
Gestione della memoria
Premessa
Come sappiamo, la memoria nella macchina di Von Neumann è rappresentata come un vettore dove ad ogni indirizzo corrisponde un valore che ha una dimensione pari ad un byte. La dimensione di questo vettore è una potenza di 2 ed ha un valore massimo che dipende dalla memoria installata nel sistema, ma che comunque non può superare la dimensione dello spazio di indirizzamento (ovvero la dimensione in bit di un registro della CPU). Quindi con una architettura a 16 bit, per esempio, possiamo memorizzare indirizzi da 0 a 65535, con 32 bit indirizzi da 0 a 232-1 con 64 bit indirizzi da 0 a 264-1.
Un indirizzo di memoria è in realtà in binario e solo per comodità viene rappresentato in decimale.
| Tecnologia | massimo binario | massimo decimale |
| 8 bit | 11111111 | 28-1 |
| 16 bit | 1111111111111111 | 216-1 |
| 32 bit | 11111111111111111111111111111111 | 232-1 |
| 64 bit | 1111111111111111111111111111111111111111111111111111111111111111 | 264-1 |
Tuttavia la rappresentazione binaria può essere molto lunga da rappresentare. E la sua rappresentazione in decimale richiede una conversione non immediata. Per questa ragione si preferisce una rappresentazione esadecimale grazie al fatto che una cifra esadecimale rappresenta una combinazione di 4 bit.
| HEX | BIN |
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
| A | 1010 |
| B | 1011 |
| C | 1100 |
| D | 1101 |
| E | 1110 |
| F | 1111 |
Quindi ad esempio: 11000010 è pari a C2 eseguendo una banale conversione di 4 bit alla volta.
Viceversa D6 è pari a 11010110 convertendo ogni cifra esadecimale in 4 bit.
La tabella sopra indicata diventa quindi:
| Tecnologia | massimo binario | massimo decimale | massimo esadecimale |
| 8 bit | 11111111 | 28-1 (3 cifre) | FF |
| 16 bit | 1111111111111111 | 216-1 (5 cifre) | FFFF |
| 32 bit | 11111111111111111111111111111111 | 232-1 (10 cifre) | FFFFFFFF |
| 64 bit | 1111111111111111111111111111111111111111111111111111111111111111 | 264-1 (20 cifre) | FFFFFFFFFFFFFFFF |
La trattazione da adesso in avanti si riferirà quindi alla memoria in esadecimale.
Per identificare un numero esadecimale e non confonderlo da un decimale, si usa normalmente il prefisso 0x.
Quindi 100 è 100, mentre 0x100 è pari a 256.
Partizionamento della memoria: un approccio “easy”
Nella sua versione originale, la macchina di Von Neumann era progettata per usare un solo programma alla volta con annessi i suoi dati. Il sistema operativo moderno invece gestisce più programmi allo stesso momento, chiamati processi, e divide il tempo di cpu in quanti di memoria mediante un meccanismo di time-sharing.
Ma la memoria, come viene gestita? In questo caso il meccanismo deve essere di space-sharing, ovvero di suddivisione della memoria fisica in porzioni separate, assegnate ciascuna ad un solo processo. Inoltre va previsto un meccanismo che garantisca al processo di accedere alla propria memoria logica in modo sicuro, riservato ed indipendente. In pratica il processo lavora come se avesse un’unica area di memoria a disposizione, e deve ignorare del tutto che questa sia una porzione di memoria fisica. Ovvero deve esserci un meccanismo analogo a quello già visto per le CPU.
Il primo metodo ipotizzato è quello di inserire le partizioni nella memoria in modo contiguo. Ad ogni processo viene assegnato un blocco contiguo di memoria libera che viene assegnato. E’ poi sufficiente memorizzare l’inizio e la fine di quel blocco di memoria fisica e si ricava l’indirizzo iniziale e finale della memoria logica a disposizione del processo.
Qui un esempio con un computer con 4GB di memoria, con 3 processi che occupano circa 1,5GB.
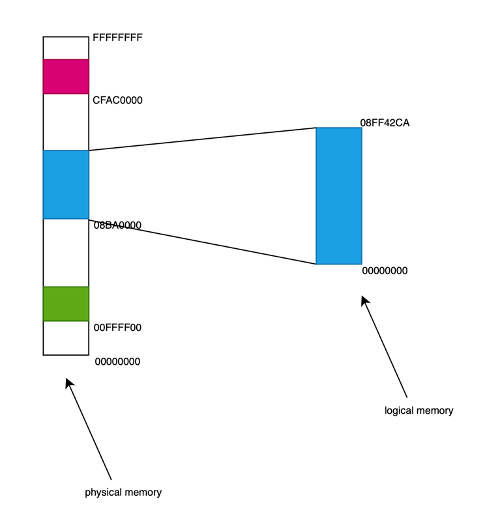
Il grosso vantaggio è che questo sistema è molto semplice da realizzare ed anche molto veloce, in quanto è facile calcolare l’indirizzo logico a partire da quello fisico. Il limite di questo sistema è che è possibile allocare, cioè destinare ad un processo, solo un’area contigua pari alla più grande area di memoria libera disponibile. Nell’esempio qui sopra è evidente che sebbene siano disponibili 2,5GB di memoria, è possibile inserire un processo indicativamente di 500MB perchè è l’area più grande disponibile.
Una eventuale soluzione di “deframmentare” la memoria copiando l’area dei processi in modo contiguo non è efficace. Questa soluzione è molto complessa, e poco praticabile per le prestazioni di copia della memoria, senza considerare che diventa inutile se un processo richiede ulteriore memoria oltre quella già allocata. Problema non da poco, se la memoria di tutti i processi è inserita in modo contiguo!
Paginazione
Questo modello venne rapidamente abbandonato, e ad esso venne sostituito un meccanismo basato sulla paginazione. In pratica la memoria viene suddivisa in pagine di dimensione opportuna, ed ogni pagina è assegnata ad un solo processo.
Qui un esempio semplificato.
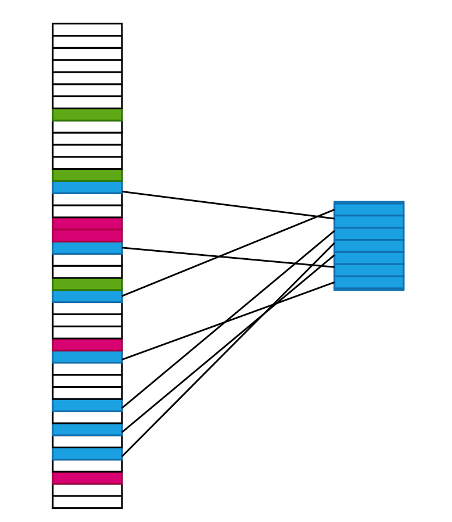
Quindi:
– la memoria fisica è divisa in pagine.
– ogni pagina fisica può essere libera o assegnata ad un solo processo;
– ad ogni pagina fisica assegnata, corrisponde ad una pagina logica di processo;
– è presente una tabella che consente di associare pagine fisiche a pagine logiche di un determinato processo.
– un programma che vuole accedere un indirizzo (logico), deve convertire la pagina (logica) a cui appartiene ad una pagina fisica.
Per capire meglio ipotizziamo di avere una memoria di 4GB ovvero 230 bytes, con indirizzi da 0 a FFFFFFFF. Se ipotizziamo pagine di dimensione 4KB (ovvero 212 bytes) esse dovranno essere 218 cioè un 1MB (infatti 1MB x 4KB fa 4GB). In esadecimale:
– ogni indirizzo nella pagina (detto offset) sarà da 000 a FFF (4KB);
– ogni numero di pagina sarà invece da 00000 a FFFFF (1MB).
– ogni indirizzo di memoria sarà quindi composto dal numero di pagina + offset:
| pagina | offset |
| 025CF | 34A |
Nell’eseguire la conversione si converte solo il numero di pagina, non l’offset.
| Pagina logica | Processo PID | Pagina fisica |
| ABC20 | 1000 | 025CF |
L’indirizzo:
| ABC20 | 34A |
diventa quindi:
| 025CF | 34A |
Qui graficamente:
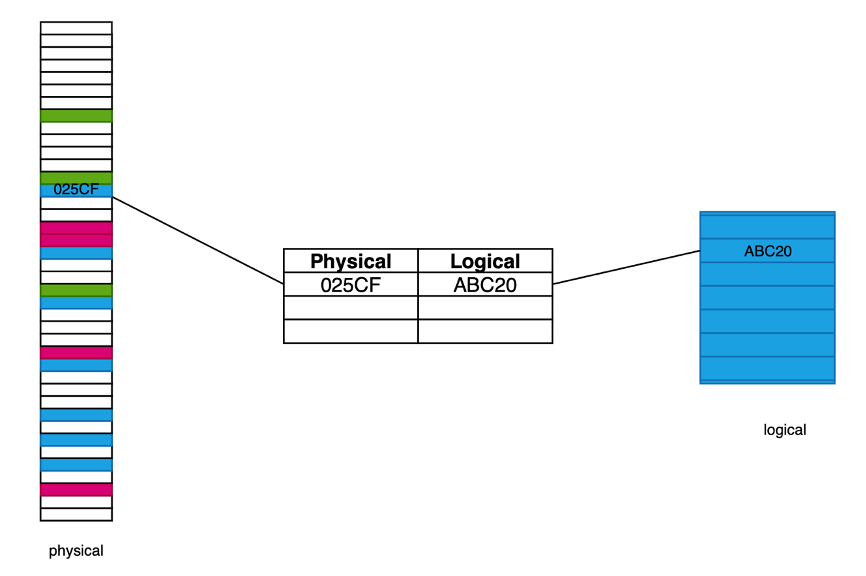
La tabella di conversione è registrata in memoria (nello spazio della memoria del sistema operativo) ma l’effettiva conversione da indirizzo logico (richiesto dal processo in esecuzione nella CPU) a indirizzo fisico (concesso dalla memoria tramite indirizzamento diretto) è eseguita da un componente hardware chiamato MMU (Memory Management Unit), per ragioni prestazionali.
Questo componente:
– riceve una richiesta di accesso ad un indirizzo logico;
– estrae la pagina logica dall’indirizzo;
– consulta la tabella;
– esegue la conversione della pagina logica in pagina fisica;
– infine accede alla memoria caricando l’indirizzo fisico.
Il processo in esecuzione riceve l’accesso alla memoria richiesta (in lettura o scrittura) senza essere consapevole dell’indirizzo fisico associato a quello logico.
La MMU quindi per accedere al contenuto di un indirizzo fisico richiede 2 accessi alla memoria.
Caching
Si ricorda che in un processore, l’accesso ad un registro di memoria avviene in modo sincrono con l’istruzione in esecuzione, ovvero nello stesso ciclo di clock, quindi in un processore odierno con tempi nell’ordine del miliardesimo (1 x 10-9) di secondo.
La memoria fisica invece ha tempi di accesso nell’ordine del milionesimo di secondo (1 x 10-6) quindi circa 1000 volte più lenta di una cpu. Quindi in tutto questo lasso di tempo il processore è fermo in attesa dell’accesso alla memoria, vanificando le sue migliori prestazioni (addirittura in alcuni sistemi multithreading la cpu mette in wait il thread e ne esegue un altro per non perdere tempo).
Se a questo aggiungiamo che ad ogni accesso alla memoria in realtà occorre farne 2, si raddoppiano i tempi di accesso, con un sistema quindi ancora più lento.
Per risolvere questi due problemi, sono state introdotte le cache.
Una cache consiste in una memoria tampone (detto “buffer”) che memorizza copia dei valori di memoria più frequentemente usati in modo da non doverli andare a caricare dalla memoria più lenta. La cache del processore ha la stessa frequenza di accesso del processore quindi l’accesso ad un dato in cache è istantaneo e non rallenta la cpu.
Il meccanismo di funzionamento è molto semplice: il processore quando cerca un indirizzo va prima a cercarlo in cache se questo è presente (cache hit) utilizza il valore ed incrementa un contatore di utilizzo (che indica quanto questo valore è usato). Periodicamente la cache decrementa i contatori di accesso degli indirizzi meno usati, riducendo il loro valore a 0. Se la cpu accede per effettuare una scrittura la cache non viene coinvolta, e la cpu scrive direttamente in memoria (mettendo comunque il valore anche in cache).
Se invece si realizza un cache miss (indirizzo non trovato), questo viene ricercato nella memoria più lenta, e caricato in cache sostituendo una cella tra quelle con contatore più basso (cioè meno usate). In questo modo la cache mantiene internamente le celle più usate e rinnova costantemente quelle meno usate. Questo algoritmo di chiama LRU (Least Recently Used).
I moderni computer implementano in realtà più cache, disposte su più livelli:
– una cache di I livello, molto piccola e costosa, che ha frequenze come quella della cpu;
– una cache di II livello, meno costosa, più grande e meno veloce della precedente;
– una cache di III livello, ancora più grande e meno costosa.
Tutte le cache sono comunque fatte in modo simile, e ciò che cambia sono le prestazioni e le dimensioni. Gli algoritmi di rimpiazzamento possono essere anche più articolati, perchè cercano di copiare in cache non solo il dato richiesto ma anche i dati ad esso associati in modo da minimizzare la probabilità di cache miss.
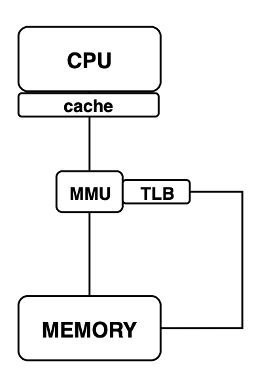
Infine, anche la MMU ha una sua cache, chiamata TLB (Translation Lookahead Buffer) che permette di memorizzare i numeri di pagina più usati per impedire il doppio accesso alla memoria.
Qui uno schema riassuntivo della porzione di macchina di Von Neumann con MMU e cache.
Memoria virtuale
In molti sistemi operativi per personal computer o lato server, la memoria fisica può non bastare a contenere tutta la memoria dei processi. Può essere previsto quindi di estendere “virtualmente” la memoria usando un file su disco, detto file di scambio (swap file), che contiene anch’esso pagine di memoria. Memoria fisica e file di swap creano quindi uno spazio di memoria, detto virtuale, che è la somma delle due memorie.
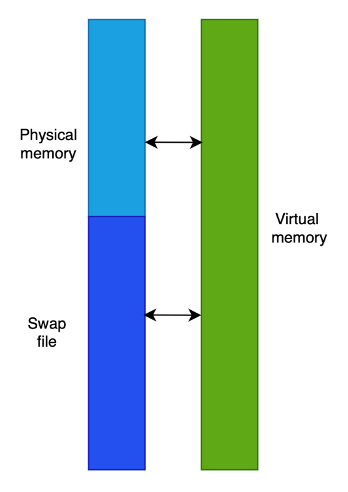
Questa memoria non è una memoria hardware, ovviamente, in quanto l’estensione su disco è un file presente su una periferica di I/O ma il kernel vede entrambe le memorie come un’unica memoria, e può quindi salvare ogni singolo processo in pagine di memoria virtuale che possono essere ciascuna fisicamente in memoria o su disco.
Qui lo schema che associa memoria logica alla memoria virtuale, e da questa a quella fisica e lo swap.
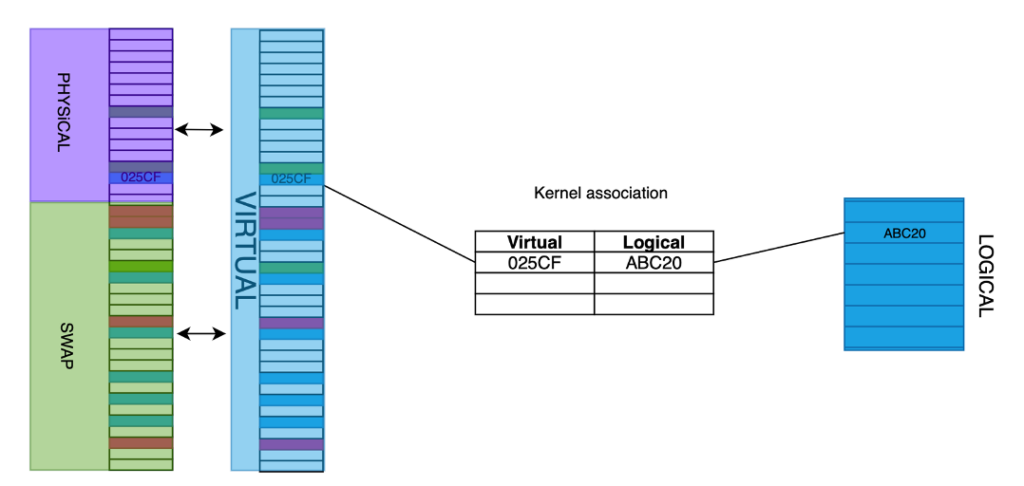
Quando un processo vuole accedere ad una pagina logica, e questa corrisponde ad una pagina fisica, avviene un page-hit, ed il comportamento è identico a quanto visto nel precedente paragrafo.
Quando un processo vuole accedere ad una pagina logica, che corrisponde ad una pagina su swap, avviene un page-fault:
– il processo viene messo in wait;
– il kernel attiva un processo real time (su Windows priorità > 16, su Linux < 99 FIFO) che va a caricare la pagina dal file di swap e la copia in una pagina di memoria libera; viene aggiornata la tabella di associazione logica-fisica;
– il processo viene rimesso in ready;
– quando il processo torna running, accederà alla memoria come se nulla fosse accaduto (dal suo punto di vista).
A grandi linee, quindi, lo swapping altro non è che una forma di caching da disco a memoria.
Ricordiamo che l’accesso alla memoria fisica è nell’ordine del milionesimo di secondo (1×10-6) mentre l’accesso al disco è nell’ordine del millesimo di secondo (1×10-9) quindi ogni volta che avviene un page-fault il processo rallenta vistosamente (anche perchè viene messo in wait) e l’utente se ne può accorgere. Questo evento è ovviamente considerato, dall’utente, come un sintomo di “lentezza” del sistema e in quanto tale uno degli obiettivi primari del sistema di gestione della memoria virtuale (e quindi del sistema operativo) è quello di ridurre al minimo i page-fault.
Il sistema operativo non ha modo di sapere quali indirizzi di memoria andrà a richiedere un processo: gli algoritmi di gestione si basano su variabili casuali[1], quindi su un processo stocastico[2]. Tramite l’analisi dei page fault l’analisi stocastica (svoltasi su processi reali in macchine reali) ha determinato una funzione di probabilità dei page-fault in funzione della quantità di pagine occupate di un processo. Questa funzione, esponenziale, mostra che al di sopra di una certa percentuale di occupazione la probabilità di page fault cala drasticamente, come è facile visualizzare dal seguente grafico.
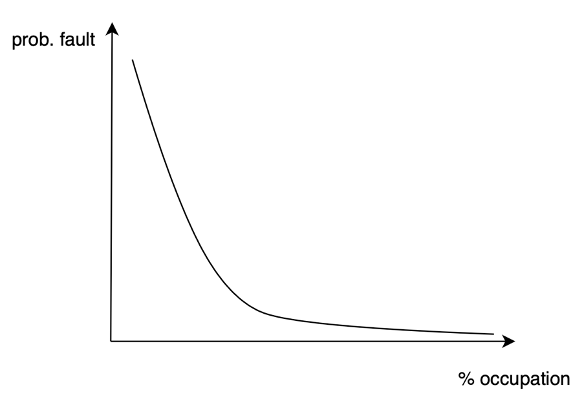
Questa percentuale dipende dal singolo processo: alcuni hanno una maggiore variabilità di richiesta di indirizzi di memoria nella propria memoria (detta “demand-paging“), altri richiedono più memoria in assoluto (detta “working-set“) ed ovviamente sono in competizione tra loro. Un demand paging di grandi dimensioni implica che ci sono molti page fault: il processo accede a molte pagine diverse in tempi anche brevi. Un working set di grandi dimensioni implica che magari usa sempre le stesse pagine, ma queste possono essere molte.
Ad esempio una applicazione come Netflix ha un working set relativamente ampio (scarica e visualizza file video) ma ha un piccolo demand-paging (scarica continuamente nuove porzioni del film da internet ma nella stessa area di memoria). Viceversa, Chrome ha un working-set relativamente piccolo (scarica pagine html) ma può avere un demand-paging enorme (basta aprire un gran numero di schede di pagine differenti).
Compito del gestore della memoria è quindi:
– trovare la percentuale di occupazione della memoria “ideale” di ogni processo;
– bilanciare i vari processi, tenendo conto delle loro caratteristiche (priorità) e delle loro esigenze (background o foreground).
Swapping in Linux e Windows
Quando avviene un page-fault il sistema operativo copia la pagina dallo swap alla memoria fisica. Tuttavia deve essere disponibile una pagina di memoria fisica libera per poter copiarci dentro la pagina che si sta caricando. Questo significa che il sistema operativo deve gestire anche lo scaricamento delle pagine dalla memoria fisica allo swap.
Linux e Windows hanno due comportamenti differenti tra loro.
Windows gestisce le pagine in memoria dando priorità al working-set: determina per ogni processo un numero ottimale di pagine da tenere in memoria fisica per minimizzare la probabilità di page fault. Per minimizzare invece il problema legato al demand-paging invece, esegue la cosiddetta “prefetch“: carica ad ogni page-fault non solo la pagina richiesta ma anche un certo numero di pagine contigue ad essa (presuppone che il processo potrebbe richiedere delle zone di memoria vicine a quella che desidera).
Per gestire invece quali pagine selezionare per lo scaricamento dalla memoria, tiene diverse liste di pagine in ordine di importanza: la lista delle pagine dei processi in foreground in stato ready, la lista delle pagine dei processi foreground in stato wait, e poi liste di pagine dei processi via via meno importanti (background e wait). Periodicamente avvia un processo che libera memoria fisica, che seleziona le pagine da “swappare” a partire dalle liste meno importanti e solo se necessario sale di importanza (ad esempio se viene avviato un nuovo processo o richiesta molta memoria da un processo esistente). Questo meccanismo garantisce che i processi utente foreground restino veloci e vengano penalizzati i processi in background.
Linux ha un meccanismo basato su due liste, quella delle pagine attive (in memoria) e quella delle pagine inattive (su disco). La lista delle pagine attive è ordinata in base all’ultimo accesso. Nella prima lista vengono inserite le pagine usate più frequentemente, in quelle inattive quelle meno frequenti.
Quando un processo richiede una pagina:
1) se questa è presente nelle pagine attive, viene richiamata, e finisce in cima alla lista.
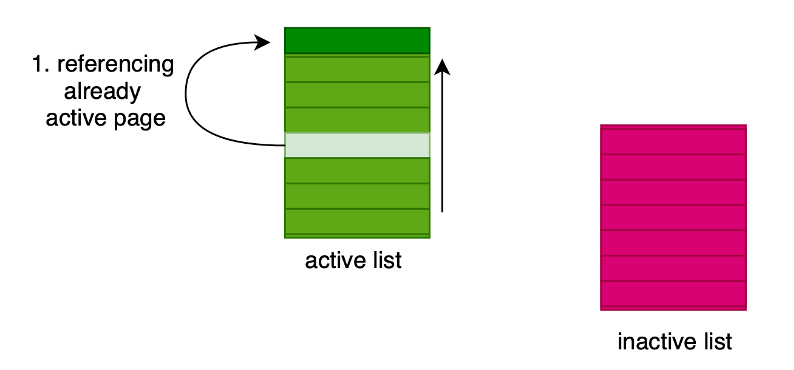
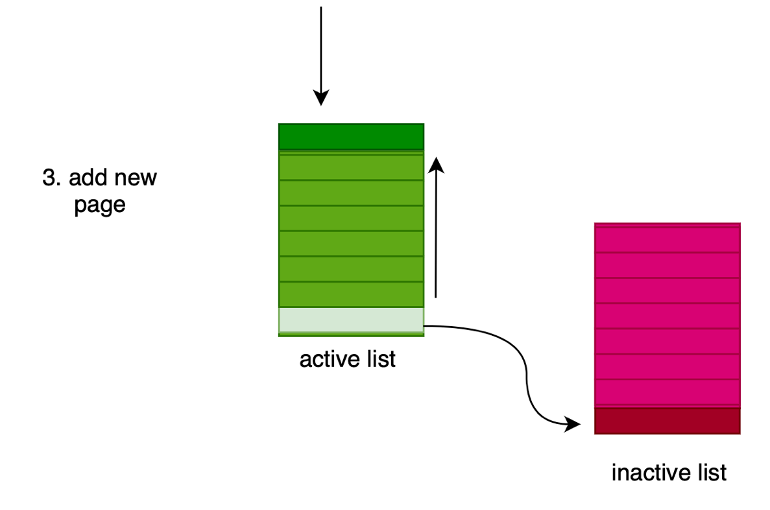
2) se non è presente nelle pagine attive, ma è su disco, viene eseguito lo swap e viene aggiunta alla lista delle pagine attive in memoria (in cima); inoltre, per mantenere lo stesso numero di pagine, viene eseguito lo swap dalla memoria al disco della più vecchia delle pagine attive.
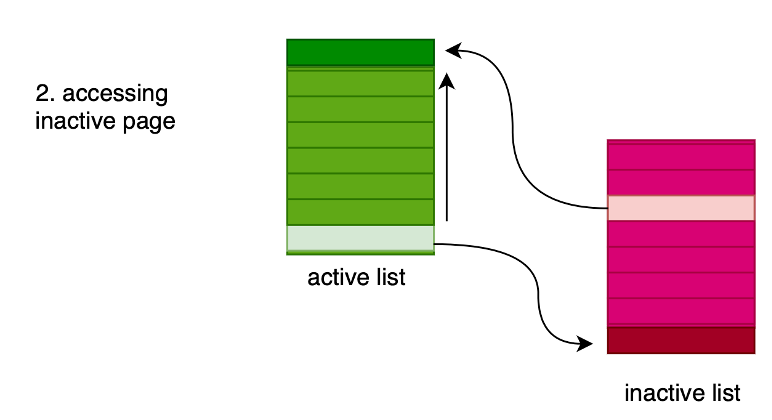
3) se la pagina richiesta non è in nessuna lista, viene creata appositamente.
E gli altri sistemi operativi?
– MacOS utilizza meccanismi simili a Windows.
– iOs e Android non usano, in genere, memoria virtuale, per ragioni legate sia alle prestazioni che al risparmio energetico. Quindi i processi che occupano memoria se in background, possono essere terminati dal sistema operativo.
[1] Una variabile casuale (detta aleatoria o stocastica) è una variabile che può assumere valori diversi in dipendenza di qualche fenomeno aleatorio (o casuale). Ad esempio il risultato del lancio di un dado da 6 è una variabile casuale.
[2] Un processo stocastico è un processo che si basa su variabili casuali e su funzioni che godono di proprietà statistiche in base ad un certo parametro (in genere il tempo). Ad esempio lanciando molte volte un dado nel tempo è possibile realizzare un processo stocastico che permette di calcolare la probabilità che esca un 1, un 2, un 3, ecc.