
Modelli di database
Architettura dell’informazione e database
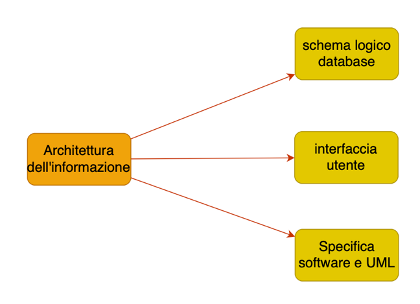
Per poter progettare un database è necessario prima di tutto analizzare e progettare l’architettura dell’informazione dell’applicazione nel suo complesso. Questa architettura, chiamata anche Domain Model, è un modello concettuale che suddivide le informazioni gestite dall’applicativo in unità concettuali, generalmente chiamate entità, e definite tramite attributi. Le entità possono essere collegate tra loro tramite relazioni che determinano i flussi di informazione e quindi il modo in cui è organizzata la conoscenza da parte dell’applicazione. Il Domain Model è quindi un modello concettuale che rappresenta il modo in cui è organizzata l’informazione, si tramite la definizione di entità (e attributi) e il modo in cui agiscono le relazioni tra queste.
Il database è invece una rappresentazione logica di questa struttura, e stabilisce quindi il modo in cui i dati dovranno essere organizzati tra loro, tenendo conto anche delle tecnologie messe a disposizione. Ne deriva che un database è una rappresentazione del modello concettuale/domain model, ma per farlo deve tenere conto di aspetti di natura concreta, come la struttura dati utilizzata, e le tecnologie utilizzate, in particolar modo il database engine.
Un database engine è una tecnologia (generalmente un software o una famiglia di software) che permette allo sviluppatore di realizzare concretamente il database e di utilizzarlo, sia manualmente sia tramite API da parte dell’applicazione che userà il database. Il database engine offre quindi un linguaggio o qualche metodologia per modellizzare il database (chiamata DDL) e per inserire/modificare/cancellare i dati (DML). Nel momento in cui si progetta un database a partire dal modello concettuale è quindi necessario tenerne conto, in modo analogo a quanto avviene quando si sceglie un linguaggio di programmazione ed una tecnologia specifica per la realizzazione di un software.
Il database non va quindi confuso con il Domain Model nel suo complesso, che invece va a definire anche dinamicamente flussi di informazione e interfacce con l’utente, come già abbiamo visto nella lezione collegata, ma non solo rappresenta la struttura dei dati, ma anche la forma possibile che essa dovrà assumere. Vedremo tra poco che esistono diverse tipologie di strutture di database.
Tipologie di strutture di database
Esistono diverse tipologie di database .
- database a forma di tabella: i dati sono organizzati in forma appunto di tabelle, con diverse forme di organizzazione, tra cui una di quelle più diffuse prevede di considerare una tabella come un insieme di entità dello stesso tipo (dette anche record) una per ogni riga, e le colonne come attributi dell’entità rappresentata nella riga. Ad esempio un elenco di anagrafiche di persone potrebbe essere rappresentato come nella tabella seguente. Tipici database engine di questo tipo sono i fogli di calcolo, come Microsoft Excel, e sono il tipo di database probabilmente più usato al mondo. Un database engine consente una interrogazione (tramite ricerca o filtro) e l’applicazione di modifiche massive anche mediante strumenti automatici come formule o script. Come si può vedere proprio nell’esempio qui sotto le entità riga organizzano l’informazione in un modo che può essere ridondante, ripetendo per ogni entità attributi che potrebbero essere condivisi tra più righe.
| Nome docente | Cognome docente | classe | Nome studente | Cognome studente | Materia |
| Mario | Bianchi | 3A | Marta | Genovesi | Informatica |
| Mario | Bianchi | 3A | Valerio | Nerini | informatica |
| Mario | Bianchi | 3A | Lucia | Russo | informatica |
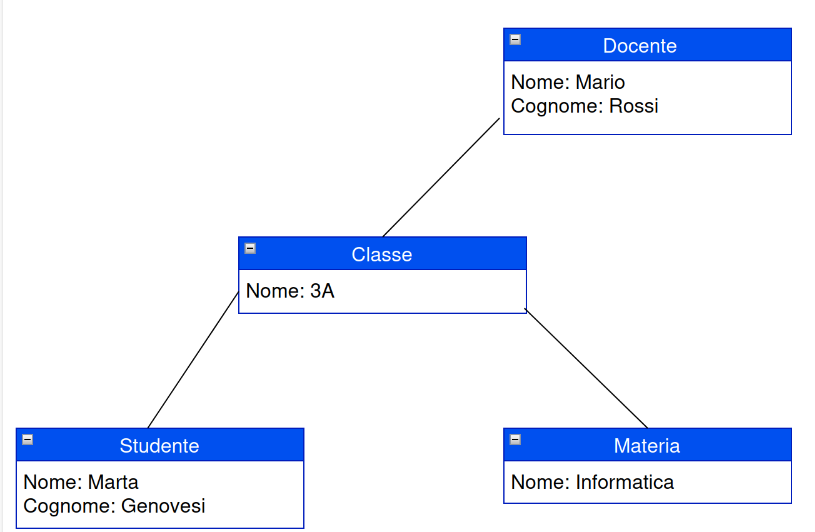
- database di tipo gerarchico, dove i dati sono strutturati ad albero. Nel modello gerarchico anzichè avere un unico tipo di entità con molti attributi (anche ridondati), è possibile suddividerle e collegarle tra loro tramite una relazione di tipo gerarchico (padre-figlio) dove un attributo è in realtà una istanza di una entità figlia, con suoi propri attributi ed eventuali nodi figli.
Il vantaggio è quindi quello di evitare ridondanza dei dati ed una migliore organizzazione in entità più piccole che sono più legate ad un singolo concetto di informazione (docente, classe, ecc.)
Il formato di documenti XML è un esempio di questo tipo di documento e può essere utilizzato per rappresentare o distribuire database strutturati in modo gerarchico, anche con regole complesse sui tipi di dati utilizzabili, l’obbigatorietà e il formato dati utilizzabile. Ad esempio molti formati di documenti complessi (ad esempio quelli di Microsoft Office o Libre Office) sono strutturati in XML, così come molti formati di interscambio di database su Internet (ad esempio quelli usati dal protocollo SOAP). Un altro formato gerarchico, meno espressivo ma più semplice è il formato JSON. Si veda qui sotto un esempio di organizzazione gerarchica. Qui un esempio di database gerarchico:
- database relazionali (RDBMS): le singole entità sono memorizzate sotto forma di tabelle, dove le righe sono le istanze di una entità e le colonne i suoi attributi. Le tabelle sono però connesse tra loro tra loro tramite relazioni di molteplicità (uno a uno, uno a molti) ottenendo così un grafo, come si può vedere nell’esempio qui sotto.
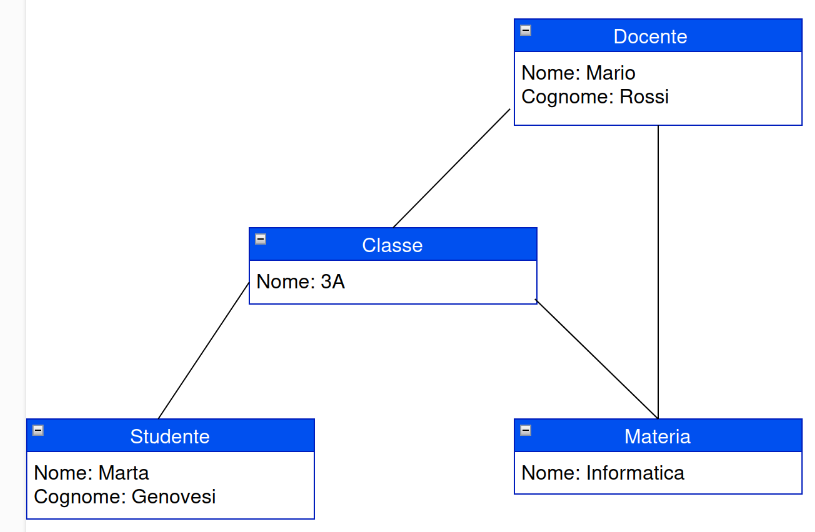
In generale il modello a grafo anche se concettualmente più complesso di quello gerarchico, offre un grande vantaggio rispetto a quello ad albero. In un albero infatti esiste un solo cammino nelle relazioni tra due entità, e quindi nell’esempio per conoscere la materia che insegna un docente occorre interrogare il database cercando prima le classi dove insegna e solo dopo conoscere la materia. Nel modello a grafo possiamo (se ci serve) collegare direttamente il docente alla materia e rendere più intuitivo lo schema logico e più simile al modello concettuale (ovvero il domain model). Nel modello relazionale sono previste solo relazioni 1-1 o 1-molti, ma è possibile ottenere relazioni anche molti a molti o di appartenenza tramite opportune entità aggiuntive (tabelle di relazione e tabelle di decodifica).
Gli RDBMS prevedono un linguaggio specifico per la loro modellizzazione (DDL) e manipolazione (DML). Il linguaggio più diffuso per gestire entrambe è il linguaggio SQL, ed i database engine più diffusi sono SQLite, Mysql, Oracle, Sql Server e PostgreSQL, ognuno con una propria variante di SQL. I database engine più avanzati consentono di gestire concorrenza e sezioni critiche tramite l’uso di transazioni. I database relazionali sono ad oggi tipo di database più diffuso, anche per ragioni tecnologiche (le prestazioni oggi raggiunte sono eccezionali, e migliori di qualunque altra architettura di database).
- database ad oggetti (ODBMS), le entità sono modellizzate tramite oggetti, ovvero strutture che implementano ereditarietà, polimorfismo e incapsulamento. Il grafo che ne deriva non prevede quindi solo relazioni di molteplicità ma anche di dipendenza o di ereditarietà ed in generale la rappresentazione logica dell’informazione è molto simile a quella del Domain Model, superando quindi alcuni dei vincoli della struttura a grafo.
Tuttavia, rispetto agli RDBMS, sono molto meno diffusi perchè hanno prestazioni inferiori, per un insieme di ragioni tecnologiche, prima di tutto la grande velocità raggiunta dai database relazionali che ha limitato lo sviluppo di altre tecnologie. Tuttavia nel corso degli ultimi 15 anni si sono sviluppate delle librerie che permettono di creare database ad oggetti usando internamente i database relazionali: si tratta degli OR/M, che ad oggi puntano a sostituire o meglio a “nascondere” in toto gli RDMBS. Tra questi vanno ricordati Hibernate (Java), Entity Framework (.NET), Doctrine (PHP) e Sequelize (NodeJs).
Gli OR/M oggi rappresentano una metodologia standard di realizzazione di database, che riduce al minimo la necessità di imparare SQL, anche se per ottenere le migliori prestazioni resta la tecnologia dominante.
- database NoSQL, dove le entità sono memorizzate sotto forma di documenti con id univoco, con o senza relazioni tra loro, ma che (in generale) non fanno uso del linguaggio SQL ma di sistemi alternativi di memorizzazione. Tra questi spiccano:
- i database engine basati su JSON come MongoDB/CouchDB. Il mondo MongoDB ha avuto un enorme successo sia perché è il database di riferimento di NodeJs, ma anche perché JSON si pone come strumento alternativo al sistema di modellazione tabellare perché nel modello relazionale la singola entità ha attributi fissi ed ogni record di ogni entità è obbligato ad averli anche quando non presenti o non necessari. Questa struttura si rivela poco flessibile per la gestione di database semistrutturati, come quelli che organizzano grandi moli di dati non correlate tra loro. Questo tipo di database hanno il nome commerciale di BigData. I Big Data sono database con una struttura non rigida organizzate in entità chiamate Datalake. Il motivo per cui non sono strutturati è perché a differenza di quanto visto finora è necessario memorizzare informazione per cui non esiste o esiste limitatamente un Domain Model corrispondente all’organizzazione dei dati. Il mondo BigData è di enorme importanza commerciale oggi in quanto costituisce la base di informazione principale che alimenta i sistemi di apprendimento dei modelli computazionali di intelligenza artificiale.
- i motori di ricerca come ElasticSearch/Apache Solr (il database è un motore di ricerca)
- i dizionari chiave/valore (esempio Redis), dove l’intero database è un dizionario chiave/valore ad altissime prestazioni.
- infine possiamo inserire tra i database engine anche i modelli basati su reti neurali (in particolare i transformers e la loro più nota applicazione, gli LLM, ovvero i Large Language Models). Questi prodotti sono dei modelli computazionali che memorizzano dati ed informazioni su più livelli di “consapevolezza”. In altri termini questi sistemi sono addestrati basandosi su informazione strutturata o semi strutturata (vedi sopra i BIg Data) e sono in grado di costruire in modo automatico un modello concettuale strutturato. In questo tipo di memorizzazione non è il progettista a creare il modello dei dati, ma al contrario i dati vengono inseriti tramite uno schema di apprendimento per esempi e poi il modello si addestra automaticamente memorizzando esempi e risultati attesi fino ad ottenere una struttura interna (detta appunto “modello computazionale”) in grado – se sufficientemente addestrata – di ricevere input e restituire output di conoscenza in modo del tutto autonomo. Il modello è sufficientemente complesso da poter usare il termine “intelligenza artificiale”.
La forza di questo modello è che è in grado di interpretare linguaggio naturale, che è in grado di ricordare il contesto della richiesta (e in base alla sua capacità computazionale anche le richieste precedenti) e dare una risposta sintetica in cui generalizza e contestualizza la risposta in base alla richiesta dell’utente. Di contro la potenza di calcolo richiesta è ad oggi enorme, così come la richiesta energetica, non si ha il controllo dei dati inseriti (quindi si ha un potenziale rischio di sicurezza) il servizio ha un costo ambientale enorme, e in generale almeno nelle versioni più avanzate ha costi significativi. Le problematiche connesse a questo sono infine e soprattutto che il set di addestramento di dati influenza enormemente l’apprendimento (problema del bias o pregiudizio) e che le risposte hanno una base statistica e potrebbero non essere corrette.
E’ comunque una tecnologia in evoluzione e quindi ci saranno sicuramente aggiornamenti significativi nel breve medio periodo.
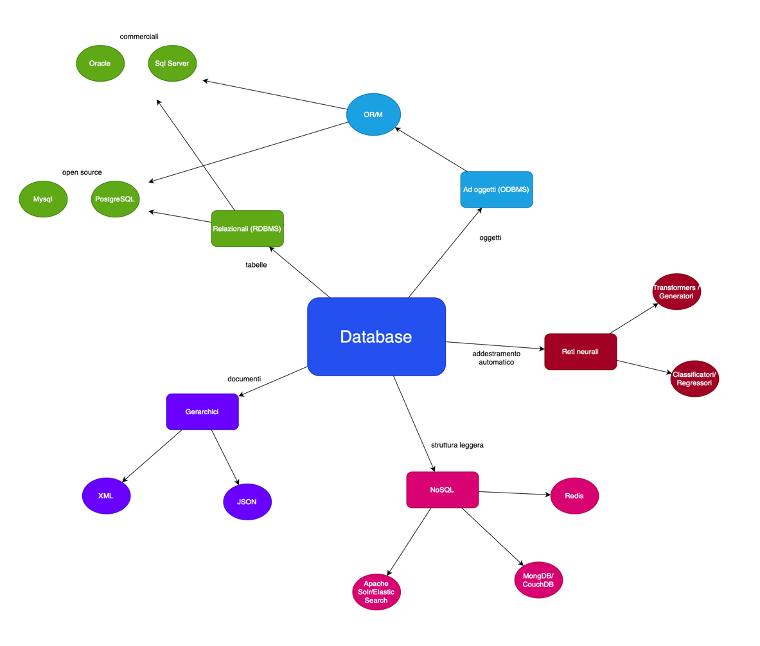
Gli RDBMS basati su SQL ancora oggi costituiscono la tecnologia più importante e diffusa, anche se spesso sono affiancati da sistemi NoSql (come i motori di ricerca) o sono utilizzati da un OR/M. anche se per molte applicazioni e tecnologie sono spesso affiancati da prodotti come MongoDB o Redis. I sistemi basati su Reti Neurali vanno invece a costituire un nuovo modo di intendere il concetto stesso di database ed informazione, perché superano il problema del formalismo domanda/risposta, ma soffrono di problemi legati al fatto che generano risposte su base statistica e non hanno strumenti di validazione che possono dire con certezza se un dato è corretto oppure no.