
Polimorfismo
Dipendenza tra classi
Nella lezione sull’ereditarietà abbiamo visto che le classi possono essere realizzate utilizzando una gerarchia in cui da una classe genitore di creano classi figlie e che a loro volta possono essere estese a loro volta. Questa gerarchia è quindi una struttura ad albero.
Ad un certo punto però questa gerarchia deve essere usabile dall’esterno, e quindi devono essere previste classi che conoscono la gerarchia e la utilizzano, dette anche consumatori. Questa relazione di dipendenza genera quindi una struttura di oggetti a forma di grafo, come in questo esempio.
Gerarchie di classi
Questo grafo viene chiamato grafo delle dipendenze. Per rappresentarlo possiamo usare UML ed il diagramma di classe.
UML è un linguaggio visuale che è stato introdotto per la fase di analisi e progettazione, che consente di realizzare diversi diagrammi che rappresentano sia la struttura dell’applicazione, sia il suo comportamento. Nella figura vediamo il diagramma di classe, dove vengono rappresentate le classi e le loro dipendenze (extends ed use), ciascuna con le proprietò (parte superiore) e i metodi (parte inferiore). Il simbolino + indica che la proprietà o il metodo è pubblico, il simbolino – indica che è privato.
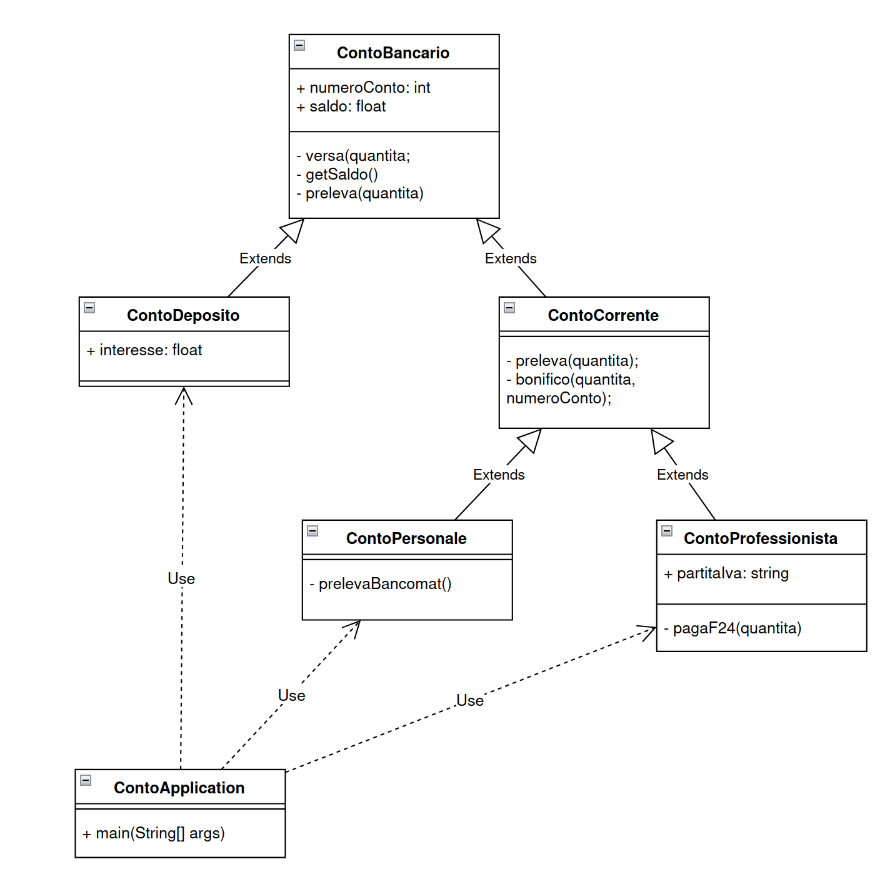
Vediamo un esempio:
package polimorfismo;
import java.util.Scanner;
class ContoBancario {
protected String numeroConto;
protected double saldo;
public ContoBancario(String numeroConto) {
this.numeroConto = numeroConto;
this.saldo = 0;
}
public void versa(double quantita) {
this.saldo += quantita;
}
public void preleva(double quantita) {
this.saldo -= quantita;
}
public double getSaldo() {
return this.saldo;
}
}
class ContoDeposito extends ContoBancario{
private double interesse;
public ContoDeposito(String numeroConto) {
super(numeroConto);
}
}
class ContoCorrente extends ContoBancario {
public ContoCorrente(String numeroConto) {
super(numeroConto);
}
public void bonifico(double quantita, String numeroConto) {
// logica per gestire bonifico
super.preleva(quantita);
}
}
public class ContoApplication {
public static void stampaSaldo(ContoBancario conto) {
System.out.println(conto.getSaldo());
}
public static void main(String[] args) {
int tipoConto;
Scanner input = new Scanner(System.in);
System.out.print("Inserisci codice 1 per deposito, 2 per conto corrente: ");
tipoConto = input.nextInt();
input.close();
ContoBancario nuovoConto;
if (tipoConto == 1) {
nuovoConto = new ContoDeposito("123456"); //
} else {
nuovoConto = new ContoCorrente("123456"); //
}
stampaSaldo(nuovoConto);
}
}
In questo esempio il consumatore (ovvero Application) :
- chiede all’utente che conto vuole;
- dichiara una variabile come classe genitore (ContoBancario);
- assegna alla variabile una nuova istanza della classe figlia in base alla richiesta dell’utente (ad esempio il conto deposito o il conto corrente).
- richiama un metodo (getSaldo) che riceve come argomento ContoBancario.
Come si può vedere non è necessario quindi ridefinire stampaSaldo() per ogni tipo di conto, è sufficiente usare la classe padre, perché usiamo un metodo definito nella classe padre. Restando generici è possibile quindi usare una qualsiasi sottoclasse senza riscrivere il metodo, perché tanto al metodo non interessa quale sottoclasse sta usando, perché deve usare una funzionalità comune a tutta la gerarchia.
Questo porta al Principio di Sostituzione di Liskov.
Principio di Sostituzione di Liskov (LSP)
Il principio per cui possiamo usare una classe figlia al posto del padre viene chiamato “Principio di sostituzione di Liskov”, ideato da Barbara Liskov, una informatica americana pioniera della programmazione ad oggetti (a lei si deve non solo questo principio ma il concetto di classe astratta e di gerarchia di classi).
Questo principio afferma che possiamo sostituire sempre una classe figlia al posto della classe padre, in quanto ogni classe figlia eredita dal padre tutte le caratteristiche.
E’ un principio fondamentale della programmazione ad oggetti, perché ci consente di rendere generici i consumatori, senza che dipendano dalla gerarchia di classi. Questo significa anche che è possibile modificare la gerarchia di classi, ad esempio aggiungendone di nuove, senza dover per forza modificare i consumatori.
Override
Una classe figlia può non solo aggiungere funzionalità ad una classe padre, ma può anche ridefinire il comportamento di uno o più metodi. Questa possibilità si chiama override.
Abbandoniamo il mondo bancario e passiamo ad un esempio di geometria.
abstract class FiguraGeometrica {
public double area() {
return 0;
}
}
class Rettangolo extends FiguraGeometrica {
double base;
double altezza;
public Rettangolo(double base, double altezza) {
this.base = base;
this.altezza = altezza;
}
public double area() {
return this.base * this.altezza;
}
}
class Cerchio extends FiguraGeometrica {
double raggio;
public Cerchio(double raggio) {
this.raggio = raggio;
}
public double area() {
return this.raggio * this.raggio * Math.PI;
}
}
public class FigureGeometriche {
public static void main(String[] args) {
FiguraGeometrica cerchio = new Cerchio(4);
FiguraGeometrica rettangolo = new Rettangolo(6, 4);
System.out.println(cerchio.area());
System.out.println(rettangolo.area());
}
}
Con l’override Java va a cercare prima se il metodo area() è definito nella classe Cerchio e solo se non è definito risale la gerarchia fino a trovare una classe che lo implementa.
Questo meccanismo si chiama polimorfismo, ovvero possiamo cambiare il comportamento delle classi derivate senza che i consumatori ne siano a conoscenza. Ancora una volta, al consumatore non interessa come l’oggetto utilizzato si comporta, basta che il metodo sia presente con quella firma.
Metodi astratti
Nell’esempio sopra indicato dichiariamo nella classe FiguraGeometrica un metodo area() per fare in modo che il consumatore possa utilizzarlo in modo generico senza sapere quale oggetto è stato effettivamente istanziato. Java infatti come detto sopra risale la gerarchia finché non trova un metodo che corrisponde a quanto richiesto.
Ma se una sottoclasse non reimplementa il metodo, cioè usa il metodo di FiguraGeometrica, non abbiamo errori, tuttavia il programma si comporta in modo errato.
Per obbligare le sottoclassi a reimplementare il metodo lo possiamo rendere abstract e non implementarlo. Quindi scriveremo:
abstract class FiguraGeometrica {
public abstract double area();
}Un metodo astratto è dichiarato ma non implementato. Sarà compito delle sottoclassi impegnarsi a farlo. Come si vede spostiamo il controllo della correttezza dal runtime al build time, evitando un errore di dimenticanza.
Possiamo usare la definizione di metodi astratti di una classe astratta per imporre il vincolo alle sottoclassi di implementare quel metodo. Ad esempio se una classe astratta VeicoloAMotore dichiara un metodo AccendiMotore() come astratto, sarà obbligo delle sottoclassi concrete implementarlo.
Questo però porta il vantaggio alle classi che usano il VeicoloAMotore di non doversi preoccupare “quale” sia il VeicoloAMotore effettivo che sarà usato. Il compilatore garantisce che il metodo AccendiMotore sarà implementato a runtime.
In altri termini la classe consumatore può dipendere solo dalla classe astratta ma non dalle sue sottoclassi, e senza conoscere tutta la gerarchia. Viene quindi garantito disaccoppiamento tra gerarchie di classi.
Interfacce
Questo meccanismo anche se efficace (ed implementato da quasi tutti i linguaggi di programmazione ad oggetti) prevede che il consumatore deve comunque conoscere l’esistenza della classe base.
Facciamo un esempio. Poniamo di avere la seguente gerarchia:
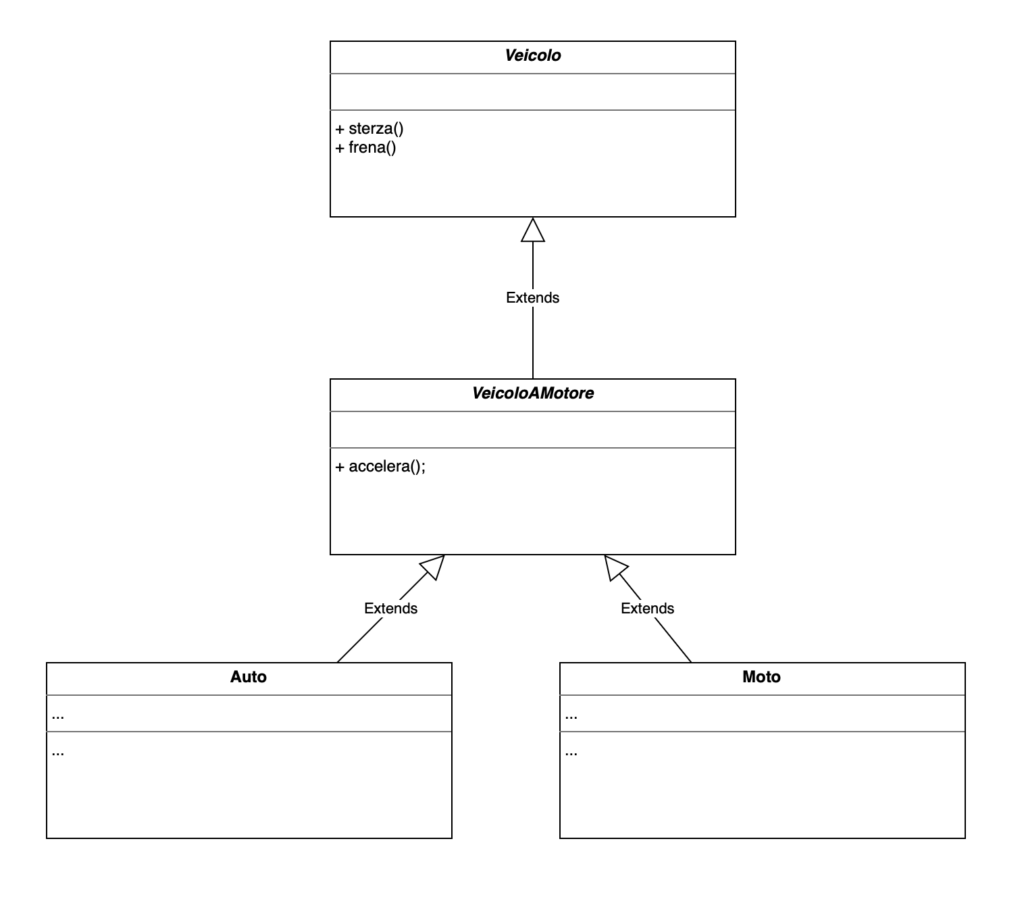
La classe astratta Veicolo introduce delle funzionalità, estese poi dalla classe astratta VeicoloAMotore, che a sua volta è estesa dalle classi concrete Auto e Moto.
Se vogliiamo utilizzarle potremmo scrivere la seguente applicazione:
public class Veicoli {
private static VeicoloAMotore[] creaOggetti() {
return new VeicoloAMotore[]{new Auto(), new Moto()};
public static void main(String[] args) {
VeicoloAMotore[] veicoli = creaOggetti();
veicoli[0].accelera();
veicoli[1].accelera();
}
}Per il principio di sostituzione di Liskov abbiamo dichiarato delle variabili di tipo VeicoloAMotore, ma poi le istanziamo con le classi figlie. Il consumatore (cioè la classe Veicoli) si appoggia alla classe base per dichiarare le variabili, e poi le istanzia con la classe figlia opportuna, sfruttando la gerarchia per gestire in modo generale le singole istanze (ad esempio usando il metodo tipologia).
Questo modello è tuttavia molto rigido, perché presuppone necessariamente una gerarchia. Poniamo quindi di eliminare la classe VeicoloAMotore e riportare tutti i suoi metodi solo nella classe Veicolo, come in questo schema:
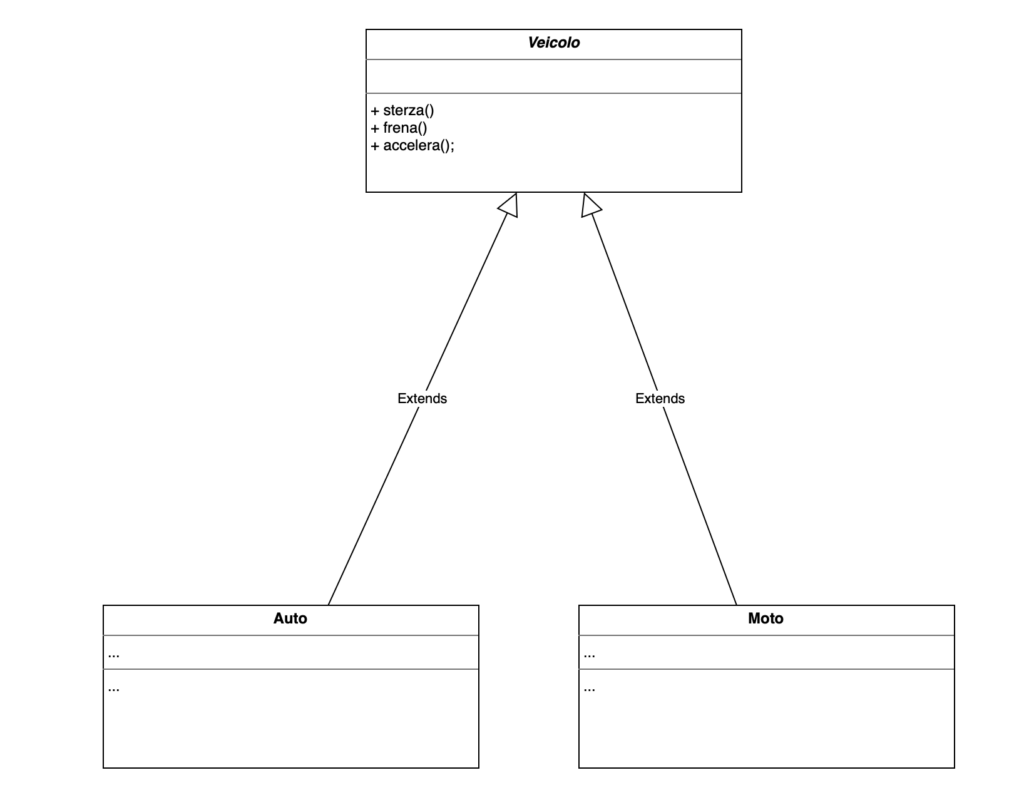
In questo scenario dovremmo riscrivere tutti i consumatori, come la classe veicoli:
public class Veicoli {
private static Veicolo[] creaOggetti() {
return new Veicolo[]{new Auto(), new Moto()};
public static void main(String[] args) {
Veicolo[] veicoli = creaOggetti();
veicoli[0].accelera();
veicoli[1].accelera();
}
}Questo tipo di modifiche può avere grossi impatti su progetti di grandi dimensioni, perché se cambia una gerarchia bisogna riscrivere anche l’implementazione di tutti i consumatori di quella gerarchia.
Il consumatore è vincolato sempre a quella gerarchia, anche se in realtà alla fine vengono eseguiti sempre gli stessi metodi. Se osserviamo bene il consumatore non dipende effettivamente da una classe specifica, ma solo da un metodo con una specifica firma. Non deve necessariamente sapere quale classe lo implementa.
Non solo, non deve nemmeno necessariamente sapere la gerarchia a cui appartiene.
Questo concetto si chiama “architettura a plugin” e per capirlo è sufficiente pensare ad una presa elettrica. Chi la costruisce si limita a disporre una uscita con una certa tensione ed un attacco compatibile con uno specifico standard. Non deve conoscere come verrà usata la corrente elettrica, e tantomeno chi la usa. L’importante è la “compatibilità”, non la “classificazione”.
Per questa ragione Java prevede il concetto di interfaccia. Una interfaccia è una dichiarazione di tipo che che prevede solo metodi astratti. Non è vincolata ad una gerarchia di classi, e non implementa nulla. Essa ha un solo scopo di dichiarare “un contratto di utilizzo” tra il fornitore di un servizio (cioè chi implementa il metodo) e il consumatore (cioè chi lo utilizza).
E’ quindi possibile scrivere classi che implementano una interfaccia, cioè che garantiscono che implementeranno uno specifico metodo.
Qui uno schema che riassume il concetto:
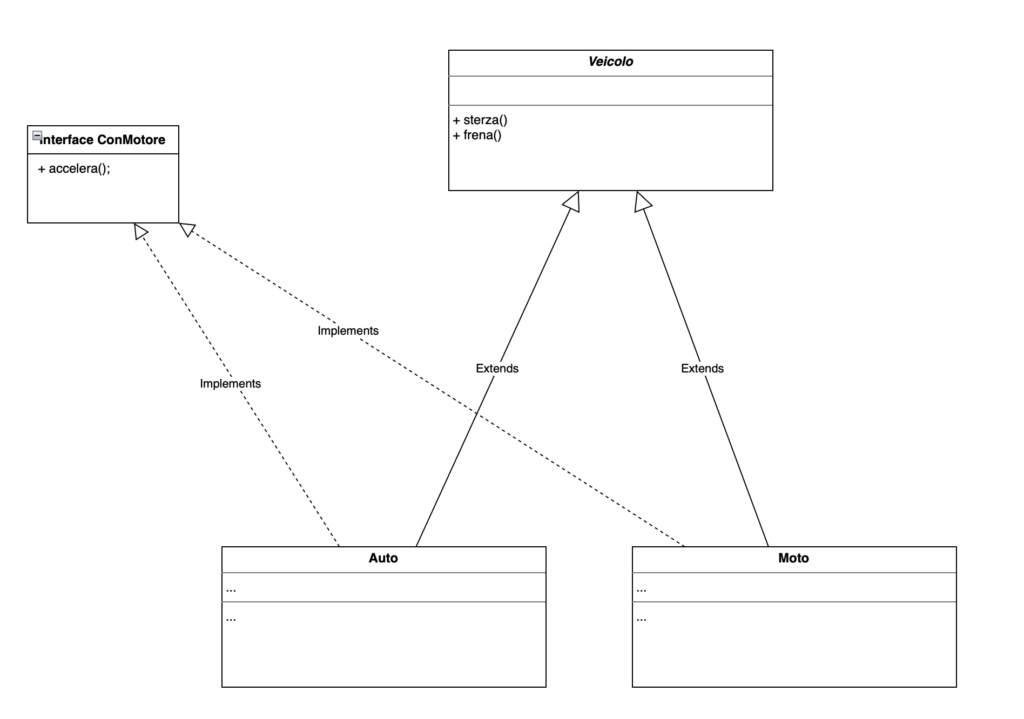
Come si vede abbiamo estratto il metodo “accelera” dalla classe astratta Veicolo e creato una interfaccia apposta. Le classi Auto e Moto sono obbligate ad implementarla, ed i consumatori possono serenamente utilizzarla senza sapere a quale gerarchia appartengono.
public class Veicoli {
private static ConMotore[] creaOggetti() {
return new ConMotore[]{new Auto(), new Moto()};
public static void main(String[] args) {
ConMotore[] veicoli = creaOggetti();
veicoli[0].accelera();
veicoli[1].accelera();
}
}A differenza del modello precedente possiamo liberamente modificare l’intera gerarchia di veicoli, associando l’interfaccia a qualsiasi livello della gerarchia. Il consumatore non ne sarà mai coinvolto, perché lui non si aspetta una classe specifica, ma crea un array di oggetti che implementano una interfaccia.
Questo porta ad un altro vantaggio: le classi che implementano una interfaccia non devono nemmeno far parte della stessa gerarchia di classi. Ecco un esempio:
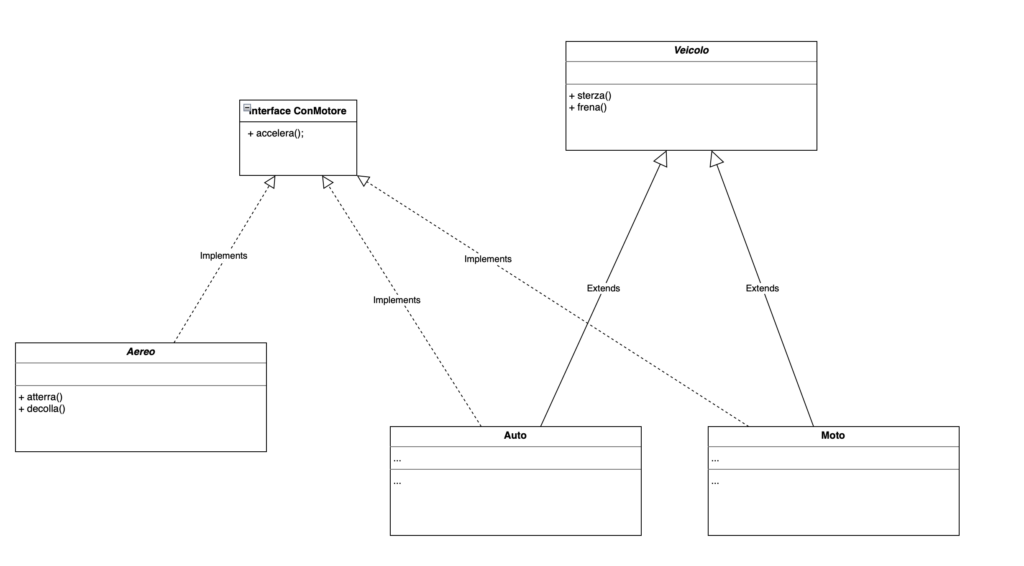
Come si vede la classe Aereo è esterna alla gerarchia di classi, ma non cambia nulla il consumatore:
public class Veicoli {
private static ConMotore[] creaOggetti() {
return new ConMotore[]{new Auto(), new Moto(), new Aereo()};
public static void main(String[] args) {
ConMotore[] veicoli = creaOggetti();
veicoli[0].accelera();
veicoli[1].accelera();
veicoli[2].accelera();
}
}e classi che la usano. Nessuna di queste conosce l’altra. E’ inoltre possibile implementare la stessa interfaccia in gerarchie indipendenti tra loro, ed il consumatore non è tenuto a sapere chi userà concretamente.
Il polimorfismo è dunque pienamente applicato quando il consumatore di un servizio non conosce la classe dell’oggetto che sta usando, ma solo la sua interfaccia. Questo permette quindi, nell’evoluzione di un progetto, di sostituire una classe, un oggetto o una intera gerarchia senza toccare il resto dell’applicazione.
Questo principio di progettazione si chiama Dependency Inversion.
Dependency Inversion Principle (DIP)
Questo principio afferma che un consumatore non deve dipendere da una classe ma da una interfaccia. Viene chiamata “inversione della dipendenza” perché non è la classe consumatore che dipende dalla classe fornitore, ma è la classe fornitore che deve indicare ai suoi consumatori cosa sa fare.
Per capirlo con un concetto fuori dall’informatica, un guidatore impara ad usare l’auto tramite volante, pedali, cambio, ecc., è cioé addestrato ad usare una interfaccia di funzionamento di qualsiasi oggetto dotato di volante, pedali, ecc. Per usarli non è tenuto sapere come sono fatti.
E’ invece il costruttore di auto a dover costruire una auto che dispone di questi comandi.
Se quindi un guidatore venisse fatto salire bendato su una auto mai vista, e la benda venisse tolta solo quando è dentro l’auto, sarebbe comunque in grado di guidarla, anche senza sapere che auto è.
In ingegneria del software è stato coniato il termine “architettura a plugin” per rendere bene l’idea di questo concetto. Un plug-in è un componente che è possibile sempre sostituire senza che chi lo usa se ne accorga, esattamente come cambiare una lampadina con una di tipo diverso da un lampadario, purché abbiano lo stesso “attacco” (cioè l’interfaccia).
Differenza tra classe astratta ed interfaccia
La domanda concreta che si pongono sempre i progettisti è “ma allora quando devo usare una interfaccia al posto di una classe astratta”. Per capirlo rivediamo le due definizioni:
- una classe astratta è una classe che non solo serve per mettere a fattor comune caratteristiche comuni di sotto classi, ma che può avere metodi non implementati (che saranno implementati dalle sottoclassi);
- una interfaccia definisce dei metodi che dovranno essere implementati dalle classi che implementano quella interfaccia.
Da ciò discende la regola generale. Bisogna usare una classe astratta quando è necessario mettere a fattor comune l’implementazione di uno o più metodi che verranno usati dalle sottoclassi.
Se invece una classe astratta definisce solo metodi astratti, solo per vincolare le sottoclassi ad implementarli, è sempre meglio usare una interfaccia.
Rischi nell’uso delle interfacce in Java
Il modo in cui Java implementa però questo meccanismo può comportare un rischio. Se infatti è molto comodo raccogliere in un contenitore, come un array, un insieme di oggetti con la stessa interfaccia, potrebbe essere necessario in alcune occasioni sapere cosa sono, per poter usare per usare funzioni specifiche.
Ad esempio, se al nostro lampadario vogliamo attaccare una lampadina “smart”, è vero che implementa lo stesso tipo di “attacco”, ma ha pure funzioni aggiuntive che vogliamo poter utilizzare e che non sono previste nell’attacco.
Per capirlo proviamo a scrivere questo codice:
public class Veicoli {
private static ConMotore[] creaOggetti() {
return new ConMotore[]{new Aereo(), new Aereo(), new Aereo()
};
public static void main(String[] args) {
ConMotore[] veicoli = creaOggetti();
veicoli[0].decolla();
}
}Se lo compiliamo, avremo un errore di compilazione. Per Java veicoli[0] non è un aereo, ma un oggetto che implementa l’interfaccia ConMotore, anche se internamente è un Aereo.
Per risolvere il problema dobbiamo fare uso del cast esplicito:
public class Veicoli {
private static ConMotore[] creaOggetti() {
return new ConMotore[]{new Aereo(), new Aereo(), new Aereo()
};
public static void main(String[] args) {
ConMotore[] veicoli = creaOggetti();
Aereo aereo = (Aereo)veicoli[0];
aereo.decolla();
}
}Dobbiamo per forza dire a Java cosa è quel veicolo prima di poterne usare le caratteristiche, perché non è in grado capirlo da solo.
Questo codice funziona, ma ci espone ad un rischio: non c’è modo di sapere, se non a runtime, se l’oggetto è effettivamente un aereo. Vediamo un esempio che compila correttamente ma da errore a runtime:
public class Veicoli {
private static ConMotore[] creaOggetti() {
return new ConMotore[]{new Auto(), new Aereo(), new Aereo()
};
public static void main(String[] args) {
ConMotore[] veicoli = creaOggetti();
Aereo aereo = (Aereo)veicoli[0];
aereo.decolla();
}
}Siccome l’oggetto veicoli[0] è internamente una auto, se forziamo il cast ad Aereo, Java si blocca e da errore.
Vedremo che questo difetto di Java viene risolto tramite l’uso di Generics, un tipo di dato che verrà visto in prossime lezioni.
Separazione delle interfacce
E’ anche possibile definire diverse interfacce per funzionalità differenti, e vincolare una classe ad implementare più di una interfaccia.
Facciamo un esempio:
interface PerimetroCalcolabile {
double perimetro();
}
interface CalcolaAngoli() {
int numeroAngoli();
}
class Rettangolo implements AreaCalcolabile, CalcolaAngoli {
double base;
double altezza;
public Rettangolo(double base, double altezza) {
this.base = base;
this.altezza = altezza;
}
public double perimetro() {
return 2 * (this.base + this.altezza);
}
public numeroAngoli() {
return 4;
}
}
class Cerchio implements PerimetroCalcolabile {
double raggio;
public Cerchio(double raggio) {
this.raggio = raggio;
}
public double perimetro() {
return this.raggio * 2 * Math.PI;
}
}Usare interfacce differenti è utile quando non vogliamo che le classi siano vincolate ad implementarle tutte. Ad esempio il cerchio non ha angoli ma ha senso avere una interfaccia comune per il calcolo del perimetro.
Interface Segregation Principle (ISP)
Questo principio da come indicazione di usare sempre interfacce specifiche per l’uso effettivo che se ne dovrà fare. In pratica anzichè creare una interfaccia che contiene molti metodi diversi tra loro, che vincolano poi le classi a doverli implementare tutti, è molto più convieniente e semplice creare interfacce specifiche per ogni singola funzione e farle implementare solo quando servono. Questa flessibilità è inoltre utile proprio nell’utilizzo: il contratto che deve rispettare la classe che la implementa si riduce solo allo stretto necessario.
Ad esempio un’auto a marce automatiche implementerà volante e pedali, ma non il cambio manuale. Per chi non conosce la guida col cambio manuale sarà ancora usabile.
Lo abbiamo visto con l’esempio delle due interfacce dell’area calcolabile e del perimetro calcolabile.
Classi anonime
Partiamo da questo esempio:
Cerchio[] cerchi = {
new Cerchio(3),
new Cerchio(1.5),
new Cerchio(4),
new Cerchio(2.2),
new Cerchio(5),
new Cerchio(0.8),
new Cerchio(3.7),
new Cerchio(1),
new Cerchio(2.9),
new Cerchio(4.4)
};
Possiamo ordinare gli array usando Arrays.sort(), ma siccome sono oggetti non c’è modo di compararli direttamente, ci serve un criterio. Per questo dobbiamo utilizzare un suo overload, che usa un comparatore:
Arrays.sort(array, comparator);dove comparator è un oggetto di una classe che deve implementare questa interfaccia:
interface Comparator {
int compare(Object a, Object b);
}Di norma quindi dovremmo scrivere una classe che implementa questa interfaccia e permette di comparare due cerchi fra di loro, come questa:
import java.util.Comparator;
public class ComparatoreCerchi implements Comparator{
@Override
public int compare(Object a, Object b) {
return Double.compare((Cerchio)a).area(), (Cerchio)b).area());
}
}Tuttavia è una classe che useremmo solo una volta. In questo senso Java prevede la creazione di classi anonime, direttamente dove devono essere usate:
Arrays.sort(oggetti, new Comparator() {
@Override
public int compare(Object a, Object b) {
return Double.compare((Cerchio)a).area(), (Cerchio)b).area());
}
});Il codice è lo stesso ma ci evita di creare una classe in più per un solo utilizzo.
Espressioni Lambda
Nei linguaggi funzionali le funzioni sono oggetti, e quindi possono essere memorizzate in variabili, restituite da altre funzioni, ecc. Infatti in questi linguaggi alla fine l’ordinamento è più semplice da scrivere perché basta passare una funzione di comparazione alla funzione di ordinamento, mentre in Java bisogna passare una istanza di una classe (per carità, anonima!) che implementa una interfaccia che contiene una funzione, con uno schema ridondante e prolisso.
Nelle ultime versioni di Java i progettisti si sono resi conto di questo problema, e pur senza introdurre il concetto di funzione come oggetto, è stato trovato un compromesso.
E’ stato infatti introdotto il concetto di interfaccia funzionale, ovvero di una interfaccia che ha un solo metodo, proprio come il comparatore. Per questo tipo di interfacce, viene reso possibile di passare direttamente una funzione detta “funzione Lambda”, nome preso a prestito dai linguaggi funzionali.
La lambda ha questa struttura
(argomenti) -> codice di una sola rigaIn questo caso quindi possiamo scrivere quindi:
Arrays.sort(oggetti, (a,b) -> Double.compare(((Cerchio)a).area(). ((Cerchio)b).area()));
Le funzioni Lambda permettono quindi di risparmiare tempo e rendono il codice molto più leggibile, senza “rompere” i principi di programmazione ad oggetti a cui Java è strettamente legato.
Conclusioni
In una applicazione reale non si hanno solo gerarchie di classi, ma si realizza un grafo di dipendenze dove alcune classi dette consumatori usano altre classi. E’ importante quindi capire che questo tipo di struttura può diventare molto complessa e vincolante.
Possiamo però utilizzare relazioni con la classe base di una gerarchia, perché grazie al principio LSP è sempre possibile una classe figlia, visto che ne eredita tutte le funzioni.
E’ stato introdotto il polimorfismo, una caratteristica della OOP che consente ad una classe figlia di reimplementare uno o più metodi della classe base grazie all’override dei metodi. Java ricerca all’indietro nella gerarchia delle classi il primo metodo che implementa quanto richiesto.
Ma il polimorfismo trova piena applicazione nell’uso delle interfacce. Queste rappresentano dei contratti che rendono indipendente il consumatore dalla gerarchia di classi utilizzata, che può essere estesa e rimodellata senza ritoccare le sue dipendenze. Questo principio è noto come DIP. Abbiamo infine visto che è sempre più utile segregare le interfacce in modo specifico, in modo da non obbligare una classe ad implementare tutti i metodi di una interfaccia, se non strettamente necessari.
SRP, OCP, LSP, ISP e DIP formano l’acronimo SOLID, e sono i cinque principi fondamentali della programmazione ad oggetti.