
Problemi di sincronizzazione
In questa dispensa andiamo ad analizzare tre noti problemi di sincronizzazione, e la loro risoluzione.
Produttore consumatore
Il sistema dei semafori è fondamentale per sincronizzare thread che lavorano insieme sugli stessi dati. In particolare andiamo ad approfondire uno scenario molto comune, quello in cui alcuni thread producono dei dati che inseriscono in un buffer condiviso, ed altri che invece consumano questi dati, nello stesso tempo. Questo problema, detto del “produttore-consumatore”, consiste nel fatto che occorre che i produttori possono produrre nuovi dati solo se c’è spazio nel buffer, e viceversa i consumatori possono consumare i dati nel buffer solo se ci sono dati presenti.
Partiamo con un solo produttore ed un solo consumatore. Un esempio può essere un sistema di gestione ordini, dove un produttore (il cliente dell’ordine) inserisce un ordine nel buffer, e il consumatore (cioè il gestore ordini) lo evade, eliminandolo dal buffer. Dobbiamo fare in modo che il cliente, cioè il produttore, possa effettuare ordini solo se ci sono slot liberi, ed il gestore, cioè il consumatore, si attivi per evaderli solo se ci sono ordini.
L’obiettivo è fare in modo che se il buffer è pieno, il produttore viene messo in attesa, invece se il buffer è vuoto il consumatore viene messo in attesa.
Sono necessari due semafori: uno per gestire quanti slot liberi rimangono, ed uno per gestire quanti slot occupati rimangono. Non è possibile infatti usare un solo semaforo, perché dobbiamo tenere conto del fatto che dal punto di vista del produttore, gli slot liberi non sono quelli “non occupati”, ma bisogna tenere conto del fatto che mentre un consumatore “consuma” uno slot questo slot non è nè occupato nè libero, e lo stesso vale per il consumatore. La produzione (ed il consumo) dei dati per uno slot infatti non sono attività istantanee.
Il produttore, prima di inserire un nuovo elemento, diminuirà di uno il semaforo dei liberi. Se c’è almeno uno slot libero, potrà scrivere impiegandoci un certo tempo: quando avrà finito, aumenterà di uno il semaforo dei pieni.
Il consumatore, prima di leggere un nuovo elemento, diminuirà di uno il semaforo dei pieni. Se c’è almeno uno slot pieno, potrà leggere, operazione neanche questa immediata: quando avrà finito, aumenterà di uno il semaforo dei liberi.
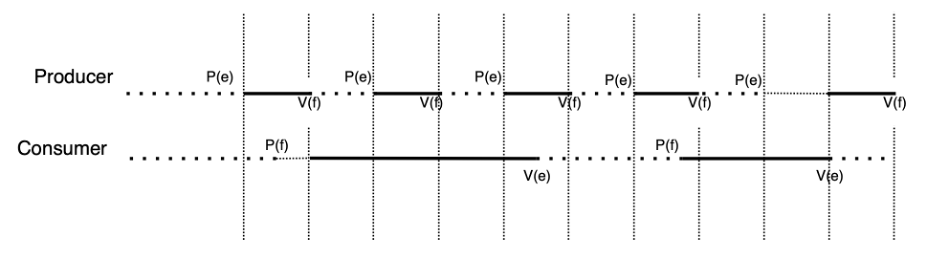
Come si vede:
– i due attori usano P per diminuire il semaforo di propria competenza, e V per aumentare il semaforo dell’altro.
– quando il buffer è pieno infatti i liberi sono a 0, il produttore si deve fermare ed attendere che il consumatore cominci a svuotarlo;
– quando il buffer è vuoto i pieni sono a 0, ed il consumatore si deve fermare ed attendere che il produttore cominci a riempirlo.
Vediamo il codice (simuliamo il tempo di produzione e consumo con la funzione sleep).
int full = 0;
int empty = MAX;
int read_cursor = 0;
int write_cursor = 0;
int *buffer;
void producer() {
while (1) {
p(&empty);
buffer[write_cursor] = rand() % 100;
cout << "produced: " << buffer[write_cursor] << endl;
write_cursor = (write_cursor + 1) % MAX;
print();
v(&full);
sleep(2);
}
}
void consumer() {
while (1) {
p(&full);
cout << "consumed: " << buffer[read_cursor] << endl;
buffer[read_cursor] = 0;
read_cursor = (read_cursor + 1) % MAX;
print();
v(&empty);
sleep(rand() % 5 + 1);
}
}(i tempi di sleep sono diversi per avere un comportamento più realistico dei due thread).
| Produttore | Consumatore |
| – il produttore per prima cosa richiede se ci sono caselle libere (empty): se ci sono produce una risorsa e la inserisce nel buffer alla posizione write_cursor; – si noti che il buffer è circolare: una volta occupata la posizione più a destra, write_cursor si posiziona alla posizione 0 (operatore modulo); – una volta terminata la scrittura, incrementa di uno il semaforo delle piene (full) in modo da attivare eventuali consumatori in attesa. | – il consumatore per prima cosa richiede se ci sono caselle piene (full): se ci sono consuma la risorsa presente usando la posizione read_cursor; – read_cursor è circolare ed indipendente da write_cursor; – una volta terminata la lettura viene aggiornato il cursore e viene incrementato il semaforo delle caselle vuote (empty), in modo da attivare eventuali produttori in attesa. |
Grazie a questo sistema produttore e consumatore si sincronizzano, rimanendo in attesa di risorse senza fermarsi.
Qui graficamente:
Ma cosa succede se ci sono tanti produttori e consumatori? In questo caso non si ha solo un problema di sincronizzazione nel tempo, ma ci può essere un problema di competizione sulla risorsa del buffer. Ad esempio due produttori potrebbero contemporaneamente entrare nella sezione critica ma condividendo la risorsa write_cursor potrebbero scrivere sulla stessa casella del buffer, e poi modificare in modo inaspettato anche write_cursor. La stessa cosa il consumatore. In pratica serve un mutex aggiuntivo.
void producer() {
while (1) {
p(&empty);
p(&mutex_p);
buffer[write_cursor] = rand() % 100;
cout << "produced: " << buffer[write_cursor] << endl;
write_cursor = (write_cursor + 1) % MAX;
v(&mutex_p);
print();
v(&full);
sleep(2);
}
}
void consumer() {
while (1) {
p(&full);
p(&mutex_c);
cout << "consumed: " << buffer[read_cursor] << endl;
buffer[read_cursor] = 0;
read_cursor = (read_cursor + 1) % MAX;
v(&mutex_c);
print();
v(&empty);
sleep(rand() % 5 + 1);
}
}| Produttore | Consumatore |
| – il produttore per prima cosa richiede se ci sono caselle libere (empty); – una volta che ci sono caselle libere, richiede l’accesso esclusivo al cursore; – produce una risorsa e la inserisce nel buffer alla posizione write_cursor;- una volta terminata la scrittura, rilascia il mutex uscendo dalla sezione critica esclusiva; – infine incrementa di uno il semaforo delle piene (full) in modo da attivare eventuali consumatori in attesa. | – il consumatore per prima cosa richiede se ci sono caselle occupate (full); – una volta che ci sono caselle occupate, richiede l’accesso esclusivo al buffer ed al cursore; – consuma la risorsa e modifica il read_cursor; – una volta terminata la lettura, rilascia il mutex; – infine viene incrementato il semaforo delle caselle vuote (empty), in modo da attivare eventuali produttori in attesa. |
Un esempio di questo scenario è quello del McDonald’s. I produttori sono i clienti che producono ordini per la cucina, i consumatori sono gli addetti del fast food che consumano ovvero leggono gli ordini.
Il semaforo empty richiede se c’è un totem libero. Il semaforo full attiva un eventuale addetto libero.
Lettore e scrittore
Prendiamo ora un caso in cui la stessa risorsa è condivisa tra più scrittori e lettori, ad esempio una variabile intera scalare.
Il problema del lettore scrittore va pensato come il problema delle “strisce pedonali”.
Lo scrittore è l’automobile: mentre impegna le strisce i pedoni attendono prima di attraversare.
Il lettore sono i pedoni: mentre impegnano le strisce l’automobile attende.
Tuttavia se un nuovo pedone comincia l’attraversamento prima che l’ultimo pedone abbia finito, allora l’auto deve rimanere in attesa.
La sezione critica sarà quindi occupata da un solo scrittore oppure da molti lettori in contemporanea.
Vediamo i due scenari che possono accadere.
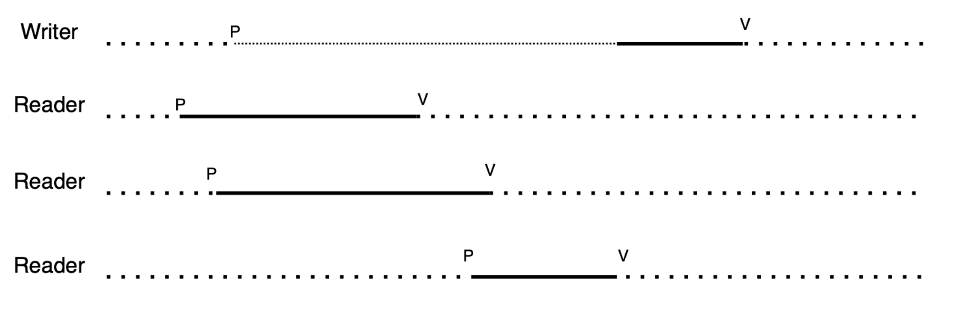
1) lo scrittore richiede la risorsa per scrivere: se non ci sono lettori attivi, lo scrittore scrive, altrimenti attende. E’ quindi sufficiente un mutex di scrittura.
2) un lettore richiede la risorsa per leggere, usando lo stesso mutex. Tuttavia se arriva un secondo lettore questo NON PRENDE il mutex, perchè è già stato preso. E così via altri lettori. E’ necessario però contare il numero di lettori nella sezione critica: ogni volta che entra un lettore il numero aumenta di 1, quando esce un lettore, diminuisce di 1. Quando l’ultimo lettore esce allora il contatore dei lettori va a 0, ed allora uscendo rilascia il mutex di scrittura.
Bisogna ricordarsi che anche la variabile che memorizza il numero dei lettori va protetta da un mutex, in quanto è condivisa tra i lettori.
I mutex sono quindi 2: quello di scrittura, e quello relativo al numero di lettori.
Vediamo il codice:
int semaphore_write = 1;
int semaphore_count_readers = 1;
int MAX = 3;
int shared_variable;
int count_readers = 0;
void writer() {
while (1) {
p(&semaphore_write);
shared_variable = rand()%100+1;
v(&semaphore_write);
}
}
void reader(int n) {
while(1) {
p(&semaphore_count_readers);
count_readers++;
v(&semaphore_count_readers);
if (count_readers == 1) {
p(&semaphore_write);
}
cout << shared_variable;
p(&semaphore_count_readers);
count_readers--;
v(&semaphore_count_readers);
if (count_readers == 0) {
v(&semaphore_write);
}
}
}Qui un esempio funzionante: https://replit.com/@CRISTIANNOBILI1/LettoriScrittori#main.cpp
Nell’esempio sono stati aggiunti gli sleep
| Scrittore | Lettore |
| – prende il semaforo P legato alla risorsa; – scrive; – rilascia il semaforo V legato alla risorsa | – esegue P sul semaforo legato al numero di lettori; – aumenta di 1 il numero di lettori; – esegue V sul semaforo legato al numero dei lettori; – se il numero di lettori è 1 è il primo lettore e quindi esegue P sul semaforo di scrittura; – legge il dato condiviso; – esegue di nuovo P sul semaforo legato al numero di lettori; – diminuisce il 1 il numero di lettori;- esegue V sul semaforo legato al numero dei lettori. – se il numero di lettori è 0 è l’ultimo lettore e quindi esegue V sul semaforo di scrittura |
Qui graficamente.
Il problema del lettore scrittore è legato a quegli scenari in cui l’oggetto da scrivere richiede del tempo per essere scritto ed è fondamentale che non ci sia nessun overlapping durante la scrittura. Quando lo scrittore effettua la modifica deve essere certo che nessun lettore stia leggendo i dati che scrive, perché potrebbero essere in uno stato non consistente (cioè non coerente). Per la stessa ragione, mentre un lettore legge, lo scrittore deve attendere il completamento della lettura onde evitare di compromettere i dati letti.
Un scenario reale è ad esempio quello dell’esecuzione di un aggiornamento delle disponibilità di magazzino per un ordine di un ecommerce. Finchè lo scrittore non aggiorna tutte le informazioni, i lettori non possono leggere i nuovi dati. Finchè i lettori leggono i vecchi dati, lo scrittore non li può aggiornare.
Lo stesso discorso vale per l’aggiornamento della disponibilità di un conto corrente quando è stato effettuato un bonifico. O l’aggiornamento del mercato azionario. O la propagazione di una informazione all’interno di una rete.
Filosofi a cena
Ci sono 5 filosofi cinesi seduti a una tavola rotonda. Ognuno ha davanti a se un piatto e tra ogni piatto c’è una bacchetta. Ogni bacchetta è condivisa tra due filosofi. Ogni filosofo può fare due cose: pensare (è un filosofo!) oppure mangiare. Ma per poter mangiare ogni filosofo ha bisogno di prendere prima la bacchetta a destra, poi quella a sinistra, e dopo aver mangiato ripetere l’operazione al contrario. Le bacchette però sono condivise con il filosofo rispettivamente a destra e a sinistra, quindi mangia un filosofo, quelli alla sua destra ed alla sua sinistra non possono mangiare.
Questa immagine rende l’idea.
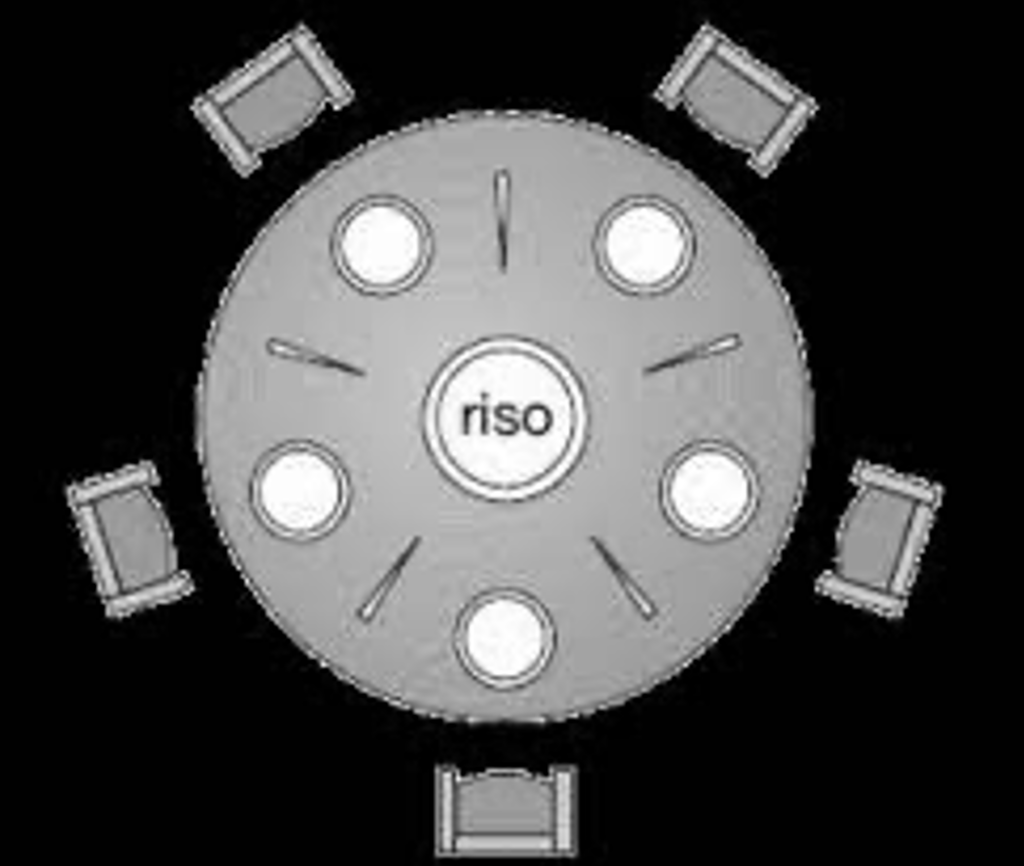
Il problema è dato dal fatto che se tutti i filosofi prendono più o meno contemporaneamente la bacchetta alla propria destra, rimangono tutti in attesa della bacchetta alla propria sinistra, col risultato che nessuno mangia.
E’ un problema di deadlock, cioè di dipendenza da una risorsa esclusiva che però è bloccata in modo circolare.
In termini informatici, abbiamo 5 thread e 5 risorse, ognuna associata ad un semaforo.
Vediamo il codice.
int chopsticks[5] = {1,1,1,1,1};
void philosopher(int i) {
while (1) {
cout << i << ": thinking" << endl;
p(&chopsticks[i]);
p(&chopsticks[(i + 1) % 5]);
cout << i << ": eating" << endl;
v(&chopsticks[i]);
v(&chopsticks[(i + 1) % 5]);
}
}In pratica il filosofo quando desidera mangiare si mette in attesa della bacchetta a destra, ed una volta presa, di quella a sinistra (si ricorda che è un array gestito in modo circolare quindi si usa l’operatore modulo).
Come ovviare a questo problema?
Ci sono diverse soluzioni, ma la più semplice è quella di ridurre il numero di filosofi che possono prendere le bacchette ad un massimo di 4 (con un semaforo numerico). E’ infatti evidente che con 4 soli filosofi che cercano di mangiare, il quinto non potrà mai prendere la bacchetta alla sua sinistra e quindi il filosofo alla sua sinistra potrà prendere anche la bacchetta alla sua destra, mangiare e rilasciare due bacchette, sbloccando a sua volta un altro filosofo e così via: si mangia più lentamente, ma tutti mangiano.
int chopsticks[5] = {1,1,1,1,1};
int sem_eating = 4;
void philosopher(int i) {
while (1) {
cout << i << ": thinking" << endl;
p(&sem_eating);
p(&chopsticks[i]);
p(&chopsticks[(i + 1) % 5]);
v(&sem_eating);
v(&chopsticks[i]);
v(&chopsticks[(i + 1) % 5]);
}
}Gli scenari reali corrispondenti a questo problema sono quelli in cui per gestire una elaborazione è necessario dover utilizzare risorse fra loro indipendenti, presenti però in numero inferiore rispetto ai thread in esecuzione, col rischio quindi di avere dipendenze circolari.