
Programmazione parallela in C++
Parallelizzare i task
L’attività di parallelizzazione, come si è visto, consiste nel dividere il flusso del programma in più sottoflussi o task per i quali il sistema operativo garantisce una esecuzione parallela a livello hardware. Non è il programmatore a garantire il parallelismo ma per farlo sfrutta il sistema operativo, che rende effettivo il parallelismo attivando i processori paralleli (o le macchine parallele) se sono disponibili.
In assenza di risorse disponibili per la parallelizzazione, il software sarà eseguito in modo sequenziale rendendo nulli i vantaggi della parallelizzazione, ed anzi rallentando l’esecuzione dell’applicazione stessa perchè l’attività di creazione e gestione di task paralleli richiede comunque tempo di calcolo. L’applicazione comunque funzionerà correttamente anche su sistemi monoprocessore.
A livello tecnico la parallelizzazione consiste nell’eseguire una suddivisione dell’attività mediante la creazione, all’interno della stessa applicazione di uno o più sottoflussi a cui assegnare dei task specifici.
Graficamente questa azione si può rappresentare nel seguente modo:
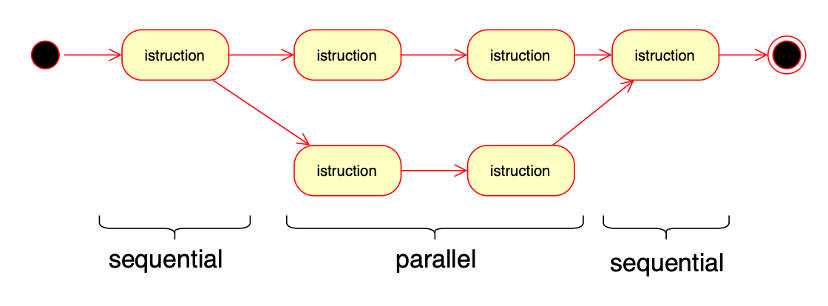
A un certo punto del flusso di esecuzione avviene una “biforcazione” che genera una attività “figlia”, che svolge una attività parallela. Quando questa termina rimane in esecuzione una sola attività. E’ possibile chiaramente prevedere più biforcazioni rendendo possibile quindi avviare molte attività parallele.
Sono previste, nei moderni sistemi operativi, due tecniche per svolgere queste biforcazioni: mediante l’uso dei processi (multiprocessing) o l’uso dei thread (multithreading).
Multiprocessing
Nel multiprocessing viene generato per ogni nuova attività un processo figlio, con quindi un PCB dedicato e memoria logica dedicata. Nei sistemi operativi a standard POSIX (Unix, Linux, ultime versioni di Windows, MacOs, iOs, Android) il processo di generazione viene chiamato fork. La fork esegue una chiamata al sistema operativo, che crea un nuovo PCB e clona lo stato di processo attuale (codice, heap, stack, stato, ecc.).
Questo significa che la istruzione successiva alla fork verrà eseguita da due processi, in quanto si tratta della stessa applicazione in esecuzione su due processi distinti. Ciascun processo avrà ovviamente un PID differente e da questo elemento si potrà differire.
Vediamo un esempio:
#include <unistd.h>
#include <iostream>
using namespace std;
int main() {
int pid = fork();
cout << pid << endl;
return 0;
}Se eseguito questo codice stamperà due volte il PID sulla schermata, con due codici diversi (l’istruzione getpid restituisce il PID del processo corrente).
Come si vede dal codice fork restituisce un id. Questo id ha un valore differente a seconda del processo
– nel processo padre esso avrà il valore del PID del processo figlio;
– nel processo figlio esso avrà valore 0.
#include <iostream>
#include <unistd.h>
#include <sys/wait.h>
using namespace std;
int main() {
int pid = fork();
if (pid != 0) {
print("This is father process");
} else {
print("This is son process");
}Con questo sistema il programmatore è in grado di distinguere tra i due processi ed eseguire quindi l’opportuna programmazione parallela.
Affinchè la programmazione parallela possa terminare correttamente, è necessario che un processo (in genere il processo padre, ma non è obbligatorio) attenda il termine dell’esecuzione dei processi figli. In C++ questo compito è svolto dall’istruzione wait, che senza parametri può attendere tutti i processi figli, oppure uno con specifico id.
#include <iostream>
#include <unistd.h>
#include <sys/wait.h>
using namespace std;
int main() {
int id = fork();
if (pid != 0) {
print("This is father process");
wait(NULL);
print("Child terminated");
} else {
print("This is son process");
}Come si vede il processo padre si mette in attesa che il figlio finisca di essere eseguito, poi va avanti con la sua attività.
Si ricorda che nella programmazione parallela:
– l’ordine di esecuzione dei processi è deciso dal sistema operativo, non è sotto il controllo del programmatore.
– la creazione di un processo è una operazione molto costosa in un sistema operativo, sia in termini di tempo che di spazio, perchè si clona tutta la memoria del processo, il processo figlio in pratica all’inizio della sua esecuzione è del tutto identico al padre.
Per comunicare tra loro e quindi collaborare i processi possono utilizzare differenti tecniche, ma le due principali sono le pipes e le socket. Le prime sono una funzione messa a disposizione dal sistema operativo e che consiste in un canale di comunicazione monodirezionale. Le seconde sono parte dello standard ISO-OSI e sono bidirezionali (si usano anche nella comunicazione di rete).
Multithreading
Il forking è un meccanismo utilizzato principalmente nelle applicazioni che lavorano in sistemi monoprocessore per creare applicazioni figlie che svolgono in genere attività quasi del tutto indipendenti. Sono il sistema tradizionale del mondo Unix realizzare parallelismo, ma ormai questo sistema è stato quasi soppiantato dal multithreading, che richiede meno risorse e “forza” il sistema operativo ad eseguire i thread su cpu differenti.
Il thread è come sappiamo una “coda di esecuzione” ovvero sequenza di istruzioni che vengono messe in esecuzione all’interno di un determinato processo. Nei sistemi operativi moderni (post 2000) ogni processo può eseguire più thread contemporanei sullo stesso codice. A differenza dei processi paralleli però i thread condividono la stessa memoria delle istruzioni e lo stesso Heap, quindi tutti i thread hanno accesso alle stesse risorse.
Quel che cambia è che ogni thread esegue una funzione indipendente, con un suo stack dedicato, quindi con variabili locali indipendenti.
Un thread viene creato assegnandoli direttamente la funzione che deve svolgere (o una istanza di classe in linguaggi come Java o C#). Vediamo un esempio in C++:
#include <iostream>
#include <thread>
void print(int n) {
cout << n << endl;
}
int main() {
thread threads[10];
for (int i=0; i<10; i++) {
threads[i] = thread(print, i);
}
for (int i=0; i<10; i++) {
threads[i].join();
}
return 0;
}thread è quindi sia un tipo di oggetto sia la funzione che lo crea.
Nel multithreading è sempre previsto che ci sia una thread principale (detto main thread) che crea dei thread secondari. Il thread principale per evitare che termini (e con esso l’intero programma) può essere messo in attesa tramite l’istruzione join. Occorre fare attenzione: è necessario eseguire join per OGNI thread creato ed eseguito.
I thread hanno due indiscutibili vantaggi sui processi: la loro attivazione richiede una frazione delle risorse di un processo, ed inoltre la memoria utilizzata è condivisa, quindi non sono necessari complessi meccanismi di comunicazione tra processi. E’ sufficiente utilizzare variabili globali o staticamente allocate per condividere informazioni.
C’è però uno svantaggio: il controllo sull’accesso alle risorse condivise deve essere gestito dal programmatore, tenendo quindi conto delle condizioni di Bernstein.
Vedremo nella prossima dispensa che questo problema lo si risolve coi mutex e coi semafori.