
Codifica digitale
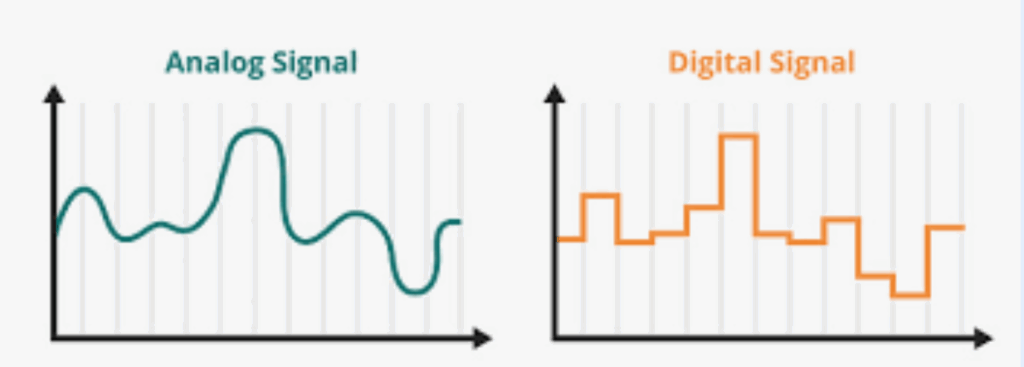
Alla base dei sistemi informatici c’è il concetto di digitale, parola in contrapposizione con analogico. Ma cosa significano digitale ed analogico?
Una conoscenza o sensazione analogica ha una forma “continua“: la nostra percezione sensoriale la percepisce come un “tutt’uno” e non quindi come un insieme di percezioni distinte. Ciò vuol dire che quando ad esempio il nostro occhio vede una scena come un paesaggio o una stanza, o il nostro orecchio percepisce un suono o della musica, queste sensazioni sono ricevute dal nostro cervello come un flusso continuo di segnali senza discontinuità al loro interno, il cui unico limite è la capacità dei sensi di percepirne sfumature e frequenze. Il nostro cervello è infatti analogico e percepisce, memorizza le informazioni come uniche entità in cui tutte le parti sono fuse insieme nello spazio e nel tempo. Quando quindi i nostri sensi vedono, sentono, odorano, gustano o toccano il nostro cervello riceve l’intera informazione in modo indiviso e con sfumature infinitesimali senza alcun tipo di discontinuità.
Nel digitale invece la conoscenza è divisa in tante piccole unità “discrete“, anche molto piccole, ma comunque discontinue tra loro. Il computer è una macchina digitale, quindi memorizza e invia segnali digitali, cioè composti da un un insieme di parti discrete, di tipo numerico, ovvero singoli dati numerici distinti tra loro. Se il loro numero è sufficientemente elevato per unità di spazio (es. immagini) o di tempo (es. audio) la nostra mente sarà in grado di percepirli come analogici. Ma è bene capire fin da subito che non lo sono. Il computer ha bisogno di “digitalizzare” l’informazione che riceve (attraverso periferiche come microfoni o telecamere), ed allo stesso modo questa informazione deve poi essere convertita in “analogico” (tramite schermi ed altoparlanti) quando ci viene restituita.
Sistema binario
Qualsiasi contenuto digitale che utilizza un computer, come le immagini, i video, l’audio, i testi è memorizzato, trasmesso ed elaborato sempre come una sequenza di numeri, che rappresentano le singole unità di informazione digitale.
Tuttavia il sistema di numerazione utilizzato nei computer non è quello decimale. I computer gestiscono i dati tramite il sistema di numerazione binario, ovvero tramite unità di memoria dette bit, che possono assumere solo il valore di 0 oppure 1.
Il motivo di questa scelta è dovuto al fatto che è molto più semplice ed economico memorizzare i numeri tramite due stati possibili, in una macchina elettronica dove questi due valori sono gestiti tramite due diverse tensioni elettriche.
Per rappresentare valori superiori a 1 il sistema binario usa più di un bit. Ad esempio per rappresentare il valore 2 abbiamo bisogno di 2 bit, con valore “10”, mentre 3 sarà “11”. Per memorizzare il valore 4 usiamo tre bit: “100” e così via come in questa tabella:
| Decimale | Binario |
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
| … |
Come si può vedere ogni volta che aggiungiamo un bit raddoppiamo i valori memorizzabili: con 1 bit sono 2, con 2 bit sono 4, con 3 bit 8, con 4 sono 16 e così via. La regola è che con N bit si possono memorizzare 2N valori. Il sistema binario non è altro che il sistema di numerazione a base 2.
Il principio di funzionamento dei sistemi di numerazione è infatti posizionale, anche nel sistema decimale. Ad esempio il valore 36143 è in realtà rappresentabile in questa forma:
3*104 + 6*103 + 1*102 + 4*101 + 3*100=3614310
Ovvero
| 4 | 3 | 2 | 1 | 0 | Base |
| 3 | 6 | 1 | 4 | 3 | 10 |
Se vogliamo rappresentare un numero in binario usiamo lo stesso sistema. Ad esempio il numero 10011 è rappresentabile in questa forma:
100112 = 1*24 + 0*23 + 0*22 + 1*21 + 1*20 = 1910
| 4 | 3 | 2 | 1 | 0 | Base |
| 1 | 0 | 0 | 1 | 1 | 2 |
E’ quindi possibile fare una conversione da una base all’altra. Qui una lezione di approfondimento.
L’altra unità fondamentale di misura della memoria è il byte. Esso è costituito da una sequenza di 8 bit, che rappresentano quindi 256 valori possibili. La memoria è normalmente quindi rappresentata in multipli di byte.
| byte | 8 bit -> 256 valori memorizzabili. | unità di misura fondamentale della memoria. |
| KiloByte (KB) | 1024 byte (210 byte) | documenti e testi |
| MegaByte (MB) | 1024 KB (220 byte) | immagini |
| GigaByte (GB) | 1024 MB (230 byte) | video |
| TeraByte (TB) | 1024 GB (240 byte) | memorie RAM e SSD |
| Petabyte (PB) | 1024 TB (250 byte) | grandi archivi dati su Internet |
Codifica dei testi
I testi sono documenti composti da sequenze di caratteri alfanumerici. Sono già per loro natura in qualche modo digitali (anche se il nostro cervello li memorizza in concetti ed informazioni con infinite sfumature). Nei computer ogni carattere è codificato come un numero e memorizzato in binario. Il più antico (ed ancora oggi utilizzato) sistema di codifica è il codice ASCII, che possiamo vedere qui sotto (si ringrazia https://www.pierolucarelli.it/codiciascii/Tabella%20ASCII%20strandard.htm)
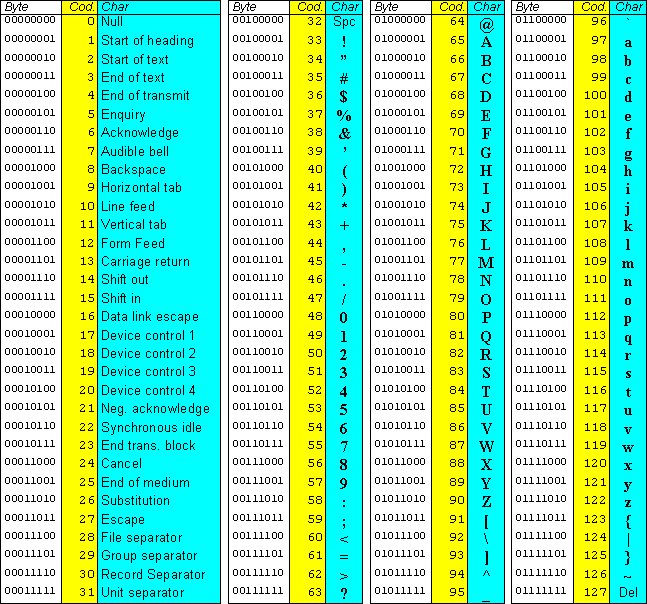
Nella sua versione originale ASCII usa 7 bit per rappresentare 128 caratteri, poi portata a 8 bit (un byte) con altri 128 caratteri per un totale di 256. Per decenni è stato il sistema principale di codifica dei caratteri ed è alla base di molti linguaggi di programmazione.
Tuttavia questo sistema riesce a malapena a rappresentare i caratteri latini, e non permette di memorizzare altre lingue (tedesco, arabo, cinese, cirillico, ecc.). Nel 1991 è stato quindi introdotto un nuovo sistema, Unicode, che rappresenta i caratteri usando 16 bit (2 byte) quindi 65536 caratteri. Successivamente i bit sono stati aumentati col tempo fino a 21 bit (circa 2 milioni di simboli). Tuttavia per rappresentare in digitale i caratteri Unicode si utilizza un sistema di codifica chiamato UTF, di cui esiste una variante a 8 bit (UTF-8, di fatto il codice ASCII) a 16 bit (UTF-16) o anche 24 e 32 (meno usate).
Immagini
Anche le immagini sono codificate digitalmente come sequenze numeriche (binarie). Una immagine digitale va pensata come una griglia di quadratini, detti pixel, dove ciascuno di essi memorizza una piccola porzione di immagine. Ipotizziamo per esempio di voler rappresentare la lettera “t” come immagine, essa potrebbe essere rappresentata così:
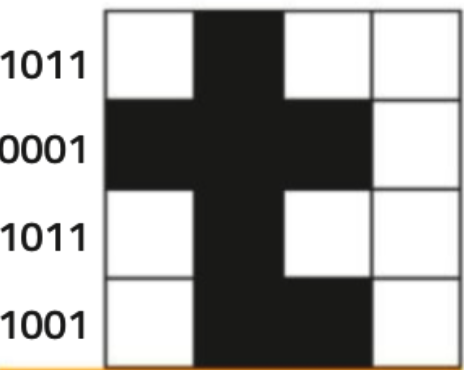
Ogni pixel bianco è 1, ed ogni pixel nero è 0. Se vista da vicino vediamo i pixel, ma da lontano “sembra” una immagine analogica.
Analogamente possiamo memorizzare una immagine in scala di grigi, dove ogni pixel memorizza un byte dove 0 è nero e 255 è bianco, coi valori intermedi che sono appunti i grigi sempre più chiari.

Ovviamente maggiore è la dimensione della griglia, maggiore è la dimensione dell’immagine, detta risoluzione, e più dettagliata la qualità della visualizzazione su uno schermo, fino al punto da non riuscire a distinguere i singoli pixel. Ma se guardiamo uno schermo, ad esempio dello smartphone, con una lente di ingrandimento, scopriamo che questo è costituito da una griglia di pixel.

In figura vediamo un ingrandimento proprio della parola pixel (fotografia dello schermo di un computer). Da vicino vediamo la griglia ma da lontano il nostro occhio è “ingannato” e ci sembrdddda una immagine analogica.
Le immagini però sono a colori. Per questa ragione di usa un sistema di codifica chiamato RGB (Red Green and Blue), dove ciascun colore è rappresentato da un codice per il rosso, uno per il verde ed uno per il blu (8 bit per ciascun colore, in totale quindi 24 bit ovvero 16 milioni di colori). Qui alcuni esempi di codifica di colori:
- Rosso: (255, 0, 0)
- Verde: (0, 255, 0)
- Blu: (0, 0, 255)
- Giallo: (255, 255, 0)
- Ciano: (0, 255, 255)
- Magenta: (255, 0, 255)
- Bianco: (255, 255, 255)
- Nero: (0, 0, 0)
Esiste anche uno standard esteso S-RGB (detto HDR) che arriva a 10 bit per colore cioè 30 bit (un miliardo di colori) utilizzato da schermi di ultima generazione, per gestire una maggiore profondità di sfumature di colore ed avvicinarsi alla sensibilità dell’occhio umano.
Il sensore di una fotocamera digitale è quindi composto da una griglia di microsensori (chiamati fotodiodi) che trasformano la luce in un segnale elettrico che viene poi trasformato in un valore numerico in base alla sua intensità e memorizzato come pixel digitale coi suoi colori e memorizzato nella memoria della fotocamera e quindi elaborabile da un computer.
Qui un elenco di dimensioni tipiche delle immagini digitali:
| Dimensione | Numero pixel (in MegaPixel) | Esempio |
| 1280×720 | 1MP | Fermo immagine di un video ad alta definizione |
| 1920×1080 | 2MP | Fermo immagine di un video di qualità Full HD |
| 3840×2160 | 8MP | Fermo immagine di un video 4K |
| 4000×3000 | 12MP | Immagine tipica da fotocamera di uno smartphone |
| 5472×3648 | 20MP | Immagine di fotocamera compatta di fascia alta |
| 6000×4000 | 24MP | Immagine tipica di fotocamera mirrorless anche professionale |
| 9504×6336 | 61MP | Immagine tipica di fotocamera mirrorless professionale |
Dimensione degli schermi e risoluzione
Per ottenere un effetto “analogico” i pixel devono essere sufficientemente piccoli da ingannare l’occhio umano. Questo effetto si ottiene aumentando la risoluzione dello schermo, ovvero il numero di pixel che compongono l’immagine, misurati come larghezza per altezza in pixel, il cui prodotto è il numero totale di pixel necessari.
L’aumento della dimensione delle immagini significa automaticamente un miglioramento della nitidezza dell’immagine? La risposta è no, perché entra in gioco la densità.
La densità misura il numero di pixel per pollice (si usa il sistema anglosassone) ovvero PPI. In generale quindi maggiore è il numero PPI, più piccoli saranno i pixel. Qui un esempio di schermi comuni coi loro PPI:
| Dispositivo | Schermo (“) | Risoluzione | PPI |
|---|---|---|---|
| iPhone SE (2022) | 4.7″ | 1334 × 750 | 326 PPI |
| iPhone 17 | 6.3″ | 2532 × 1170 | 460 PPI |
| Galaxy S24 | 6.2″ | 2340 × 1080 | 416 PPI |
| Galaxy S24 Ultra | 6.9″ | 3120 × 1440 | 496 PPI |
| iPad Air | 10.9″ | 2360 x 1640 | 264 PPI |
| Galaxy Tab S11 | 11″ | 2560 x 1600 | 270 PPI |
| Notebook HP | 15.6″ | 1920 x 1080 | 141 PPI |
| Notebook Asus | 14″ | 2880 x 1800 | 243 PPI |
| Macbook Pro | 14″ | 3024 x 1964 | 254 PPI |
| Monitor FHD | 24″ | 1920 x 1080 | 92 PPI |
| Monitor 4K | 27″ | 3840 x 2160 | 163 PPI |
| Monitor 4K | 32″ | 3840 x 2160 | 138 PPI |
| TV 4K | 55″ | 3840 x 2160 | 80 PPI |
Ma quindi su un TV 4K si vedranno di più i pixel rispetto ad un Samsung S25 Ultra? Si e no, perché in realtà conta anche la distanza: più si è lontani più i pixel sono indistinguibili.
E’ stato osservato tramite studi scientifici che una risoluzione di 300ppi a 25cm (la distanza tipica di uno smartphone) è sufficiente per rendere impossibile distinguere i singoli pixel anche per una persona con una vista perfetta. Una densità maggiore a 300PPI è del tutto inutile da quella distanza. Ad una distanza maggiore servono meno PPI, ad una distanza maggiore (ad esempio 10cm) servono più PPI.
Pertanto no, probabilmente il nostro TV in salotto da 55 pollici è sufficiente per una visione perfetta, perché non lo vediamo da 25 cm, ma da 3 metri.
Vediamo qui una procedura per calcolare, data una risoluzione dello schermo e la sua diagonale in pollici, qual è la distanza minima per una visione ottimale. Ipotizziamo per semplicità che lo schermo sia 16:9, la dimensione tipica di qualsiasi monitor o tv da tavolo (ma diversa da quella degli smartphone 20:9, pc 16:10 e tablet 4:3).
a. Dobbiamo prima di tutto calcolare la larghezza dello schermo in base alla diagonale, applicando il teorema di Pitagora.
- Teorema di Pitagora D2= L2+A2
- Prendiamo L= 16 e A= 9 quindi: D2= 162+92 = 256 + 81 = 337
- Rapporto larghezza diagonale: L/D = 16/√337 = 0.8716
- Siccome il rapporto non cambia all’aumento della diagonale: L = D * 0.8716
Ad esempio un 55 pollici avrà una larghezza di 47,9 pollici.
b. Calcoliamo i PPI, ovvero la risoluzione in larghezza diviso il numero dei pollici.
Il tv da 55 pollici 4k ha una larghezza di 3840 pixel che va divisa per 47,9 pollici. Che fa appunto circa 80PPI.
c. A questo punto applichiamo una proporzione
- Distanza minima (d) : 25 = PPI misurati : 300
- d = 25 * 300 : PPI = 7500 : PPI
Nel caso del 4k avremo quindi d = 7500 : 80 = 93cm
Siccome nessuno si siede a meno di 2 metri, 55 pollici 4k bastano eccome. Se facciamo i conti anche per contenuti FULL HD bastano circa 2 metri, mentre per contenuti HD bisogna stare ad almeno 3 metri.
Questo è il motivo per cui ad esempio anche le tv di fascia alta (ad esempio gli schermi OLED da 100 pollici) hanno una risoluzione non superiore al 4k perché la distanza di visualizzazione (con 100 pollici è di diversi metri) è tale da rendere in qualsiasi scenario reale impossibile vedere i pixel (a meno ovviamente di stare ovviamente attaccati allo schermo e girare la testa). Nei cinema la risoluzione non è più alta, anche perché il pubblico è di solito a decine di metri.
Torniamo alle immagini. Ma allora a cosa servono immagini così grandi da molti MP se tanto gli schermi sono al massimo 4K, cioè circa 8MP? In realtà sono utili prima di tutto per effettuare zoom per osservare dettagli, poi per poter eseguire ritagli ed infine per la stampa di grande dimensione dove invece 300PPI sono sempre necessari per stampe di alta qualità.
Quello della rappresentazione digitale delle immagini è un mondo affascinante, ma lasciamo l’approfondimento al lettore di questa ed altre tematiche e torniamo invece alla codifica digitale delle immagini.
Compressione
La dimensione delle immagini pone infatti un altro problema di natura tecnica, ovvero l’occupazione di memoria. Se sappiamo che ogni pixel di immagine richiede 24 bit RGB (cioè 3bytes) quanto occupano in memoria le immagini?
| Dimensione | Numero pixel (in MegaPixel) | Occupazione di memoria |
| 1280×720 | 1MP | 3MB |
| 1920×1080 | 2MP | 6MB |
| 3840×2160 | 8MP | 24MB |
| 4000×3000 | 12MP | 36MB |
| 5472×3648 | 20MP | 60MB |
| 6000×4000 | 24MP | 72MB |
| 9504×6336 | 61MP | 183MB |
E’ facile calcolare che ad esempio uno smartphone con memoria da 256GB potrebbe memorizzare appena 7500 immagini dello smartphone stesso (in realtà molto meno visto che serve spazio per sistema operativo, programmi ed altri dati). Il problema dell’eccessiva occupazione di spazio da parte di immagini può essere risolto riducendo la dimensione delle immagini, ma ovviamente si rischia di peggiorare la qualità e la nitidezza delle stesse, e quindi è una pratica che viene evitata.
La soluzione adottata è invece la compressione, un sistema che riduce la dimensione del file immagine (ma non dell’immagine stessa) memorizzandone una versione compressa, cioè che occupa meno spazio.
Esistono due tipi di compressione:
- lossless (senza perdita) come nel formato PNG, dove l’immagine viene elaborata cercando di accorpare informazioni di pixel identici (si pensi ad immagini con parti dello stesso colore). Con il lossless si riesce mediamente a dimezzare la dimensione dell’immagine.
- lossy (con perdita), come nel formato JPEG, dove l’immagine viene elaborata cercando di accorpare le informazioni di pixel anche non identici ma molto simili, eliminando parte dell’informazione, secondo un meccanismo sofisticato che analizza e riduce sfumature ed altre microcaratteristiche di dettaglio. Con JPEG si possono ottenere compressioni del 90% senza che l’utente si accorga della differenza di qualità.
Per questa ragione generalmente la maggior parte delle foto per usi non professionali sono memorizzate in formato JPEG. Per tornare all’esempio precedente, diventa possibile memorizzare su uno smartphone non più 7500 immagini, ma 75000 (sempre in linea teorica, perché lo spazio serve anche per altro). Non male.
Audio
Il principio su cui si basa l’audio digitale è quello del campionamento. In pratica il registratore digitale di un computer converte la vibrazione sonora su una membrana in un segnale elettrico che viene campionato (cioè letto e trasformato in valore digitale) con una certa frequenza. Maggiore la frequenza migliore la “somiglianza” del segnale digitale a quello analogico.
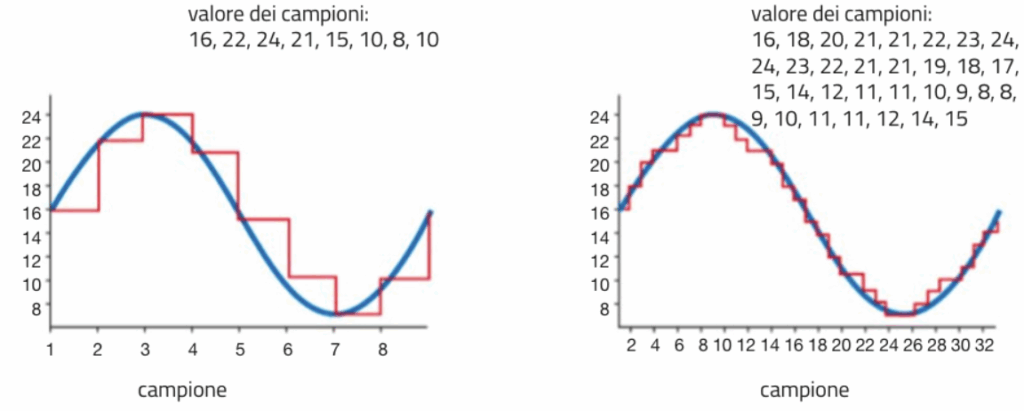
Anche qui valgono considerazioni simili a quelle delle immagini. Una eccessiva frequenza di campionamento non migliora la qualità del suono digitale, perché l’orecchio umano percepisce suoni fino ad una certa frequenza (circa 20 mila oscillazioni al secondo, dette Hertz). Un tipico campionamento viene quindi effettuato a 44,1khz per ottenere frequenze uditive fino a 22Khz (sevono due campionamenti per ogni oscillazione). Per ogni campionamento viene estratto un valore numerico binario, di solito nei campionamenti moderni di 16 bit (nell’audio professionale arriva a 24 bit).
Anche qui bisogna fare i conti con lo spazio occupato: un’ora di audio stereo occupa circa 600MB, un valore impensabile se vogliamo conservare nel nostro computer qualche migliaio di brani di musica. Per questo anche nella memorizzazione delle immagini si usa la compressione con perdita, tramite un algoritmo MPEG, che comprime il singolo campione sonoro eliminando frequenze non udibili ed altri microdettagli. Il formato MPEG più noto è il formato MP3, che consente di ottenere una qualità indistinguibile dall’originale con una compressione di circa 5 volte (da 600 a 120MB l’ora) ma volendo si può ottenere una qualità ancora ottima anche comprimendo 7-8 volte rispetto all’originale non compresso.
Video
I video sono sequenze di immagini (dette anche frame) proiettate in rapida successione che creano l’illusione di movimento, con un audio accoppiato sincronizzato. I video digitali sono la versione digitale dei video analogici. L’occhio umano, quando il numero di fotogrammi per secondo (fps) è sufficientemente alto, non percepisce più le singole immagini, ma percepisce direttamente un movimento continuo, tramite un effetto che si chiama “motion blur” (sfocatura di movimento).
Normalmente il flusso video tipico di un film o trasmissione TV varia dai 24 fps) (tipico del cinema) o 30 fps (TV). Tuttavia oggi le fotocamere (anche non troppo professionali) oggi sono in grado di registrare filmati a 60, 120 o addirittura 240fps. Maggiore il numero di fps migliore la fluidità percepita dal movimento.
Il problema è dato però ancora una volta dallo spazio occupato in memoria dei video, e per i video trasmessi in streaming su Internet, anche dalla velocità di connessione. Ad esempio un video FULL HD a 30fps richiede di inviare 30 immagini al secondo, che richiedono (partendo da JPEG) circa 1,8MB al secondo, una velocità sostenibile solo da una connessione in fibra ottica. Un video 4K richiede invece 7,2MB al secondo, velocità eccessiva per qualsiasi rete domestica (e spesso anche aziendale).
Per questa ragione è stata introdotta una nuova forma di compressione MPEG che consiste nell’inserire nel video frame contenenti non l’intera immagine ma solo la parte dell’immagine che cambia rispetto alla precedente. Ad esempio se stiamo vedendo una scena di un film in cui due protagonisti parlano, tra un fotogramma e l’altro si muoveranno solo le labbra ed il viso, quindi saranno solo queste porzioni dell’immagine che verranno inserite nei frame successivi al primo frame, che contiene tutta l’immagine. Periodicamente poi per non perdere troppa informazione, viene inserito un key frame intero. Questa tecnica si chiama motion compensation (da cui il termine MPEG, Motion Compensation Expert Group) e consente di ottenere compressioni di anche 10 volte rispetto ad un flusso video tradizionale (da 1,8MB al secondo diventano 180KB al secondo e 7,2MB al secondo diventano 720KB al secondo) anche se ovviamente la compressione dipende molto anche dal tipo di video, ad esempio un film d’azione con scene movimentate ha un’alta percentuale di movimento e verrà compresso meno, mentre un film di tipo teatrale è pià comprimibile. Naturalmente è possibile scegliere, come col JPEG e MP3 la quantità di compressione, ottenendo quindi maggiore o minore qualità.
Nella tabella seguente vedremo le velocità di connessione delle principali tipologie di trasmissione dati:
Trasmissione dati
Abbiamo visto che il mezzo di trasmissione dei dati in rete può essere via cavo (telefono, fibra, ADSL, o rete LAN) o senza cavo (Wifi, Rete cellulare, satellite). Anche le connessioni digitali alle periferiche possono essere con cavo (USB, HDMI) o senza (Bluetooth).
I dati sono trasmessi digitalmente anche nelle reti di computer, tramite router (che connettono reti di computer) e su mezzi diversi con dispositivi come i modem (che consentono di trasmettere e ricevere comunicazioni digitali su diversi canali di trasmissione, come la rete telefonica cablata o senza filo), o dispositivi analoghi ma specifici per la fibra ottica e il satellite, che svolgono le stesse funzioni del modem.
In sintesi, ogni trasmissione digitale avviene tramite un mezzo fisico (cablato o meno) in cui il dato digitale (binario) viene convertito in una qualche forma di comunicazione analogica:
- un segnale radio per Wifi, Bluetoth, Satellite e Rete cellulare;
- un segnale elettrico per LAN (Ethernet), rete telefonica ed ADSL;
- una segnale ottico per la fibra ottica
Questo segnale viene poi ricevuto dal destinatario, che lo converte di nuovo in dato digitale ricostruendo il messaggio originale.
Esiste una materia specifica, l’ingegneria per le telecomunicazioni, che si occupa proprio di studiare le comunicazioni digitali ed analogiche, la scienza e le tecnologie che ne sono alla base.
La velocità di trasmissione è la più importante grandezza che misura le prestazioni di una trasmissione, ma non è l’unica, ad esempio è importante anche il tempo di risposta detta anche latenza (utile per esempio nei videogiochi in tempo reale), e lo è altrettanto anche la capacità di banda (cioè quanti dati si possono mandare contemporaneamente, dato che viene molto pubblicizzato dalle compagnie telefoniche).
La velocità resta comunque una grandezza essenziale, perché è quella che ci permette di capire le prestazioni effettive di un sistema di comunicazione digitale.
| Tecnologia | Velocità Teorica Massima (Mbit/s) | Velocità Reale Media (Mbit/s) | Note principali |
|---|---|---|---|
| USB 2.0 | 480 | 240–320 | Ancora usato per periferiche base (mouse, tastiere, chiavette) |
| USB 3.0 / 3.1 Gen1 | 5000 | 2400–3200 | Diffuso su PC e dischi esterni |
| USB 3.2 Gen2 | 10000 | 5600–7200 | Supporta cavi di alta qualità |
| Wi-Fi 4 | 600 | 50–150 | Ancora comune in router economici |
| Wi-Fi 5 | 3500 | 300–800 | Standard molto diffuso |
| Wi-Fi 6 | 9600 | 600–1200 | Maggiore efficienza e latenza ridotta |
| Wi-Fi 7 | 30000 | 1000–5000 | Standard emergente, ottimo per gaming |
| Bluetooth 4.2 | 1 | 0,3–0,8 | Ideale per audio e periferiche |
| Bluetooth 5.0 / 5.3 | 2 | 0,8–2 | Maggior raggio e qualità, standard emergente |
| Ethernet | 100 | 90–95 | Ancora presente in buona parte delle reti aziendali (es scuole) |
| Ethernet (Gigabit) | 1000 | 900–950 | Standard moderno di riferimento |
| ADSL2+ | 24 ↓ / 1,4 ↑ | 8–15 ↓ / 0,8–1 ↑ | Usa doppino telefonico, nelle zone non coperte da fibra. |
| VDSL2 (FTTC) | 100 ↓ / 20 ↑ | 50–90 ↓ / 10–20 ↑ | Rete mista rame/fibra, dove la fibra non arriva a casa. |
| Fibra FTTH | 2500 ↓ / 500 ↑ | 800–1200 ↓ / 300–400 ↑ | Fibra ottica fino a casa |
| 4G | 300–1000 | 50–200 | Dipende da copertura e frequenze |
| 5G | 1000–3000 | 300–800 | Ampia copertura, bassa latenza |
| Connessione Satellitare (Starlink, ecc.) | 150–250 ↓ / 20–40 ↑ | 100–200 ↓ / 15–30 ↑ | Alta latenza (30–60 ms), utile in zone rurali |
Conclusioni
I dati di qualsiasi tipo sono codificati nei computer come sequenze digitali numeriche memorizzate come numeri binari. Testi, immagini, suoni e video sono quindi trasformati tramite speciali codifiche e memorizzati quindi come sequenze binarie e riconvertite per la loro fruizione da parte dell’utente.
Per immagini audio e video gioca un ruolo importante la compressione, soprattutto lossy, che consente di risparmiare spazio nelle memorie e rende possibile la trasmissione in tempi sostenibili dei dati nella rete Internet.