo dalla potenza della cpu e del tempo messo a disposizione dal sistema operativo (in concorrenza con gli altri task). In termini tecnici questa esecuzione di istruzioni sequenziale si basa sul concetto di thread (“filo”), che rappresenta la coda di istruzioni da eseguire nel processo.
Tuttavia, se abbiamo due processori, possiamo riscrivere il programma per sfruttarli: in questo caso creiamo due thread sequenziali attivi in contemporanea, entrambi che svolgono lo stesso identico algoritmo, ma con la differenza che al primo thread assegnamo la prima metà del testo, ed al secondo la seconda metà. Ognuno dei due thread si occupa della ricerca in metà del testo, dimezzando virtualmente il tempo di ricerca. Al termine della ricerca i due task si ricongiungeranno (“join”) e uniranno i propri risultati.
Col parallelismo abbiamo una esecuzione parallela, non concorrente, infatti i due task collaborano e sono consapevoli dell’esistenza di un thread (o più di uno) contemporaneo, con cui possono condividere dati, ed anche scambiarli, se necessario. Ovviamente tutto questo ha senso solo se ci sono più processori che effettivamente possono operare in contemporanea.
La ricerca sui motori di ricerca sfrutta il parallelismo su una scala notevolmente maggiore, dove sono impegnati cluster di migliaia di computer, che eseguono la ricerca della parola chiave su migliaia di dataset diversi in contemporanea. Qui un esempio visuale:
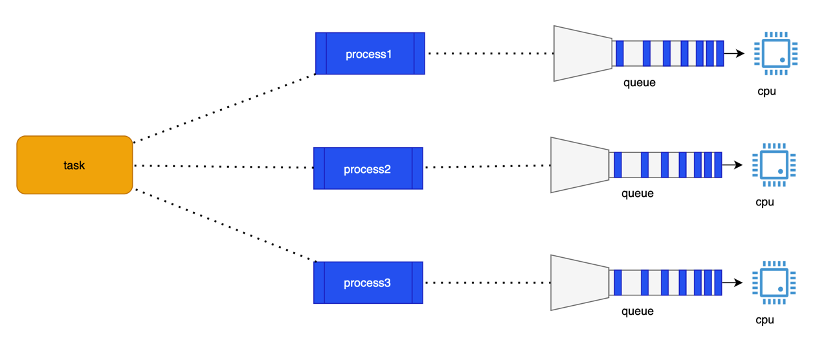
E’ oggi tecnicamente impossibile ottenere lo stesso risultato con sistemi monocore. Per un insieme di limiti tecnici, i processori monocore all’inizio degli anni 2000 avevano raggiunto il massimo grado di sviluppo, e per ottenere un incremento di prestazioni si è reso necessario realizzare processori con più core. Quindi il parallelismo oggi non è una scelta, ma l’unica strada percorribile per sfruttare la potenza di calcolo dei sistemi multi-core. Quindi la programmazione parallela deve essere parte del bagaglio tecnico di qualsiasi programmatore.
Come si può notare paradigma parallelo e concorrente sono presenti in contemporanea, ma non sono la stessa cosa. Col parallelismo il task è unico e spezzato in più sottotask contemporanei e reciprocamente consapevoli, con la concorrenza invece i task sono molteplici, indipendenti e inconsapevoli del resto.
Tuttavia in entrambi i casi si parla di contemporaneità di esecuzione.
Proviamo a fare quindi un riepilogo di quanto visto finora.
1) i processi sia paralleli che concorrenti possono concorrere nell’accesso alle medesime risorse (cpu-memoria-periferiche) e quindi si può assistere a condizioni in cui due o più task cercando di leggere o scrivere su risorse condivise. Questo tema si può riassumere nella necessità di introdurre tecniche per limitare lo spreco di risorse, o blocchi, al fine di evitare che si vanifichino i vantaggi della parallelizzazione. Tuttavia in ogni caso bisogna tenere conto del fatto che non si può avere nè concorrenza nè parallelismo “perfetto” in un contesto di risorse esclusive (si pensi ad un computer con una sola tastiera ed un monitor).
2) L’esecuzione contemporanea di più task introduce una lentezza dovuta al costo dello switch di contesto tra un processo e l’altro: durante lo switch di contesto il controllo passa al sistema operativo che deve decidere il prossimo task da eseguire, verificare e soddisfare eventuali richieste di risorse, aggiornare la coda dei processi. Questo switch di contesto interessa tutti i casi di programmazione concorrente e parallela. Anche questo elemento va a limitare la parallelizzazione e la concorrenza.
3) Occorre tenere conto che anche in un software parallelo non tutte le operazioni sono frazionabili in più attività contemporanee. In un sistema informatico vi sono risorse non parallelizzabili (anche quando non sono in mutua esclusione). Ad esempio l’accesso ad un filesystem in lettura può essere condiviso da più processi concorrenti ed eventualmente anche paralleli ma l’accesso alla risorsa resta sequenziale.