
Introduzione alla programmazione parallela
Nella programmazione parallela, come già visto, si suddivide un task in sottotask che vengono eseguiti in parallelo e svolgono ciascuno una attività che concorre al completamento del task complessivo.
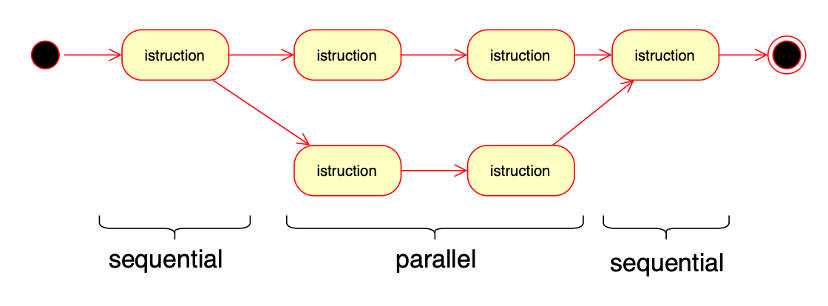
Vi sono molteplici algoritmi per gestire la migliore strategia di parallelizzazione, ma possiamo individuare due strategie principali per gestire la suddivisione del task: la domain decomposition e la functional decomposition.
Domain decomposition
In questo tipo di suddivisione, i dati associati al task vengono partizionati. Ogni task parallelo quindi poi lavora su una porzione dei dati, generalmente in modo simmetrico (la stessa quantità di dati).
L’algoritmo è quindi composto da tre fasi:
- Decomposizione del data set in modo opportuno
- Esecuzione di task paralleli sulle partizioni
- Ricomposizione dei risultati dei task paralleli, tramite comunicazione/condivisione dei risultati tra task.
La parola “dominio” intende il modello dati da elaborare.
Alcuni esempi di decomposizione di dominio:
- Mapping di un vettore (ogni elemento del vettore viene trasformato);
- Ricerca in un insieme;
- Reducing di un vettore o data set (si calcola un risultato scalare frutto di una operazione che comprende ogni elemento del vettore, es. la somma);
- Filtering;
- Alcune tipologie di ordinamento ricorsivo (quicksort-mergesort) con opportuni accorgimenti nel set iniziale.
- Manipolazione di immagini (di fatto è quasi sempre una composizione di mapping e/o reducing)
Non sono problemi partizionabili quelli in cui la suddivisione del data set non porta a lavorazioni indipendenti, ad esempio la generazione di numeri primi, serie di Fibonacci, divisioni, ecc.
Functional decomposition
Con questo approccio, l’attenzione è posta sugli algoritmi di calcolo più che sui dati. Il lavoro viene suddiviso sulla base dei task da fare. In pratica nella decomposizione funzionale i task paralleli non svolgono la stessa attività su dataset differenti, ma svolgono differenti attività su dataset che possono anche coincidere.
In questo caso i task non solo sono paralleli ma anche fortemente collaborativi: nei casi in cui il dataset coincide, sono necessarie tecniche per permettere la sincronizzazione, l’accesso protetto ad una risorsa, e garantire che non ci siano casi di starvation, ovvero di task che non riescono mai ad accedere alle risorse condivise. Nella decomposizione funzionale comunque il dataset può essere diviso anche in parti indipendenti, in quanto la decomposizione funzionale è intesa come una differente (ma pur sempre contemporanea) lavorazione di parti differenti.
Esempi di decomposizione funzionale:
- Web e application server;
- applicazioni basate sul modello muticlient-monoserver;
- tutti i modelli di applicazioni suddivise in microservizi;
- Task di Database;
- Task del tipo elaborazione in serie: uno o più task producono informazione, che viene a sua volta elaborata, in pipeline, da altri task;
- Videogiochi: in questo caso le parti differenti sono legate a funzioni differenti (si pensi ad un videogioco dove ciascuno degli sprite viene gestito in modo indipendente, es. giocatori di una partita di calcio, auto avversarie in un gioco di corsa, ecc.)
Problemi relativi all’elaborazione parallela
Nella programmazione di una applicazione parallela è necessario tenere conto, qualsiasi sia l’asse di decomposizione, delle problematiche progettuali che occorre affrontare, che si possono suddividere in due aree: le problematiche relative al tempo, e quelle relative ai dati.
Le prime sono legate ad una mancata sincronizzazione tra i task. Questi infatti sono eseguiti su uno o più processori distinti e quindi non è mai garantita l’esecuzione in modo deterministico, in altre parole il programmatore non ha modo di decidere – a priori – di eseguire un thread prima di un altro. Ad esempio un task potrebbe tentare di consumare una risorsa non ancora prodotta da un altro che è in ritardo, oppure un task potrebbe produrre una risorsa che ormai è obsoleta e quindi non utile.
Le problematiche relative ai dati partono invece dalle risorse condivise, che possono essere oggetto di scenari dove due processi cercano di scrivere la stessa risorsa (competizione), sia di scenari dove un processo cerca di scrivere e l’altro di leggere (cooperazione).
Per capirlo ripartiamo dalla esecuzione sequenziale: i task vengono eseguiti uno dietro l’altro, in coda, e non possono avvenire nè problematiche di tempo nè di dati, in quanto solo una istruzione di un solo thread ha accesso a tutte le risorse non condivise.

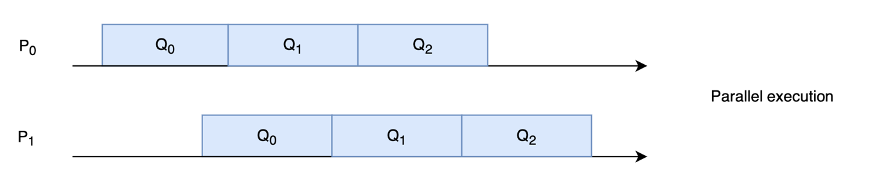
In un ambiente di esecuzione concorrente (più processi sullo stesso processore) si verifica invece il fenomeno dell’interleaving, in quanto non è mai garantito l’ordine di esecuzione (e quindi per esempio il processo P0 potrebbe richiedere di lavorare su una risorsa non ancora rilasciata da P1).
Per capirla osserviamo l’immagine: ad esempio se in Q1 il processo P1 lavora su una risorsa R condivisa con P0, quando tornerà a lavorarci al Q4, non è detto che nel frattempo questa non sia stata resa obsoleta da P0, che nel frattempo ci ha lavorato in Q2 e Q3.

Ma se nel sistema concorrente almeno le risorse sono usate una alla volta, in un ambiente parallelo si verifica anche fenomeno dell’overlapping ovvero la risorsa viene usata in contemporanea . Ad esempio P1 nel suo Q0 potrebbe utilizzare la risorsa R nello stesso momento in cui la usa P0 nel suo Q1.
Questa tipologia di errori è estremamente difficile da trovare eseguendo del semplice debugging sul codice, perché il debugging ha senso solo nel codice sequenziale, ma per la natura non deterministica della esecuzione parallela ogni scenario di esecuzione può essere differente.
E’ quindi è necessaria una progettazione che permetta correttamente ed in modo formale di garantire una esecuzione senza errori dove è il codice stesso a verificare cosa fare prima e cosa dopo.
In pratica il programmatore non può fare nessuna assunzione sulla sequenza di interleaving, sulle velocità relative dei task, sulla specifica implementazione delle istruzioni su una particolare architettura, nè sulla divisibilità delle istruzioni in un contesto preemptive.
Condizioni di Bernstein
Per comprendere il problema in termini di programmazione ed aiutarci quindi a progettare il codice per gestire bene il parallelismo introduciamo due definizioni:
– funzione atomica: istruzione o gruppo di istruzioni che agisce in modo non interrompibile su dei dati
– dominio R: insieme dei dati letti in una singola funzione atomica;
– rango R: insieme dei dati scritti in una determinata funzione atomica;
Ad esempio l’istruzione C++:
int sum = a + b;Ha come dominio l’insieme {a,b} e rango l’insieme {sum}.
Una regola generale per garantire che due istruzioni atomiche f1 e f2 possono essere eseguite in modo parallelo/concorrente senza incorrere in problemi di interleaving o overlapping, sono le condizioni di Bernstein:
R(f1) ⋂ R(F2) = ∅ -> il rango di f1 non deve coincidere col rango di f2;
R(F1) ⋂ D(F2) = ∅ -> il rango di f1 non deve coincidere col dominio di f2
D(F1) ⋂ R(F2) = ∅ -> il rango di f2 non deve coincidere col dominio di f1
In pratica le condizioni di Bernstein pongono condizioni che coinvolgono sempre il rango di una o di entrambe le funzioni e si possono sintetizzare nella condizione per cui per poter scrivere un set di dati, questo non deve essere nè scritto nè letto da altre funzioni in esecuzione concorrente o parallela.
Se un gruppo di N di funzioni F1…FN appartenenti ciascuna ad un thread separato soddisfa le condizioni di Bernstein, qualsiasi sia l’ordine di interleaving o di overlapping di esecuzione, il risultato ottenuto non cambierà e si otterrà lo stesso effetto di una esecuzione sequenziale.
Se invece non vengono soddisfate si rischia una qualche forma di inconsistenza dei dati.
Vediamo un esempio.
F1
void remove(int x) {
int partial1 = total - x;
total = partial1;
}Il cui dominio è {x, total, partial1) ed il rango (total, partial2)
F2
void add(int x) {
int partial2 = total + x;
total = partial2;
}Il cui dominio è {x, total, partial2) ed il rango (total, partial2).
Vengono quindi violate le condizioni di Bernstein. Poniamo infatti di voler eseguire questo codice in un sistema multiprocessore:
remove(5);
add(6);Esso si può tradurre, senza altri accorgimenti in una delle due seguenti sequenze di istruzioni:
Caso a:
int total = 0;
partial2 = total + 6; // (6)
partial1 = total - 5; // (-5)
total = partial1; (ora total vale -5)
total = partial2; // (ora total vale 6)Caso b:
int total = 0;
partial2 = total + 6; (6)
total = partial2; (ora total vale 6)
partial1 = total - 5; (1)
total = partial1; (ora total vale 1)Come si vede nel primo caso total = 6. Nel secondo caso total=1, che è il risultato che peraltro ci aspettiamo se dovessimo eseguire il codice in modo sequenziale.
E’ necessario individuare un meccanismo che garantisca che non sia la singola istruzione, ma le intere funzioni add e remove ad essere eseguite in modo sequenziale. Vedremo che il sistema operativo ci verrà in aiuto, con i mutex ed i semafori.
Conclusioni
Riassumendo quanto visto in questa sede e nelle dispense precedenti, I problemi che possono accadere quando si sviluppano applicazioni parallele sono i seguenti:
– overlapping/interleaving: due o più task cercano di accedere alla stessa risorsa nello stesso tempo senza sincronizzarsi tra loro;
– starvation: un task rimane in attesa di una risorsa che non gli verrà mai concessa;
– deadlock: due o più task sono legati da una dipendenza reciproca (o ciclica) di risorse.
I due processi possono quindi concorrere all’accesso delle stesse risorse sia in caso di cooperazione che di competizione, infatti la conoscenza dell’esistenza dell’altro processo richiede comunque un meccanismo che permetta a entrambi di accedere alle stesse risorse.
Nello scrivere quindi una applicazione che gestisce concorrenza e parallelismo, occorrerà quindi soddisfare 3 proprietà:
– safety: viene garantito che non ci sia interferenza, tramite una mutua esclusione;
– fairness: le richieste di risorse verranno prima o poi soddisfatte, per impedire starvation
– liveness: garantire che ogni processo terminerà la propria attività, per impedire deadlock.