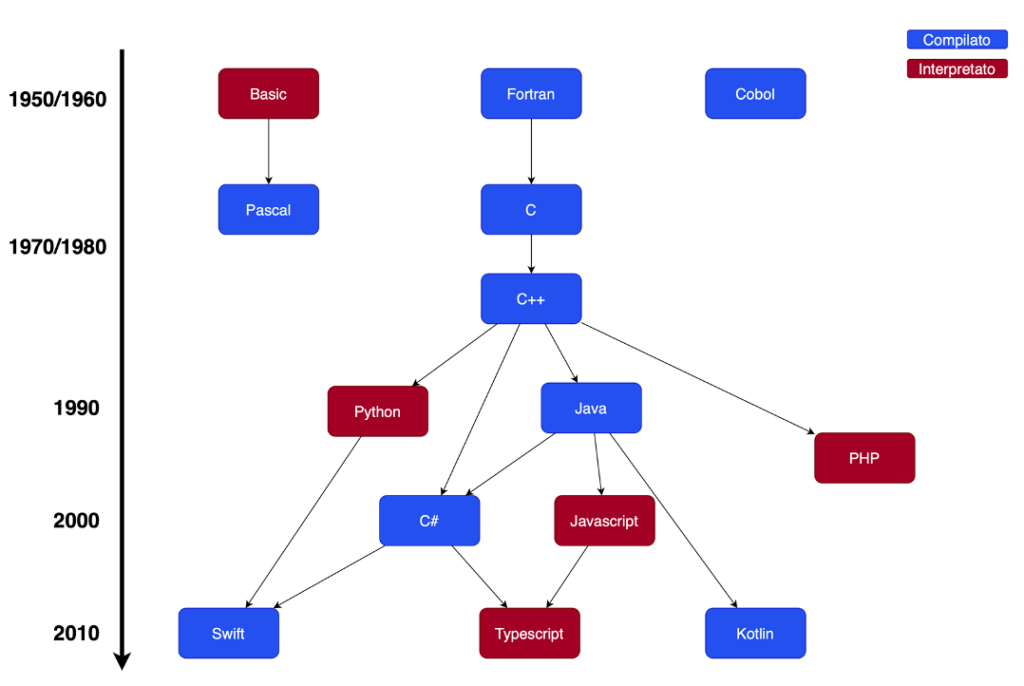
Linguaggi compilatori ed interpreti
Evoluzione dell’architettura di Von Neumann
L’architettura di Von Neumann è un modello semplificato che descrive l’architettura di un sistema che comprende una CPU ed una memoria centrale, oltre ad un componente di I/O.
Nei sistemi moderni si sono tuttavia evoluti, a partire dagli anni 80, alcune importanti innovazioni:
– i processori multi stadio, ovvero con una pipeline;
– i processori multi core, ovvero con più core;
– le cache multi livello.
Descriviamo queste innovazioni.
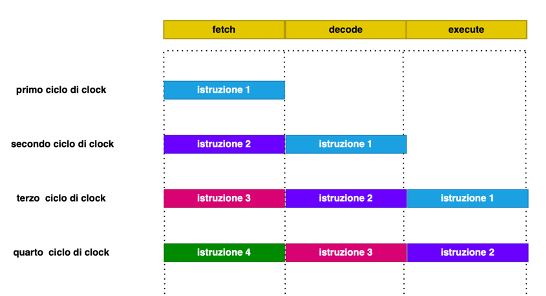
La pipeline consiste nell’esecuzione, nella cpu, di più istruzioni in contemporanea tramite la suddivisione della cpu in sezioni, dette stadi, dove viene eseguita una specifica fase del ciclo di clock. Il processore esegue cioè la fetch della prima istruzione di codice, poi quando passa alla decode, comincia la fetch della seconda istruzione, quando la prima istruzione va in esecuzione, si esegue la decode della seconda, e quindi la fetch della terza.
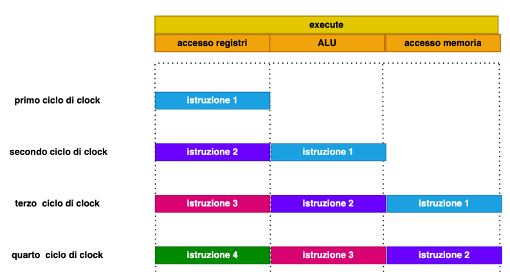
Non solo ma anche l’esecuzione viene divisa in stadi: ad esempio nell’istruzione si può per esempio suddividere l’istruzione in più fasi, come ad esempio il caricamento degli operatori, l’eventuale operazione aritmetico-logica, la scrittura dei registri, la scrittura della memoria, e quindi tenere attive più esecuzioni di istruzioni successive in contemporanea.
Questo meccanismo non funziona quando una istruzione blocca la successiva (ad esempio perchè bisogna fare un calcolo) oppure si opera un salto. In questi casi l’istruzione successiva viene annullata e si perde tutta la pipeline successiva. Poiché però la percentuale delle istruzioni bloccanti in generale è inferiore al 30%, nei processori con pipeline si ottiene a parità di clock un incremento di prestazioni notevole, sfruttando il fatto che in ogni istante si tende a usare ogni componente della cpu.
Il processore multi-core invece consiste nella replicazione della cpu, garantendo quindi l’esecuzione di più istruzioni in contemporanea, con la replicazione di tutti i registri, della CU e della ALU. Il sistema operativo quindi ha a disposizione più cpu a cui assegnare le risorse, con l’ovvio vantaggio che è possibile eseguire più applicazioni in contemporanea. Questa funzione è alla base della programmazione concorrente.
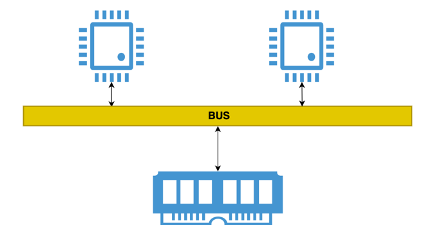
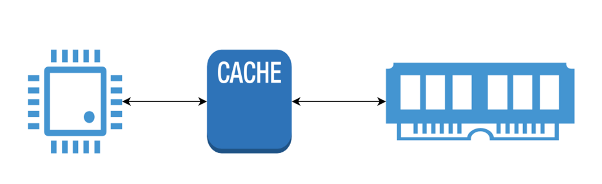
La cache è un meccanismo, gestito a livello hardware, per cui il processore non comunica direttamente con la memoria, ma con una cache del processore, che ha una velocità simile a quella della cpu e superiore a quella della ram, che conserva i dati di memoria più utilizzati, e ne permette il ricaricamento rapido da parte del processore nella fase di caricamento.
RISC e CISC
Nel corso degli anni 70 si sono evolute due famiglie distinte di processori: i processori CISC e RISC. I primi hanno avuto come base una strategia basata su istruzioni macchina più complesse, i secondi su istruzioni più semplici ed un maggior numero di registri. Oggi queste due architetture fanno riferimento in particolare, rispettivamente alle tecnologie Intel e ARM.
Vediamo le differenze in questa tabella:
| RISC | CISC | |
| ISA (Instruction Set Architecture) | ridotto | ampio |
| Ortogonalità | ampia | ridotta |
| Numero registri | molti | pochi |
| Cicli per istruzione | 1 | più di 1 |
| CU | cablata | microprogrammata |
| ALU | solo su registri | anche su memoria |
| applicazioni | calcolo | multipurpose |
| pipeline | si | parziale |
| dimensioni codice | grande | piccolo |
| esempi | ARM, GPU | PC |
Alcune definizioni:
– ISA: set di istruzioni Assembly
– Ortogonalità: capacità di una istruzione di accettare parametri di tipo differente (registri, indirizzi e valori assoluti)
– CU cablata e microprogrammata: nella prima la decodifica delle istruzioni è integrata nell’hardware fisico della macchina. Nell’architettura microprogrammata è invece possibile programmare (tramite codici) in modo da modificare il set di istruzioni base.
– GPU: cpu delle schede grafiche.
Linguaggi ad alto livello
l linguaggio Assembly è un linguaggio a basso livello. Esso dipende dall’architettura hardware della macchina, ed anche quando contiene istruzioni complesse (nei processori CISC) essere restano assai specifiche per alcune tipologie di dati (es. stringhe o vettori). In particolare, resta complesso gestire un ciclo, eseguire procedure, fare calcoli con più operandi, gestire molte variabili. Il programmatore deve tenere infatti conto di avere una memoria limitata, di dover fare le conversioni di tipo e di memorizzare sempre nello stack le informazioni. Nei programmi di maggiore complessità diventa estremamente oneroso sviluppare e quindi si rende necessario semplificare.
Per questo fin dagli albori dell’informatica sono stati progettati linguaggi cosiddetti “ad alto livello” con lo scopo di dare al programmatore una serie di strumenti di programmazione più vicini al suo modo di pensare e di nascondere i dettagli, come lo stack, i registri, le limitazioni di calcolo, ecc. In pratica un programma scritto con un linguaggio ad alto livello introduce un insieme di astrazioni più vicine al modo di pensare di un essere umano:
– istruzioni condizionali;
– istruzioni di ciclo;
– tipizzazione delle variabili;
– strutture dati complesse.
Come viene tradotto un linguaggio ad alto livello in codice macchina?
Tramite un programma che automaticamente esegua la traduzione, ed in modo trasparente per il programmatore, che quindi non deve essere tenuto a conoscere le istruzioni macchina.
Sono previste due tecniche: la compilazione e l’interpretazione.
Compilazione
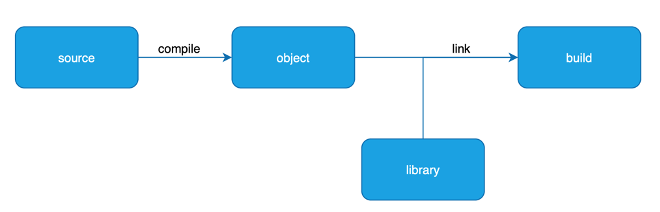
La compilazione consiste nel tradurre, in una sola macrooperazione, il codice ad alto livello direttamente in codice macchina. Le istruzioni vengono analizzate e per ogni gruppo viene creato il corrispondente codice macchina, i simboli e le variabili vengono memorizzati in memoria. La compilazione viene effettuata una volta soltanto e questa produce un file detto oggetto, che contiene il codice pronto ad essere eseguito.
Il software che esegue la compilazione, il compilatore, assume un ruolo fondamentale nella qualità del codice prodotto. Il compilatore deve essere specifico per l’architettura dove verrà eseguito il codice: quindi per ogni architettura è previsto uno specifico compilatore.
In genere, comunque, quando si scrive una applicazione, si fa uso anche di codice già pronto per svolgere operazioni pronte, ad esempio per svolgere calcoli, scrivere su disco, ecc. Questo codice non è parte dell’applicazione che scrive il programmatore, ma è parte di una o più librerie esterne, generalmente già compilate e pronte per essere inserite nel programma finale.
Pertanto, alla fine della compilazione, file oggetto e librerie vengono collegati tra loro. Questa operazione viene chiamata linking. Il risultato del linking viene chiamato build, ed assume la forma di una applicazione eseguibile, oppure un file da eseguire su un server, o una cartella che contiene tutto il codice pronto.
Una applicazione compilata, cioè una build, è una applicazione scritta in linguaggio macchina. Ma è una applicazione realizzata da un sistema automatico, che usa quindi algoritmi che cercano di creare un codice che tiene conto anche delle specificità del linguaggio di programmazione e delle caratteristiche della cpu verso cui si compila. Questo rende il codice compilato più o meno efficiente anche in base al linguaggio di programmazione e le tecniche di programmazione adottate dal programmatore. Le prestazioni potrebbero essere quindi inferiori rispetto a quelle di un programma esplicitamente progettato in Assembly. Questa è la ragione per cui per alcune attività critiche dove sono necessarie prestazioni (e nessun errore) si usa ancora l’Assembly per progettare e realizzare il software.
Interpretazione
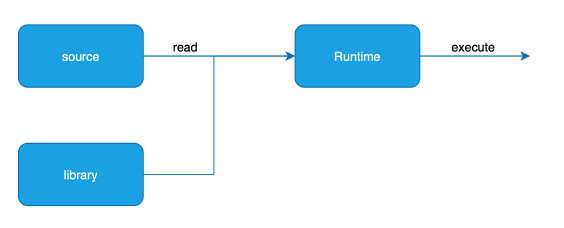
L’interpretazione consiste nell’azione di tradurre ed eseguire le singole istruzioni del linguaggio ad alto livello. Ogni singola riga di codice viene analizzata ed eseguita all’interno di un contesto di esecuzione che memorizza le variabili, i cicli in corso, le chiamate di funzione, ecc. Il software che si occupa dell’esecuzione del programma (e quindi della creazione del contesto di esecuzione) si chiama runtime, e l’interprete è quella parte del runtime che appunto interpreta ed esegue le istruzioni. Il linguaggio ad alto livello interpretato viene in genere chiamato linguaggio di scripting.
L’esecuzione del codice di scripting avviene ad ogni singola esecuzione. L’esecuzione di codice interpretato ha il grande vantaggio di non dover scrivere un compilatore. Questo significa però prestazioni inferiori, perchè non viene più eseguito codice macchina, ma codice ad alto livello.
Tenuto conto dei pro e dei conto delle due tecniche, negli ultimi decenni queste due tecniche sono state sviluppate due tecniche ibride di grande diffusione: la VM e la compilazione JIT.
La Virtual Machine e la compilazione JIT
Alcuni linguaggi (Java e i linguaggi .NET) hanno introdotto un meccanismo basato su un doppio passaggio.
In questi linguaggi il codice originale viene compilato tradizionalmente, ma il codice oggetto (e la build) non sono nel codice macchina del computer in cui sono stati compilati. Questo codice macchina (nel mondo Java si chiama bytecode, nel mondo .NET si chiama IL), è di una macchina speciale con una architettura predeterminata dai creatori del linguaggio. Questo codice per essere eseguito ha bisogno quindi di un runtime, che è un software che emula quella architettura: si tratta rispettivamente della JVM (Java Virtual Machine per Java), e del CLR (Common Language Runtime per .NET).
L’obiettivo è la portabilità: anzichè realizzare un compilatore specifico per ogni architettura, viene realizzato un compilatore generale e poi una macchina virtuale specifica, di più semplice realizzazione e compilazione. Nelle prime versioni della JVM (e del .NET framework) il codice macchina veniva quindi interpretato e si comportava quindi a tutti gli effetti come un linguaggio di scripting, con ovvie conseguenze sulle prestazioni, che erano deludenti e confinavano Java (e .NET) solo a specifiche applicazioni non “time critical”.
Nell’ultimo decennio tutte le JVM e i CLR si sono quindi evolute, ed hanno implementato una compilazione dell’applicazione da codice macchina virtuale a codice macchina reale. L’applicazione diventa quindi a tutti gli effetti una build con codice macchina nativo dell’architettura di esecuzione. Questa tecnica si chiama compilazione JIT (“Just in time”) e cerca di unire i vantaggi della portabilità a quelli delle prestazioni.
La compilazione JIT è oggi utilizzata su una vastità di linguaggi interpretati, ad esempio Javascript, e verrà introdotta anche in linguaggi di scripting come PHP.
Quadro riassuntivo dei principali linguaggi ad alto livello.