
Git
Git è un software che ha lo scopo di gestire lo storico delle modifiche in una cartella del filesyste, intese come aggiunte, modifiche, eliminazioni di file o cartelle.
Grazie a git è possibile:
- salvare lo stato corrente della cartella (backup)
- tornare ad uno stato precedente (restore) tra quelli salvati
- sincronizzare i file della cartella con altre persone
ed altre funzioni ancora più avanzate. Sebbene sia un software generico che non ha conoscenza di cosa sta gestendo, git è ottimizzato per gestire file di testo e quindi soprattutto codice e progetti software, anche se il funzionamento è garantito per qualsiasi file.
Git è un programma da linea di comando e funziona su windows, linux e mac. Sono comunque presenti dei tool visuali.
Concetti fondamentali
Stato di un file
Git utilizza un database interno per gestire le modifiche, chiamato repository. Un repository può essere creato da zero (init) o tramite duplicazione di un repository remoto esistente (clone). Ogni volta che vogliamo salvare lo stato del repository eseguiamo una commit, una specie di fotografia della situazione corrente.
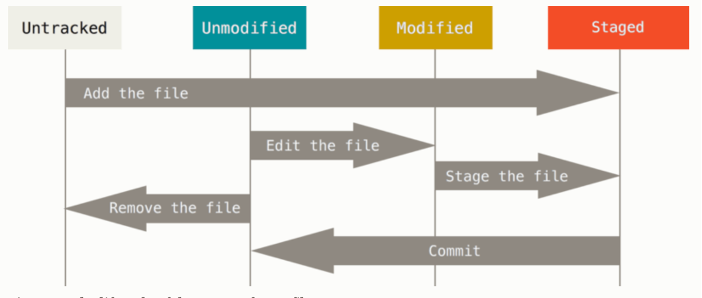
Nel momento in cui un repository è attivo, git tiene traccia delle modifiche dei singoli files. Un file può avere uno dei seguenti stati
- untracked: stato iniziale di un file che ancora non è stato tracciato.
- unmodified: è lo stato di un file dopo che è stata fatta una commit che lo comprende.
- modified: un file modificato dopo la sua ultima commit.
- staged: un file aggiunto per essere inserito nella prossima commit. Può essere un file già stato oggetto di commit, oppure un file appena aggiunto.
Qui uno schema che mostra le transizioni da uno stato all’altro.
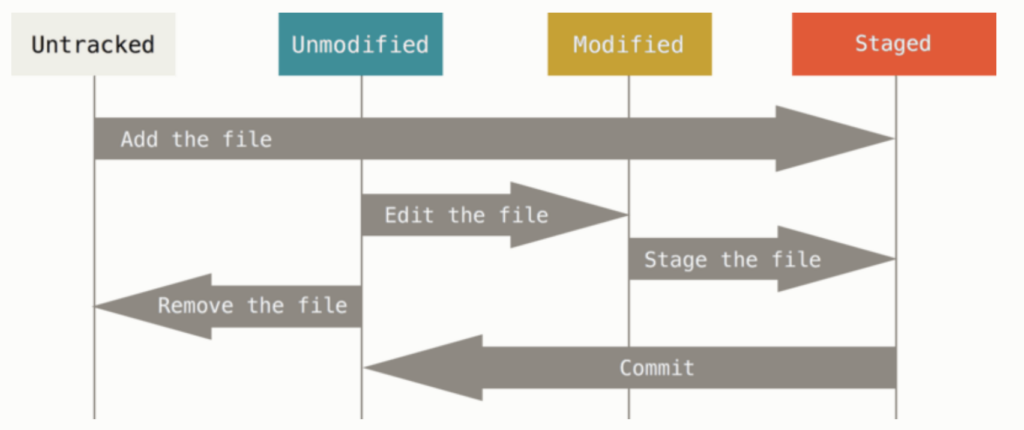
E’ possibile vedere lo stato con il comando status, che mostra la cartella corrente indicando quali file sono non tracciati, modificati e in staged. E’ poi presente la possibilità che un file sia in stato ignored, cioè non tracciato da git. Non è il comportamento di default: come vedremo per ignorare un file bisognerà configurare git apposta, il gitignore.
Commit
La commit non salva una copia nuova del file, ma quando possibile (nei file di testo) nel salvataggio delle sole modifiche (differenze) rispetto alla versione precedente.
Ad esempio se creiamo un file testo.txt ed eseguiamo le seguenti operazioni:
1) inserire una riga di testo “testo 1”, add e poi commit
2) inserire una riga di testo “testo 2”, add e poi commit
3) inserire una riga di testo “testo 3”, add e poi commit
Ogni commit memorizzerà solo la riga di testo aggiunta.
Questo sistema rende possibile rendere indipendenti le modifiche. Questo rende possibile la fusione di commit per la sincronizzazione tra più utenti e repository che hanno agito su parti diverse della cartella o anche dello stesso file, e semplifica inoltre il rollback (tornare indietro ad una versione precedente) tramite l’eliminazione di una commit o più commit, perchè la commit salva solo la differenza tra due stati del filesystem. Vuol dire che possiamo anche applicare una commit o più commit a qualsiasi file, e quindi salvare solo alcune modifiche di un file.
La commit è associata a:
- un codice hash che ne costituisce l’identificativo, calcolato dalle modifiche. Due modifiche identiche avranno lo stesso hash.
- un autore: git è pensato per essere multiutente;
- una data.
Le commit sono memorizzate in modo indipendente nel database, e associate alla history del repository mediante data. Si può vedere lo storico delle commit con git log. Questo rende quindi possibile riordinare le commit opportunamente quando desiderato (e quindi modificare l’ordine delle modifiche).
L’ultima commit è chiamata anche HEAD.
Si puo ‘anche eliminare una o piu’ commit semplicemente spostando la head (reset).
Un repository git è quindi proprio come un ” film” dove le commit sono i fotogrammi, e dove è quindi possibile tagliare e cucire parti della history.

Repository server
Con git è possibile sincronizzare due repository. Si possono condividere direttamente, ma il sistema usato per la maggior parte dei progetti è quello di avere un repository server e poi uno i per ogni pc di ogni developer. Ogni volta che uno sviluppatore deve condividere con gli altri le proprie modifiche le invia al server, e tutti gli altri le scaricano dal server.
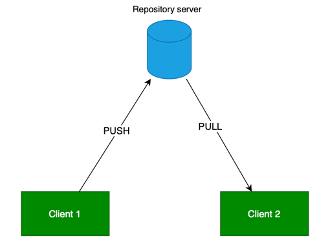
Per sincronizzare sono previste due operazioni:
–push: invia le proprie commit nuove al server
–pull: riceve le commit nuove dal server git capisce da solo le commit nuove.
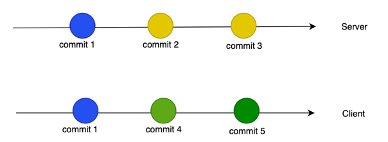
Qui ad esempio vediamo una situazione in cui nel server ci sono le commit 1,2,3 sul client le commit 1,4,5.
A questo punto il client esegue la push. Il server capisce che la commit 1 è già presente ed aggiunge le commit 4 e 5. Come si vede sono applicate DOPO le commit 2 e 3 perchè eseguite dopo.
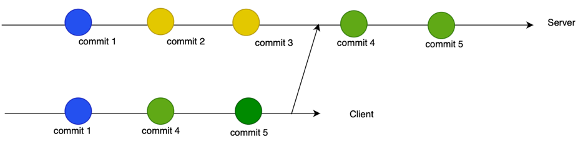
L’operazione di aggiunta di commit su un altro repository (o branch) viene chiamata merge. Per sincronizzare due utenti quindi normalmente fanno sincronizzazione col server a turno (pull e poi push) fino a quando entrambi non hanno eseguito il merge dei propri repository locali.
Git cerca di fare merge in modo automatico ma in caso di conflitti (file modificati da due commit diverse di due utenti diversi) è necessario risolvere i conflitti modificando a mano tutti i files in conflitto.
.gitignore
Poichè non tutti i files di un progetto devono essere memorizzati su git (normalmente di tutti i deliverable sono esclusi i file di libreria, eventuali file temporanei o altro ancora), è possibile definire alcune esclusioni in un file speciale detto .gitignore. E’ possibile aggiungere singoli files, cartelle e wildcard. In gitignore vanno principalmente:
- file di configurazione;
- asset;
- librerie
Ovvero tutti quegli oggetti che fanno parte della build, ma non della codebase.
Guida avanzata di git
Contesto
Nell’ambito dello sviluppo e la progettazione di applicazioni, lo sviluppatore con l’aumento della complessità dei progetti si trova di fronte alla necessità di realizzare software che girerà su più ambienti di sviluppo su macchine diverse. Inoltre nei progetti più grandi non si lavora individualmente ma con altri programmatori e nasce l’esigenza di dover gestire la possibilità di sincronizzare codice sorgente. Infine può essere necessario gestire contemporaneamente più linee di sviluppo, una per ogni versione del software. Tutto questo fa parte delle attività cosiddette di DevOps, che si occupano di dover gestire, in modo pratico, le seguenti attività:
- Attività di rilascio (cioè compilazione, linking, pacchettizzazione e deploy), anche automatizzate tramite processi di Continuous Integration e Continuous Delivery;
- configurazione delle proprie applicazioni per funzionare in contesti differenti (ad esempio in un’altra rete, con un database diverso, ecc.), compresa la configurazione e la virtualizzazione/containerizzazione degli ambienti;
- una gestione avanzata dei files sorgente del proprio progetto, che permetta di tornare indietro nelle attività di sviluppo, fare backup, collaborare e gestire versioni del software.
Git è un software che copre proprio il terzo punto sopra indicato.
Cos’è git?
Git è un software per la gestione e la sincronizzazione della history di file in particolare di testo, sorgenti software ma non solo.
L’obiettivo di git è tenere traccia delle modifiche che avvengono in una cartella e nelle sue sottocartelle (questa porzione del filesystem viene chiamata repository) tramite la creazione di istantanee (snapshot dette amche commit) della situazione corrente.
Rende possibili quindi le seguenti azioni:
– tornare indietro ad uno snapshot precedente (detto revert) anche di singoli files;
– creare una history parallela rispetto ad un’altra, eseguirvi all’interno un insieme di modifiche (branching);
– eseguire la fusione di due history tra loro (merging);
– sincronizzare più repository su macchine remote (pull e push).
Git è un software progettato da Linus Torvalds nel 2005, per riuscire a risolvere il problema del mantenimento della codebase del kernel di Linux. L’obiettivo di Torvalds era quello di risolvere una volta per tutte tutte le problematiche sopra indicate: backup, revert, parallelizzazione, rilasci, ecc., problemi che parzialmente affliggevano altri prodotti per la gestione dei sorgenti presenti già sul mercato, come ad esempio Subversion, che eera in grado di gestire solo limitatamente le azioni suddette (specie il merging).
Oggi git è praticamente l’unico software che svolge questa attività, ed è adottato ed utilizzabile per qualsiasi tipo di progetto in ogni tipo di attività. E’ di fatto lo standard di mercato della gestione del software, ed un requisito fondamentale di competenza per qualsiasi programmatore.
Come funziona git
Ogni volta che viene creato un nuovo snapshot (commit), git crea una immagine di tutti i files modificati e ne conserva un riferimento, tramite la creazione di un hash della modifica stessa. La history di commit cè quindi una “storia” di istantanee della situazione del filesystem al momento della commit. Una history git va quindi vista come un “film” dove gli snapshot sono i fotogrammi. Come nei film è perciò possibile “tagliare” e “cucire” le commit.
In git esiste un branch iniziale sul quale è possibile eseguire le commit, ma a partire da ciascuna di queste è possibile creare un nuovo branch: un branch è il riferimento ad un insieme di commit che vengono effettuate in parallelo rispetto ad altri branch. Git quindi tiene traccia di tutti i branch attivi, cioè di tutte le history parallele. Il vantaggio di questo sistema è che permette di lavorare in contemporanea su più feature differenti (o si più bugfix contemproanei) senza toccare il lavoro già svolto, attività questa fondamentale quando si collabora tra più programmatori e/o si stanno svolgendo più attività che non si devono mischiare tra loro.
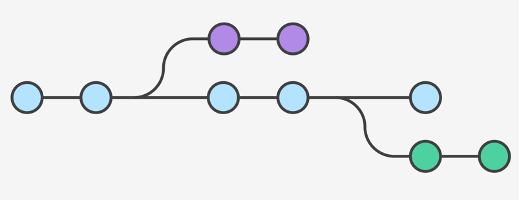
Git identifica (firma) ogni commit con un hash di tipo checksum con l’algoritmo SHA-1, e questo diventa il riferimento a quella commit nel database interno di git. E’ anche possibile taggare le commit con nomi più facili da ricordare (per ricordare ad esempio versioni).
Siccome ogni commit git aggiunge tutti i files modificati e il loro hash nel proprio database, con git è impossibile perdere dati. Nella figura un esempio di commits.
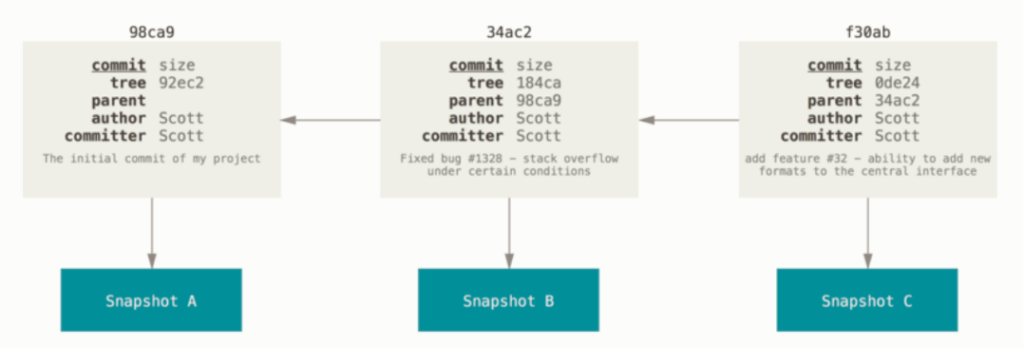
Il modello di gestione files di git
Ogni file in un repository git può avere uno dei seguenti tre stati:
- untracked: il file corrente non è tracciato
- committed: il file corrente è salvato nel repository;
- modified: il file è stato modificato rispetto alla commit attuale;
- staged: il file è stato aggiunto per la prossima commit.
E’ inoltre prevista una memoria temporanea (ma salvata comunque su disco) chiamata stash che memorizza i files in stato modified e ripristina la situazione precedente in stato committed. Sarà poi possibile recuperare i files stashed anche su un filesystem modificato da altre commit con il comando “stash pop”.
In un repository git sono quindi presenti in ogni istante 3 filesystem ben distinti:
- quello committed, identificato da un hash dello snapshot, e dallo shortcut “HEAD”
- quello in stage;
- quello modificato, che costituisce la directory di lavoro.
Infatti quando si modifica un file questo può essere quindi memorizzato in più di uno stato (ad esempio la versione committed e quella modificata) ma l’utente vede fisicamente sul filesystem solo l’ultima modifica dei file, anche se questi file ancora non sono stati committed.
Va ricordato che git funziona prima di tutto localmente, ma offre la possibilità di sincronizzarsi con un repository su macchina remota. E’ quindi basato su un modello peer-to-peer, anche se è prassi comune nella maggior parte dei progetti tenere un repository remoto condiviso centrale ed un insieme di repository locali che si sincronizzano periodicamente con questo, di fatto riproducendo una architettura client-server. In ogni caso è possibile fare un numero illimitato di commit localmente e sincronizzarsi sul server solo quando lo si desidera.
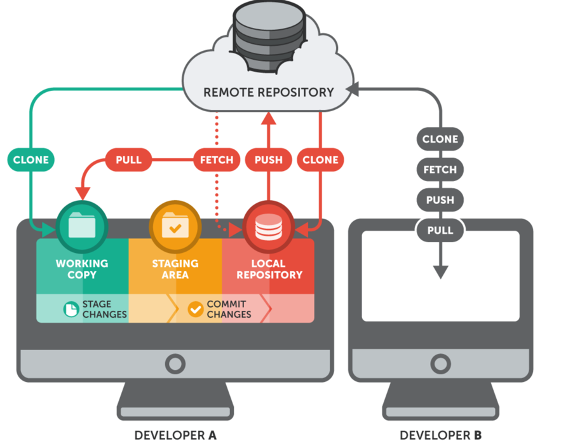
Hosting git
E’ possibile crearsi da soli un server di repository git, ma nel corso del tempo, su internet, sono sorti numerosi servizi online di hosting di repository per sviluppatori, alcuni gratuiti ed altri a pagamento, tutti che offrono la stessa tecnologia e proprio grazie alla loro diffusione sono diventati standard di mercato.
E’ possibile accedere in genere ad un servizio di hosting tramite autenticazione https (con nome password) o ssh (mediante chiave SSH).
I principali servizi di hosting sono:
- Github: sito di hosting più noto nel mondo, gratuito per progetti aperti e didattici, a pagamento per progetti privati, ora di proprietà di Microsoft;
- Gitlab: sito di hosting open source: gratuito a livello individuale, anche per progetti privati;
- Bitbucket: sito di hosting privato, di proprietà di Atlassian, nota per i prodotti Jira e Confluence, strumenti di collaborazione per professionisti: gratuito per piccoli team anche professionali, a pagamento per tutti gli altri.
Scenari reali di utilizzo
Qui di seguito si danno delle linee guida per lo sviluppo di progetti con git in due scenari: progetto monoprogrammatore (con uno o più computer di sviluppo) e progetto multiprogrammatore.
Progetto individuale:
- Preparazione iniziale
- Il programmatore crea un repository su un servizio di hosting git (vedi sotto).
- Dopo aver creato il repository si esegue il clone sulla macchina locale sulla quale si vuole sviluppare. Si ripete questo comando per ogni macchina locale sulla quale si lavora.
- Workflow di lavoro abituale:
- Si esegue un pull dal repository remoto per recuperare da master le ultime modifiche
- Si sviluppa nel seguente modo:
- Si scrive il codice di una funzionalità alla volta
- Si verifica quanto si è fatto
- Si esegue add + commit
- A fine sessione di lavoro si esegue la push remota, in modo da sincronizzare il repository. In questo modo se si cambia computer (premesso che l’ambiente di lavoro deve essere simile se non identico) il progetto resta allineato.
Progetto di gruppo:
- Preparazione iniziale
- Un programmatore – di solito il responsabile di progetto – crea un repository su un servizio di hosting git (vedi sotto).
- Dopo aver creato il repository ogni programmatore esegue il clone sulla macchina locale sulla quale si vuole sviluppare. Si ripete questo comando per ogni macchina locale sulla quale lavora ciascun programmatore.
- Workflow di lavoro abituale:
- Si esegue un pull dal repository remoto per recuperare da master le ultime modifiche
- Se le modifiche sono semplici:
- Si scrive il codice di una funzionalità alla volta
- Si verifica quanto si è fatto
- Si esegue add + commit
- Se sono articolate:
- Si crea un nuovo branch
- Si scrive il codice di una funzionalità alla volta nel nuovo branch
- Si verifica quanto si è fatto
- Si esegue add + commit (sempre nel branch)
- A fine sessione di lavoro si esegue la push remota (eventualmente nel proprio branch di lavoro), in modo da sincronizzare il repository.
- Nel caso di utilizzo di branch a fine lavorazione si esegue il merge sul branch principale. Questa operazione si esegue localmente dopo aver eseguito la pull di tutti i branch e del branch principale. Inoltre deve essere effettuata dal responsabile di progetto.
Si ricorda che non tutti i file di progetto devono essere sempre messi su git. Git è un prodotto pensato per gestire file di sorgente e file ad esso collegati, e non file di configurazione, file di database o asset (cioè immagini, video, ecc.). Queste tre tipologie di file infatti non sono strettamente materiale sviluppato ma file di corredo che dipendono sempre da un ambiente o contesto di sviluppo (ad esempio il pc locale del programmatore, o un ambiente di test, o un ambiente di rilascio). Di norma, quindi, nei progetti professionali tutti questi files sono esterni al progetto su git e gestiti in generale tenendo filesystem appositi o anche repository separati.
In ambito scolastico questo requisito non è così stringente, in quanto si usa di solito un ambiente di laboratorio, l’importante è tenere conto che questo tipo di lavorazione non è applicabile in progetti reali.
Guida di riferimento dei comandi
Git è un software che funziona da linea di comando. Ne esistono numerose interfacce grafiche, ma è impossibile comprenderlo a pieno se non si impara a usare bene i comandi da terminale. Questa guida spiega i comandi da terminale.
Identificazione
La prima volta che si usa git è necessario identificarsi per indicare nome ed email quando si eseguiranno le commit. I comandi sono i seguenti:
git config --global user.name NOME COGNOME
git config --global user.email username@domain
Come creare un repository:
git init
Bisogna prima posizionarsi nella cartella del progetto.
Da quel momento verrà creato il suo database (nella cartella nascosta .git)
Come verificare in quale stato si trovano i files:git status
Con questo comando i files committed (e stashed) non saranno visibili, i files modificati saranno in colore rosso, quelli staged (pronti per la commit) in verde.
Per aggiungere un file allo stato stage:git add <nomefile>
Sono ammesse le wildcard, quindi selezionare più files.
Per committare tutti i file in stato staged:git commit -m “commento”
Il commento è obbligatorio.
Per ripristinare i files modificati tornando a quelli committati:git reset --hard HEAD
Questo ripristinerà i soli files modificati. Se sono stati aggiunti nuovi files questi resteranno in stato modificato.
Per creare un nuovo branch:git checkout -b <nomebranch>
Git creerà il nuovo branch: tutti i files modificati e in stage presenti saranno committati nel nuovo branch.
Nota: va ricordato che quando si crea un repository git, viene creato un branch di default. Convenzionalmente questo branch si chiama “master”.
Per vedere tutti i branch presenti nel sistema (quello con l’asterisco è quello attivo):git branch
Per cambiare branch:git checkout <nomebranch>
Notare l’assenza dell’opzione -b.
Per eliminare un branch:
git branch -D <nomebranch>
Per eseguire un merge:
git merge <nomebranch>
Bisogna posizionarsi nel branch di destinazione. Un merge consiste nella copia di tutti files dell’ultima commit del branch di provenienza su quello di destinazione. Il branch di destinazione può essere qualsiasi branch esistente. Penserà git a copiare i soli files necessari. Verrà anche copiata tutta la history e quindi sarà sempre possibile ripristinare un possibile stato precedente. Al termine del merge, se tutto va buon fine, viene eseguita una commit sul branch di destinazione.
Il merge tra tutti i comandi git è il più impegnativo. Questo perché quando si esegue un merge git cerca di eseguire il merge a livello di singolo file, cioè cerca di integrare con un suo algoritmo di merging le modifiche aggiungengole o eliminandole nel file di destinazione. L’algoritmo è molto efficace e riesce quasi sempre ad eseguire merge corretti, tuttavia quando si esegue un merge su un file che nel frattempo era stato modificato e committato anche su un altro branch, l’algoritmo fallisce e git ci avverte che c’è stato un problema di merge. Non viene effettuata nessuna commit e i files dove è fallito il merge vanno in stato modified ed è quindi necessario un merge manuale, andando a ispezionare ogni file. Git però modifica il file facendo vedere in tutti i blocchi di testo dove ci sono due versioni differenti e questo facilita di molto il merge (a patto di ricordarsi quale è il blocco giusto).
Per vedere la history:
git log
verranno stampate tutte le commit, con l’hash, il nome dell’autore, la data e il commento. Sarà possibile anche vedere il branch ed eventuali simboli associati alla commit, ad esempio HEAD, o anche i tag associati.
Per visualizzare nel filesystem corrente una commit precedente:
git checkout <nomecommit>
Dove nome commit è l’hash della commit, o il tag, o il simbolo associato. Se questa commit non è associata ad un nome di branch, l’esecuzione di questo comando ci porta in uno stato “detached”, cioè fuori dalla history. Questo significa che tutte le modifiche e le commit eseguite ora non vengono aggiunte alla history “ufficiale” del repository, questo perché un punto (cioè una commit) a cui agganciarli. In genere questo comando è usato per vedere com’era in precedenza un file ed eventualmente copiare ed incollare le modifiche sull’ultima versione.
Per creare un nuovo branch coi files modificati e committati:
git switch -c <nuovo-branch>
Per tornare a HEAD:
git switch -
Per creare un tag:
git tag -a <nometag> -m ‘commento’
Questo comando associa la commit attuale ad un tag, visibile anche dal log.
Per vedere i tag:
git tag
Lavorare con repository remoti
Git permette di sincronizzare il repository locale con repository remoti.
Per clonare un repository remoto:
git clone <url del repository remoto> [<nomeremoto>]
Questo comando serve per clonare un repository remoto. Viene creato un repository locale dove viene copiato il branch principale (di solito master). Si usa quando non si ha un repository locale. Localmente il repository remoto viene associato al nome <nomeremoto> (opzionale, se omesso si usa il nome “origin”).
Per associare un repository locale ad uno remoto:
git remote add <nomeremoto> <url>
In questo caso si associa un nome remoto (non opzionale) ad una url.
Per ricevere una commit (con la sua history) da remoto:
git pull <nomeremoto> <nomebranch> [--allow-unrelated-histories]
Se i due repository non sono allineati (succede nel caso si sia aggiunto un remote con commit non collegate a quelle locali) è necessaria l’opzione –allow-unrelated-histories, che ripristina i database.
Per inviare una commit (con la sua history) ad un remoto:
git push <nomeremoto> <nomebranch> [--allow-unrelated-histories]
Per inviare i tag locali ad un remoto:
git push <nomeremoto> --tags
Gitignore
E’ possibile indicare a git un elenco di file da ignorare (non saranno messi in stage né in commit) in un file di testo speciale, che si chiama .gitignore. Occorre fare attenzione perché questo file è sotto controllo di versione. Le regole per inserire file in gitignore prevedono l’utilizzo anche di wildcard.