
Ciclo di sviluppo
Ora che abbiamo una idea di cosa sia la programmazione e dei suoi principali paradigmi, proviamo a capire in cosa consiste la fase di codifica effettiva di un programma per computer ovvero il ciclo di sviluppo.
Fasi di codifica ed esecuzione
L’attività di sviluppo consiste in due fasi alternate tra loro: la codifica del codice, e la sua esecuzione.
Durante la codifica il programmatore scrive il codice su un editor di testo, e nel farlo svolge una attività di tipo astratto e concettuale. Infatti definisce delle variabili, progetta un flusso del programma, fa delle ipotesi sui tipi di dati da utilizzare e restituire, ecc. Il risultato è scritto sotto forma di un codice formale fatto di istruzioni e simboli.
Non ha modo, però, mentre scrive il codice, di avere la certezza che quello che sta facendo è corretto. Fino a quando non viene eseguito il programma non si può verificarne il comportamento e quindi capire se ci sono errori nella sua progettazione e/o nello sviluppo. La scrittura di codice alla fine si riduce sempre alla scrittura di file di testo e non si ha modo di sapere se il programma funziona.
Per capirlo è necessaria l’esecuzione del programma. In questa fase l’elaboratore crea un processo di esecuzione ed il programma comincia a ricevere gli input, valorizza le variabili, esegue le istruzioni, accede alle risorse, ec. permettendo la verifica di quanto scritto in codifica.
Tuttavia non c’è modo, fino a quando si è in esecuzione, di modificare il codice mentre si è in esecuzione.
Dutante l’esecuzione il programma diventa una “scatola nera” (blackbox in inglese) che consente di vedere cosa sta facendo il computer ma non permette di intervenire immediatamente sul codice in caso di problemi. Il programmatore deve quindi prendere nota del comportamento, capire cosa va e cosa non va. Nel caso ci sia un errore deve capire cosa non ha funzionato, e poi modificare il codice per sistemare problemi o effettuare migliorie, dove però torna a lavorare in astratto e per formalismi.
Per capire bene facciamo un esempio, scriviamo un programma che richiede due numeri e calcola il risultato della divisione.
#include <iostream>
using namespace std;
int main() {
int numeratore, denominatore;
cout << "Inserisci il numeratore: ";
cin >> numeratore;
cout << "Inserisci il denominatore: ";
cin >> denominatore;
int risultato = numeratore / denominatore;
cout << "Il risultato è: " << risultato << endl;
return 0;
}Almeno in astratto, il programma sembra corretto. Il programmatore infatti
- definisce due variabili numeratore e denominatore;
- le richiede all’utente con le istruzioni corrette;
- calcola il risultato della divisione;
- stampa il risultato
Ma sarà veramente così?
In effetti alla prima esecuzione il programmatore testa con i valori 6 e 3 ed effettivamente ottiene 2. Ma si rende conto che questo programma ha una limitazione, non consente la divisione decimale, infatti 6 diviso 4 restituisce 1 e non 1,5. Quindi modifica il programma nel seguente modo:
#include <iostream>
using namespace std;
int main() {
float numeratore, denominatore;
cout << "Inserisci il numeratore: ";
cin >> numeratore;
cout << "Inserisci il denominatore: ";
cin >> denominatore;
float risultato = numeratore / denominatore;
cout << "Il risultato è: " << risultato << endl;
return 0;
}Stavolta il programma gestisce anche la divisione decimale. Ma allora funziona sempre? No. Ha dimenticato la divisione per 0, infatti in questo caso se mettesse 6 e 0, otterrebbe un errore di calcolo.
Deve necessariamente mettere un qualche tipo di controllo.
#include <iostream>
using namespace std;
int main() {
float numeratore = 0, denominatore;
cout << "Inserisci il numeratore: ";
cin >> numeratore;
while (denominatore == 0) {
cout << "Inserisci il denominatore: ";
cin >> denominatore;
}
float risultato = numeratore / denominatore;
cout << "Il risultato è: " << risultato << endl;
return 0;
}In questo caso inserisce un ciclo di controllo che consente di non avere mai errori di divisione per 0.
In un progetto reale, con tante variabili ed algoritmi complessi, possono essere molti gli errori di questo tipo, e per quanto un programmatore con l’esperienza impari a minimizzare gli errori, non ha mai la certezza in fase di codifica che tutto funzionerà correttamente. La programmazione è una operazione astratta e solo l’esecuzione garantisce che effettivamente l’idea si può oncretizzare.
La programmazione è in sostanza quindi una alternanza di fasi di codifica-esecuzione in cui lo sviluppatore scrive codice, poi esegue un test, sistema gli errori, testa di nuovo e così via in un insieme di cicli di di aggiunta e perfezionamento fino a quando non ottiene il risultato ottenuto.
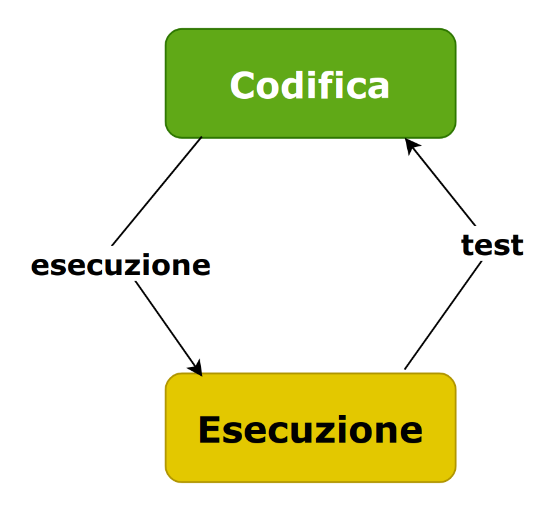
Riassumendo:
A compile time il programmatore analizza e scrive il codice sulla base di modelli, algoritmi ed ipotesi. In questa fase la programmazione è un processo astratto che è solo frutto di un ragionamento del programmatore che fa uso esclusivamente di simboli e formalismi.
A runtime il codice viene eseguito e diventa un processo concreto che trasforma il codice in istruzioni effettivamente eseguite ma dove entrano in gioco due nuovi elementi:
- il contesto di esecuzione, cioè la macchina reale dove il software viene eseguito, con le sue risorse di cpu, memoria e periferiche. L’hardware di esecuzione conta perché lo stesso programma potrebbe funzionare solo con certe risorse (es. ram, connessione ad internet, ecc.).
- i dati: una applicazione per funzionare ha bisogno di dati. Come visto nell’esempio iniziale, una ipotesi sbagliata sui dati può fare credere che un programma funzioni, salvo poi scoprire che non si è scelto accuratamente di testare il software con insiemi di dati differenti, come per esempio nella divisione per 0, costringendo a riscrivere il programma.
A runtime la programmazione diventa un concetto concreto dove tutte le astrazioni le ipotesi ed i ragionamenti vengono effettivamente verificati e messi in pratica, ma dove il programmatore non ha modo di mettere mano al codice.
Debugging
Tuttavia la maggior parte dei lingugaggi di programmazione prevede una modalità “debugging”.
Il debugger è uno strumento che permette una modalità di esecuzione speciale che rimuove una parte della black box, perché consente al programmatore di fermare l’esecuzione in un punto preciso, detto breakpoint e vedere, ad esecuzione interrotta, il valore delle variabili, lo stato della memoria e lo stack. E’ poi possibile eseguire le istruzioni una alla volta e vedere come queste variabili vengono modificate dalle istruzioni. In questa modalità di debug è quindi possibile vedere nel dettaglio qual è l’istruzione “colpevole” dell’errore o se l’esecuzione entra correttamente in una condizione o un ciclo viene correttamente eseguito.
Il debug non ci consente di modificare al volo il codice (ad ogni modifica bisogna riavviare) ma almeno consente di vedere cosa succede passo passo, funzione utile nei programmi più complessi.
Build time
In realtà tra compile time e runtime è presente una fase intermedia, detta build time. In questa fase il codice realizzato viene trasformato in codice eseguibile e viene predisposta l’applicazione che sarà eseguita a runtime. Il codice, le funzioni di libreria utilizzate, le configurazioni usate e tutte le altre risorse necessarie per il funzionamento del programma vengono accorpate in un unico pacchetto pronto ad essere eseguito.
A seconda della tipologia di linguaggio, sono previste due tecniche tra loro alternative: la compilazione o l’interpretazione.
Compilazione
Nella compilazione il codice dell’applicazione (detto codice sorgente) viene analizzato da un software detto compilatore che lo traduce in istruzioni e simboli di codice binario eseguibile. La compilazione viene effettuata una volta soltanto e produce un file detto oggetto. Se sono presenti errori, il compilatore li rileva e li segnala al programmatore, interrompendo l’operazione. Il compilatore quindi effettua una validazione del codice sorgente.
Il compilatore deve essere specifico per l’architettura hardware dove verrà eseguito il codice. Quindi lo stesso programma dovrà essere compilato separatamente per ogni piattaforma (es. Windows, Linux, ecc.).
Il codice oggetto però non è sufficiente. Per essere eseguito un programma ha bisogno di utilizzare un insieme di librerie esterne per accedere a determinate risorse (ad esempio per scrivere su file, per accedere alla rete, ecc.), librerie che a compile time sono indicate dal programmatore ma che poi è necessario includere nell’applicativo finale. E’ prevista quindi una operazione chiamata linking, che consiste nel creare un pacchetto contenente sia il codice oggetto che le librerie. Il risultato viene chiamato build, ed assume la forma di una applicazione eseguibile (un file .exe, una app mobile, un eseguibile per server, ecc.).
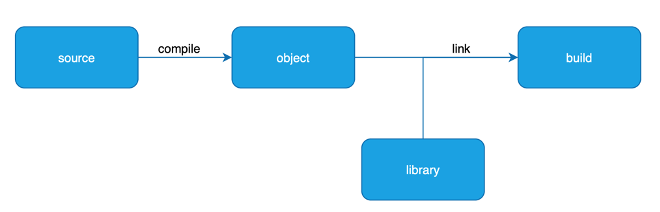
I compilatori odierni sono estremamente efficienti e riescono ad ottenere codice macchina che ha prestazioni quasi identiche a quelle che si avrebbero con un programma scritto direttamente in assembly. Ad esempio i linguaggi come C, C++ e Swift sono compilati.
Interpretazione
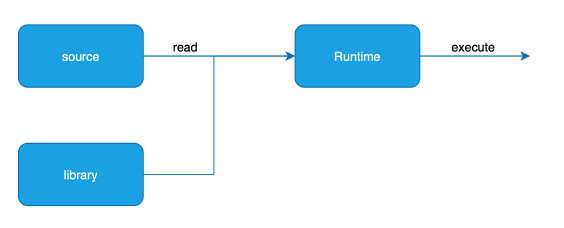
L’interpretazione è una modalità alternativa per cui il programma non viene compilato ma viene eseguito. Nei linguaggi interpretati è presente un software, detto runtime, che crea un ambiente di esecuzione per il programma e al suo interno prevede un interprete che legge il codice una riga alla volta e lo esegue nel runtime, memorizzando le variabili, eseguendo le operazioni di input/output, ecc. Se sono presenti errori, l’esecuzione si interrompe e viene segnalato l’errore all’utente (alcuni interpreti fanno una pre-analisi del codice per verificare che non ci siano errori prima dell’esecuzione).
Se un programma utilizza librerie esterne (le librerie interne sono già presenti nel runtime), può essere necessario preparare prima un pacchetto build di sorgenti (una specie di linking di codice sorgente), che contiene tutto il codice che dovrà essere eseguito.
L’esecuzione di codice interpretato può essere eseguito in qualsiasi ambiente sia previsto un runtime, senza una fase di build specifica per una determinata macchina. Questo significa però che prima di tutto bisogna installare il runtime, e poi anche avere prestazioni inferiori, perchè l’interpretazione del codice e la sua esecuzione avvengono in tempo reale e sono quindi più lente di una compilazione preliminare. Esempi di linguaggi interpretati sono Python e Javascript.
La Virtual Machine e la compilazione JIT
Alcuni linguaggi (come Java e C#) hanno un processo di build ibrido.
Con questa tecnologia il codice originale viene compilato in un linguaggio macchina speciale, detto Bytecode in Java e IL in .NET. Questo codice macchina è poi eseguito da un runtime speciale chiamato JVM Java Virtual Machine per Java o CLR Common Languare Runtime per .NET). E’ quindi necessario installare questo runtime, anche se spesso già preinstallata col sistema operativo.
L’obiettivo è unire i vantaggi della compilazione (un solo eseguibile) e dell’interpretazione (esecuzione multipiattaforma) con però lo svantaggio di prestazioni non elevate. Questo limite è stato però ben presto superato con un meccanismo chiamato compilazione Just in Time (JIT) che compila il codice in vero codice binario nativo della macchina su cui viene eseguito.
La compilazione JIT è stata poi estesa anche a molti linguaggi interpretati, in particolare su Javascript, che offre oggi prestazioni simili a quelle di un programma compilato.
Build e validazione
In fase di build è prevista, per la maggior parte dei linguaggi una fase di prevalidazione del codice, tramite strumenti di verifica formale che controllano la sintassi. La validazione ha un grande ruolo perché aiuta il programmatore sia a verificare che non ci siano errori di sintassi che i sorgenti e le librerie siano corrette, e con gli strumenti giusti, anche a verificare staticamente il codice, per esempio per condizioni che non possono verificarsi o cicli che non hanno via di uscita.
La validazione offre grandi vantaggi al programmatore perché consente, prima dell’esecuzione, di usare automatismi per verificare la correttezza formale del codice, mediante anche meccanismi molto sofisticati. Molti linguaggi moderni di programmazione, in particolare i linguaggi compilati, introducono un insieme di strumenti di verifica del codice a build time:
- tipizzazione “forte“: una variabile è sempre assegnabile solo ad un tipo di dato, questo impedisce erroneamente di assegnare una variabile ad un valore di tipo diverso;
- controllo automatico di variabili con valore nullo: impediscono mentre si scrive codice un errore molto comune in programmazione, quello di elaborare una espressione dove ci sono variabili non assegnate; (presente solo in Kotlin e Swift)
- modificatori di accesso alle variabili: alcune variabili sono inaccessibili in alcune parti del programma, questo impedisce di scrivere dove non si dovrebbe;
- introduzione di vincoli nel passaggio di parametri di funzioni: una funzione chiamata nel modo sbagliato viene considerata un errore prima dell’esecuzione.
- contratti (interfacce) nella programmazione ad oggetti: il programmatore viene avvertito su cosa può fare o non fare un altro oggetto.
- gestione automatica della memoria: non è possibile un accesso diretto alla memoria, così da evitare di creare variabili dimenticandosi di cancellarle quando non si usano più (non presente in C/C++)
Tuttavia la correttezza formale non garantisce la correttezza sostanziale. Potrebbero comunque esserci errori visibili solo in esecuzione, dovuti a errori concettuali o a errori di configurazione, librerie o altri elementi concreti non immediatamente rappresentabili in fase di codifica. Ad esempio potremmo cercare di aprire un file che non esiste, o cercare di usare una variabile non ancora valorizzata.
IDE
Un IDE è una applicazione realizzata per fornire al programmatore tutti gli strumenti necessari per lo sviluppo a compile time,
- un editor di testo che permette di scrivere il codice, con funzioni di evidenziazione di variabili, parole chiave ed errori di sintassi. E’ inoltre possibile avere funzioni di autocompletamento di istruzioni e variabili.
- un accesso rapido al compilatore o interprete tramite scorciatoie di tasti.
- l’IDE ha un debugger integrato che consente di inserire i breakpoint e visualizzare le variabili.
- permette di progettare interfacce grafiche e visuali.
- consente per alcune tecnologie di realizzare già uno schema del progetto senza scrivere il codice iniziale.
- ha tutti gli strumenti necessari per il deploy.
I due IDE oggi più diffusi sono IntelliJ (pensato in particolare per le applicazioni Java o linguaggi di quella famiglia, ma supporta anche Javascript, PHP e Python) e Visual Studio Code (pensato per Javascript, ma che supporta quasi tutti i linguaggi di programmazione tramite plugin).
Altri IDE particolarmente diffusi ma specifici per alcune tecnologie sono Visual Studio (progettato per applicazioni .NET su Windows), XCode (IDE per realizzare applicazioni per dispositivi Apple), Android Studio (variante di IntelliJ per il solo sviluppo per Android) e JavaBeans (per sole applicazioni Java).
Sono presenti anche molti strumenti di sviluppo basati su Web, come Colab Notebooks (per Python, non è un vero e proprio IDE ma consente di creare progetti e testare programmi) e Github codespaces (basato su VS Code).
Conclusioni
Qui viene rappresentato quindi tutto il ciclo di sviluppo, che si compone quindi di un insieme di cicli di codifica, build, esecuzione e debug fino a quando il programma (o una sua parte) si può considerare corretta. A sviluppo completato si procede col rilascio (deploy), ovvero quell’insieme di attività che hanno come obiettivo l’installazione del software nella macchina dove sarà eseguito dagli utenti e poi alla realizzazione della funzionalità successiva.
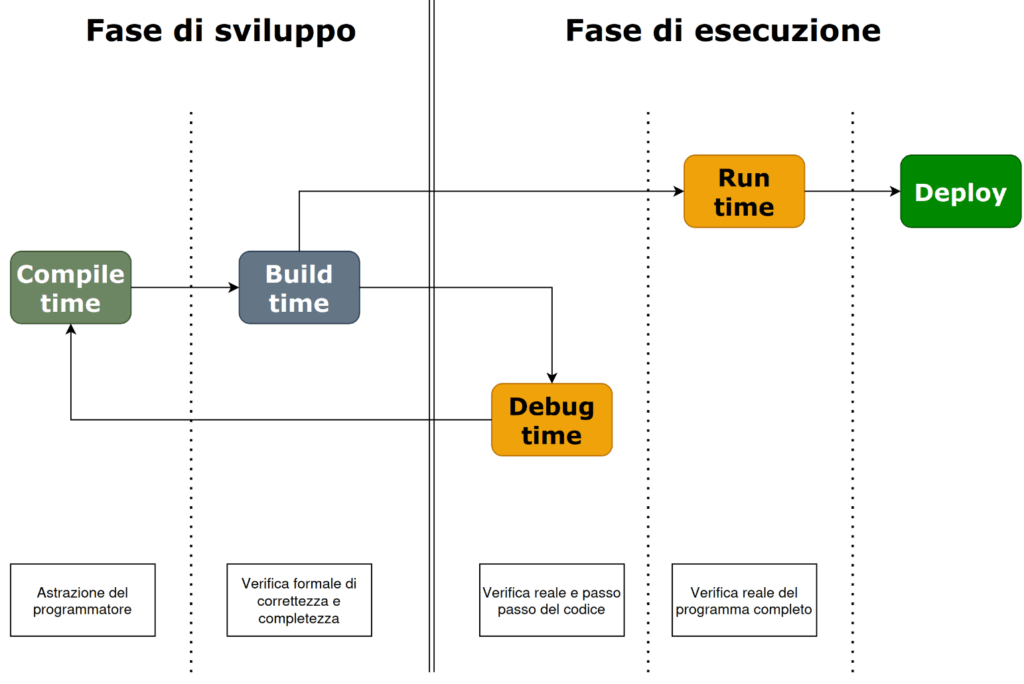
Nello sviluppo di software è sempre fondamentale tenere a mente queste fasi, e cosa è possibile fare in ciascuna di esse e quali cose è possibile fare dopo.
Il programmatore deve quindi sfruttare le particolarità di ogni fase, favorendo la massima astrazione nella fase di codifica, e la massima concretezza nella fase di esecuzione. Inoltre questo tipo di scelte ovviamente condiziona anche scelte tecnologie, come la tipologia di linguaggio, come vedremo nelle prossime lezioni.