Stack
Il modello di memoria della macchina di Von Neumann
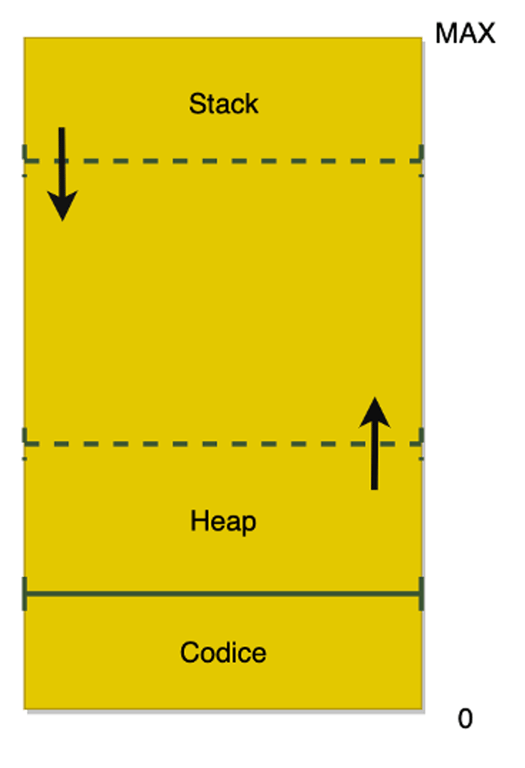
Nella macchina di Von Neumann, la memoria è organizzata come un grosso array, ovvero una sequenza di celle ciascuna con un indirizzo assoluto (da 0 alla memoria massima allocabile). La memoria massima logica di un programma è in genere data dalla sua architettura: i primi computer potevano avere pochi K di memoria, quelli moderni arrivano a decine di GB.
La memoria è unica econtiene sia le istruzioni che i dati, cioè le variabili, le strutture dati, i dati di input/ouput ed ogni dato di elaborazione del programma.
In molte implementazioni il codice viene memorizzato nella parte bassa della memoria, e ciò avviene al caricamento del programma in memoria (da parte del sistema operativo).
Il programma in esecuzione ha pieno accesso alla memoria, e quindi può leggere e scrivere in qualsiasi locazione di memoria, conoscendone il solo indirizzo, cioè la posizione in memoria. I programmi scritti in linguaggio ad alto livello hanno comunque meccanismi di protezione della memoria, e quando vengono eseguiti forniscono al programmatore direttamente l’accesso a variabili e tipi di dato (numeri, stringhe, liste, ecc.).
Internamente però queste variabili vengono memorizzate nell’area di memoria immediatamente “sopra” al codice, che viene chiamata “heap” (cumulo). Il programma alloca dello spazio in memoria, in base alle dimensioni delle strutture dati da utilizzare e agli algoritmi previsti da quel linguaggio ad alto livello (ad es. Java o Python).
La memoria “in alto” invece viene utilizzata per memorizzare le chiamate ai sottoprogrammi (detti anche subroutine). I sottoprogrammi sono parti di un programma che possono essere eseguite più volte in parti diverse del programma. Essi in genere svolgono compiti di utilità e semplificano lo sviluppo di software, evitando di ripetere di scrivere lo stesso codice. Nei linguaggi ad alto livello sono chiamati in genere “funzioni”.
Qui un esempio di chiamata di funzione (somma tra loro tutti gli interi compresi tra 1 a n):
int sum(int n) {
int result = 0;
for (int i i=0; i<n; i++) {
result += i;
}
return result;
}
int s = sum(4);Nella chiamata al sottoprogramma, il chiamante cede il controllo alla funzione del sottoprogramma, a cui passa eventualmente dei parametri. Alla fine tuttavia il chiamato deve restituire il controllo al chiamante, facendo eseguire l’istruzione successiva alla chiamata.
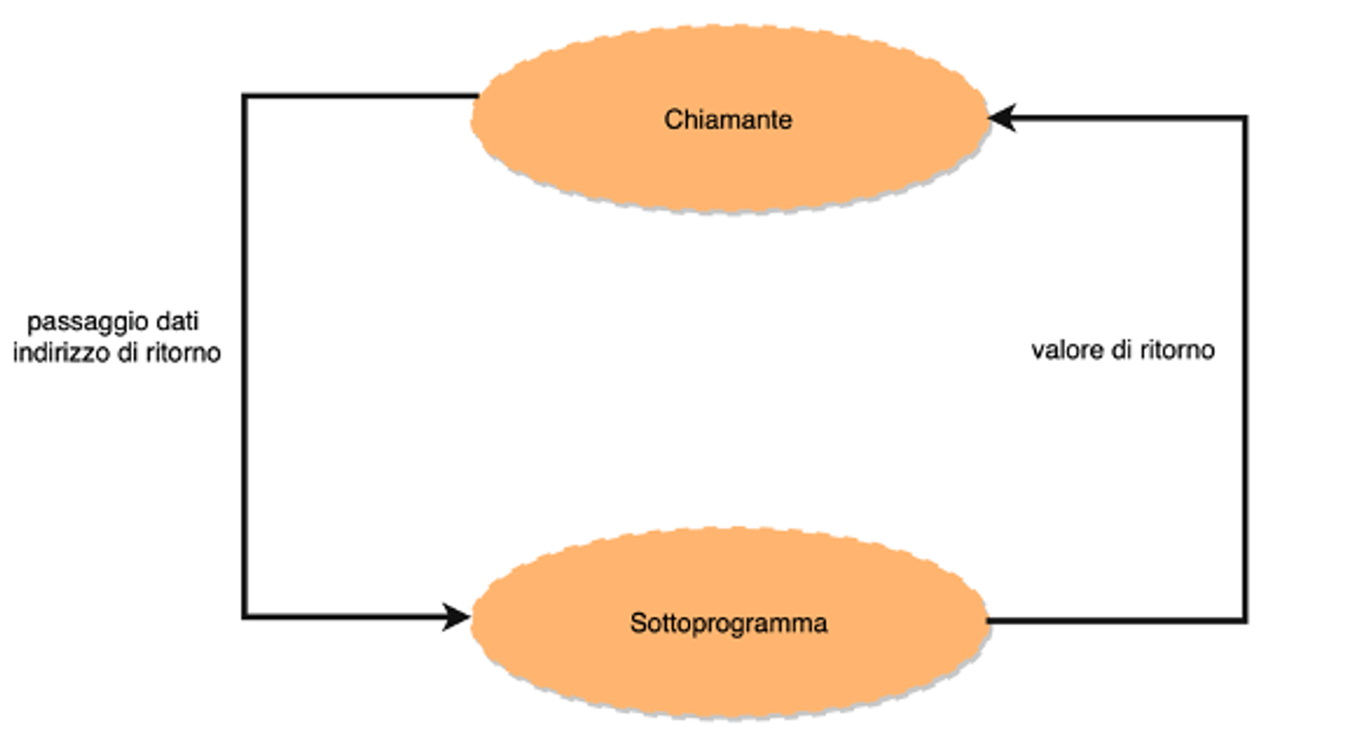
Per poter eseguire quindi le chiamate ai sottoprogrammi occorre un “meccanismo” che memorizzi sia l’indirizzo di ritorno della chiamata, sia i parametri o argomenti che questi possono ricevere. Inoltre se sono presenti vanno memorizzati anche eventuali valori di ritorno.
Queste informazioni non si possono mettere in una posizione fissa della memoria, perchè anche un sottoprogramma ne può chiamare a sua volta un altro, e quindi deve poter anche lui memorizzare indirizzi di ritorno, parametri in ingresso e valori di ritorno. E’ necessaria una struttura dati dinamica, in memoria, che memorizzi queste informazioni, e che allo stesso tempo sia facile e veloce da utilizzare.
Questo problema venne risolto brillantemente da Von Neumann facendo ricorso allo stack, una struttura matematica che si usa in programmazione.
Vediamo di che si tratta.
Cos’è lo stack?
Lo stack (“pila”) è una struttura dati matematica che si usa in informatica per memorizzare liste di elementi secondo il principio LIFO (Last In First Out). In altri termini l’accesso alla pila è solo tramite l’ultimo elemento e le due uniche operazioni possibili sono:
- push: aggiunta di un elemento
- pop: estrazione di un elemento e sua rimozione
Esempio: ipotizziamo di avere all’inizio uno stack vuoto (nessun elemento). Se eseguiamo PUSH (5) avremo:

Lo stack contiene un solo elemento. Se eseguiamo una PUSH(7) avremo:
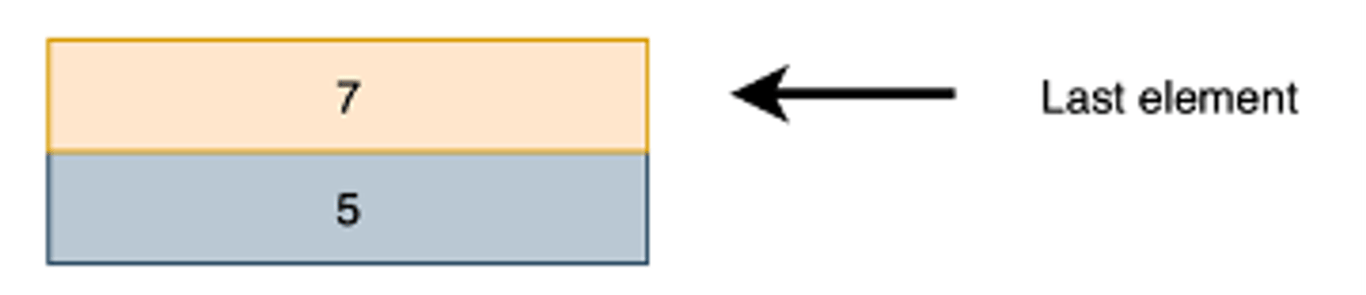
Ora sono due elementi. Se aggiungiamo ancora il valore 4 con PUSH(4) avremo:
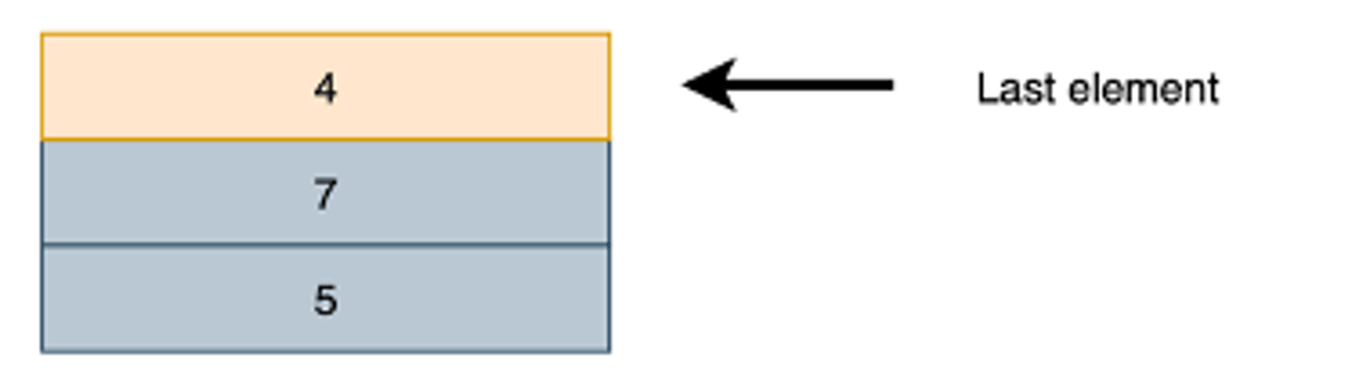
E così via. Ma attenzione, se eseguiamo POP() estrarremo l’ultimo valore (cioè 4) e rimarrà:

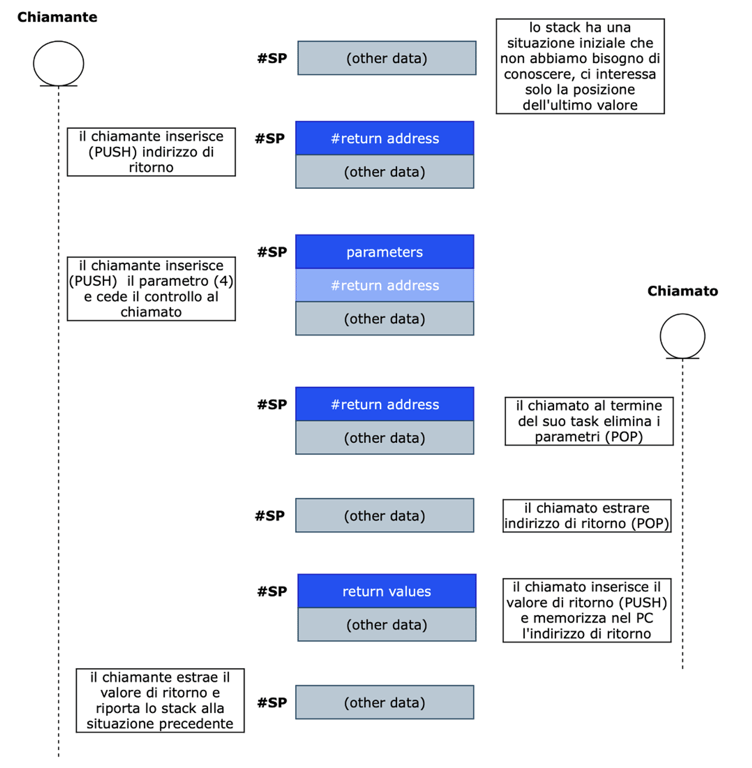
La macchina di Von Neumann prevede un registro della CPU che si chiama SP (“stack pointer”) che contiene l’indirizzo dell’ultima cella dello stack.
Quando un programma (o sottoprogramma) ha bisogno di chiamare un sottoprogramma, memorizza nello stack :
1) indirizzo di ritorno (PUSH)
2) parametri opzionali (PUSH)
E poi chiama (nella CPU si modifica il PC) il sottoprogramma.
Il sottoprogramma esegue la sua attività, SENZA conoscere informazioni sul chiamante, ma lavorando solo sui parametri presenti nello stack.
Al termine della sua esecuzione (quando cioè viene richiamato “return”):
3) estrae ed elimina i parametri (POP)
4) estrae indirizzo di ritorno (POP)
5) aggiunge eventuali valori di ritorno (PUSH)
6) modifica il PC e quindi l’istruzione successiva sarà quella successiva del chiamante.
Il chiamante:
7) estrae il valore di ritorno dallo stack (se presente) (POP)
Lo stack (acceduto mediante SP) è quindi un meccanismo che permette di:
- scambiare dati tra chiamante e chiamato;
- memorizzare dati e poterli cancellare dinamicamente quando non servono più, partendo dal più recente;
- siccome è una pila, ogni procedura in esecuzione può a sua volta chiamare delle sottoprocedure.
La limitazione dello stack è ovviamente data dalla dimensione della memoria: se la memoria dello stack occupa memoria fino ad arrivare a raggiungere lo heap, succede una problematica che si chiama “stack overflow”. Di solito all’avvio del programma viene memorizzato un limite superiore alla dimensione dello stack proprio per evitare questo tipo di problema, ed alcune architetture prevedono un riconoscimento hardware.
Qui sotto lo schema riassuntivo che mostra cosa succede allo stack in una tipica chiamata di sottoprogramma.