
DevOps
La fase di delivery
Finora abbiamo visto le macrofasi che riguardano l’analisi, la progettazione, l’analisi tecnica e il vero e proprio ciclo di sviluppo, quali artefatti producono e in che modo il software viene prodotto dal team di sviluppo, col supporto di progettisti da una parte e tester dall’altra.
Resta da approfondire cosa succede “a valle” della produzione del software, ovvero quelle attività che complessivamente sono chiamate delivery. Anch’esse sono oggetto di studi di ingegneria del software sia in termini di processo/organizzativi che in termini di tecnologie in modo da renderle ed al contempo ridurre gli errori umani.
Rivediamo limitatamente al processo Waterfall qual è la parte che è coinvolta, dove le fasi di delivery sono a seconda del tipo di progetto tutte le attività che consistono nel comporre un sistema funzionante composto da un ambiente di sviluppo, un database ed il pacchetto software realizzato.
In questa trattazione anche se generale, verrà posta particolare attenzione al mondo server.
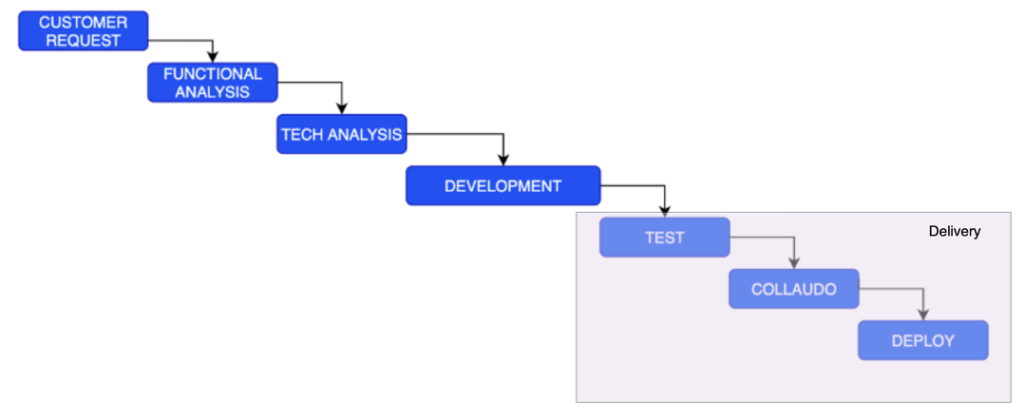
Indipendentemente dall’ambiente di rilascio (test, collaudo, produzione), essa prevede un rilascio (deploy) del software su una qualche macchina (detta ambiente di esecuzione) dove è presente un set di dati già predisposto, per poi svolgere una qualche attività di esecuzione.
Schematicamente qui sotto possiamo vedere quali sono gli attori coinvolti e quali sono le attività di ciascuno di questi.
Gli attori sono:
– lo sviluppatore che scrive il codice del prodotto, ed è responsabile della qualità del codice;
– il sistemista che si occupa delle “operations”, ovvero predispone gli ambienti di esecuzione;
– il QA (Quality Assurance) che si occupa della validazione.
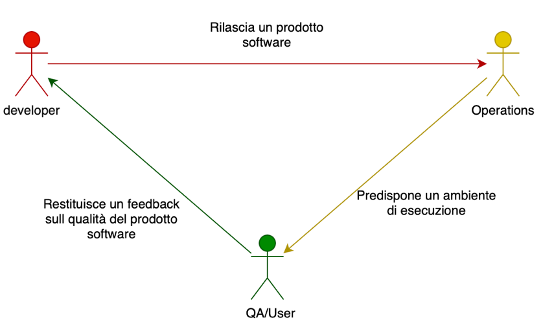
L’attività di deploy coinvolge contemporaneamente tutte queste figure perchè ciascuna di queste ha un ruolo nel definire la modalità del deploy stesso.
Infatti come vediamo facilmente dallo schema seguente il deploy coinvolge sia la build del software (a carico del team di sviluppo), sia la creazione dell’ambiente (a carico del team di Operations), sia infine la strutturazione dei database e il loro popolamento in modo opportuno (da parte di tester/QA/utenti).
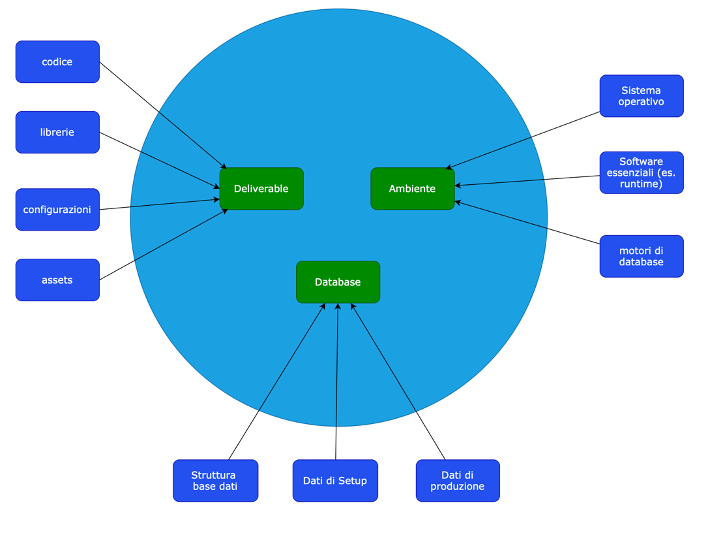
Il deploy consiste quindi nel “mettere insieme” questi elementi in modo consistente: quindi ad una specifica versione del software non solo devono corrispondere librerie, assets e configurazioni corrette, ma anche la struttura del database deve essere quella prevista, così come i dati devono essere significativi per quanto dovrà essere validato/testato/usato, e così via con l’ambiente, quindi il sistema operativo, i software essenziali, ecc. che devono essere quelli effettivamente previsti in fase di analisi tecnica.
Ad esempio in un ambiente di test verrà predisposta una build specifica di test, in un ambiente di test adeguato, con un database che contiene dati necessari per il test. In collaudo la build cambia, così come i dati e l’ambiente (ad esempio si attiva una specifica configurazione con determinati asset, il database contiene copia di dati reali, e l’ambiente è più completo rispetto al test), e così via fino alla produzione.
In ciascuna delle tipologie di rilascio ciascuno degli attori ha responsabilità distinte e competenze specifiche, gli sviluppatori per il software, i sistemisti/operations per gli ambienti, e gli utenti per i dati.
Infatti lo sviluppatore non può certamente avere accesso, per un insieme di ragioni di sicurezza, ma anche di competenza, a server dove magari sono in esecuzione applicazioni anche di altri prodotti software, e certamente non può avere un account amministrativo per gestire queste risorse. Allo stesso tempo anche se il sistemista ha accesso alla macchina dove installare il software, non ha cognizione di come questo è fatto, se sono necessarie attività di setup particolari, o altro ancora. Infine, nè il sistemista nè il programmatore hanno una chiara idea di quali dati possano essere utili per testare, collaudare, validare o comunque verificare la qualità del software, perchè questa è una competenza ed una responsabilità del team di QA o degli utenti finali.
Questa differenza di competenze, ruoli, responsabilità, tempi di attivazioni ha costituito a lungo un problema significativo nelle fasi di rilascio, comportando inefficienze ed errori anche gravi. Il problema del deploy è sempre stato presente nell’industria del software, solo con le applicazioni connesse ad Internet, le app mobili e le applicazioni server, utilizzate da diverse stratificazioni di utenti e distribuite su macchine remote è diventato un problema centrale da risolvere.
Il problema poi è tanto più grave per quelle aziende che rilasciano software più di frequente, ed in particolare quelle che hanno diverse fasi di validazione (non solo test, collaudo e produzione).
DevOps
DevOps è una metodologia di lavoro che punta a risolvere proprio questo problema, ed ha come obiettivo quello di realizzare una collaborazione tra Developers, QA ed Operations.
Essa si basa sul concetto che tutti i soggetti devono condividere la stessa responsabilità.
Avere la stessa responsabilità significa superare una delle rigidità del modello Waterfall (dove ogni team pensa in modo separato al proprio compito) ed a costruire invece un modello di sviluppo “Agile” dove competenze e responsabilità sono condivise e tutti i passaggi sono svolti insieme.
Il rilascio incrementale
La prima azione intrapresa, dovuta proprio all’esistenza di un team unificato, è quella di ricercare sia a livello generale, sia a livello di singolo progetto, di strategie e metodologie per semplificare il rilascio. Da qui l’introduzione del concetto di rilascio incrementale: anziché fare rilasci poco frequenti con un gran numero di modifiche, si è cercato di introdurre frequenti piccoli rilasci di piccole modifiche, col rischio quindi di ridurre l’impatto della modifica, e riparare in modo più preciso ad eventuali errori o inconsistenze.
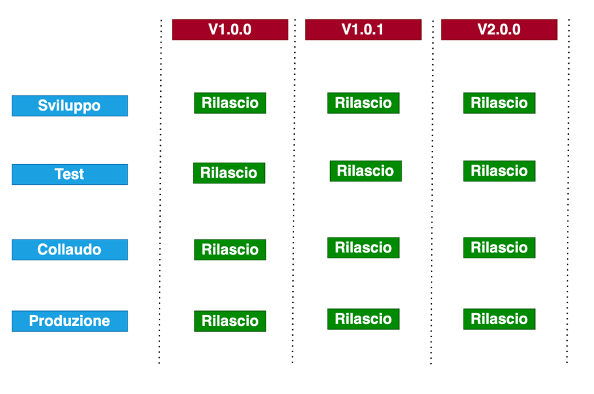
C’è però una problematica che nasce proprio dal rilascio incrementale. Oggi molte software house hanno spesso più team di lavoro indipendenti sullo stesso macroprogetto. Un team si occupa della manutenzione correttiva del software in produzione, dove ad ogni bug individuato corrisponde la correzione, il testo ed il rilascio delle correzioni in una versione minore. Nel frattempo un altro team si occupa della creazione di una nuova versione che invece introduce nuove funzionalità, e che quindi ha un suo ciclo indipendente (e suoi ambienti) di sviluppi, test, rilasci.
E’ normale quindi che in questi progetti ci siano decine di rilasci, per ogni combinazione di versione del codice e di ambiente e di linea di sviluppo. Qui uno scenario di una (semplice) applicazione verosimile, dove con quattro ambienti e tre versioni si hanno già 12 rilasci. Nei casi reali la tabella più avere ancora più ambienti e versioni, con il risultato di avere rapidamente decine o centinaia di rilasci.
L’automazione
Siccome i rilasci sono diversi ma tutti si basano sulla stessa identica procedura (o su procedure molto simili), la soluzione individuata consiste nell’automatizzare ogni rilascio, tramite strumenti appositi:
- per gestire le modifiche nel codice (come ad esempio git);
- per la creazione di database tramite script;
- per il rilascio vero e proprio.
A questi strumenti sono poi associate interfacce (web) usabili da personale non specializzato (che si limita a “premere un tasto”) o eseguiti in modo temporizzato (il sistema automaticamente produce un nuovo rilascio ogni tot tempo o dopo una commit, le cosiddette “nightly build”). Questo riduce enormemente gli errori di rilascio, non richiede di “presidiare” i rilasci meno importanti (es. in ambiente di test) e proprio la frequenza dei rilasci consente di perfezionare le attività di rilascio con continui piccoli miglioramenti.[1]
I test automatici
L’automazione coinvolge non solo lo sviluppatore che automatizza le build, ma è possibile rendere automatiche molte attività di QA. Esistono ad oggi infatti librerie, per tutti i linguaggi e tutte le tecnologie, che permettono di creare test automatici. E’ una metodologia che oggi fa parte di DevOps ma ha una origine più antica, risalente al 2000, con l’introduzione del concetto di unit test[2] e che è profondamente collegata a quanto abbiamo visto nella definizione delle architetture a componenti e plugin. Questa tecnica di programmazione consiste non solo nel suddividere (come abbiamo visto con le architetture) il codice in componenti unitari che svolgono una sola cosa, ma di scrivere, contestualmente, una o più funzioni che testano in automatico ogni singolo componente (detto unit) dell’applicazione, tramite un test detto unit test.
Qui un esempio di codice per NodeJS (per farlo funzionare è necessario installare la libreria jest (npm install jest) ed eseguire il comando jest nella cartella dove si trova il file di test. Come si può vedere il test unitario garantisce che la singola unità di codice funzioni, fin dall’inizio e dopo ogni eventuale modifica. Si tratta di una semplice classe anagrafica dal significato evidente:
class Anagrafica {
constructor() {
this.elencoPersone = [];
}
aggiungiPersona(persona) {
this.elencoPersone.push(persona);
}
trovaPersonaPerNome(nome) {
return this.elencoPersone.find(persona => persona.nome === nome);
}
rimuoviPersona(nome) {
this.elencoPersone = this.elencoPersone.filter(persona => persona.nome !== nome);
}
numeroPersone() {
return this.elencoPersone.length;
}}
module.exports = Anagrafica;Qui lo unit test scritto contestualmente:
const Anagrafica = require('./anagrafica');
test('aggiunge una persona correttamente', () => {
const anagrafica = new Anagrafica();
anagrafica.aggiungiPersona({ nome: 'Mario', cognome: 'Rossi' });
expect(anagrafica.numeroPersone()).toBe(1);
});
test('cerca una persona per nome', () => {
const anagrafica = new Anagrafica();
anagrafica.aggiungiPersona({ nome: 'Luigi', cognome: 'Verdi' });
const persona = anagrafica.trovaPersonaPerNome('Luigi');
expect(persona.cognome).toBe('Verdi');
});
test('rimuove una persona correttamente', () => {
const anagrafica = new Anagrafica();
anagrafica.aggiungiPersona({ nome: 'Maria', cognome: 'Bianchi' });
anagrafica.rimuoviPersona('Maria');
expect(anagrafica.numeroPersone()).toBe(0);
});Oltre ai test unitari possono essere sviluppati test automatici sia a livello di modulo sia a livello di esperienza utente, quindi sull’intera applicazione (questi test sono chiamati “e2e” end to end), sia infine di integrazione con altri sistemi (es. testando chiamate fetch a servizi remoti e controllando il funzionamento della chiamata).
Scrivere test unitari sembra inizialmente una perdita di tempo. In realtà i test unitari riducono ad una frazione i test manuali, e quindi i tempi di sviluppo e di rilascio. Infatti il test automatico se ben progettato elimina la necessità di riverificare, ad ogni modifica, tutte le singole funzioni, permettendo al test manuale di concentrarsi su aspetti particolari e critici. Inoltre il test automatico permette di capire subito dove sta l’errore: siccome viene effettuato a livello di componente, è facile individuare e correggere l’errore. Il test automatico quindi riduce la necessità di debugging.
I test automatici sono parte integrante del processo di DevOps: grazie all’automazione è possibile non solo eseguire il rilascio in automatico, ma è possibile eseguire in automatico anche tutti i test.
Questa attività di rilascio incrementale, automatico, comprensivo di test automatici, prende il nome di Continuous Delivery, ed è supportata da numerosi strumenti software, come ad esempio prodotti come Jenkins, Gitlab, Bamboo ed altri ancora.
Quando il rilascio incrementale ed automatico poi va ad essere effettuato su diversi sistemi software in contemporanea (es. applicazioni client-server, o servizi che sono rilasciati insieme) allora si parla di Continuous Integration, perchè si svolgono anche test di integrazione tra diversi sistemi, dove cioè il test automatico va a effettuare test anche di connessione e scambio dati tra sistemi differenti.
Conclusioni
In questa dispensa abbiamo visto come DevOps è una metodologia che ripensa tutti i processi di rilascio, e introduce nuove modalità sia organizzative che tecniche per rendere razionale ed efficiente il rilascio.
Abbiamo visto che l’automazione di rilasci e test gioca un ruolo fondamentale sia per lo sviluppatore che per il tester.
[1] E’ interessante osservare che il modello DevOps sia “figlio” del modello produttivo toyotista che a quello Waterfall, che è a sua volta figlio del fordismo. Questi sono stati e sono tuttora i due principali modelli produttivi industriali, a partire dall’industria dell’automobile (da cui i nomi di Ford e Toyota), a cui si è uniformata ogni altra industria, compresa quella informatica. Se al modello Waterfall di produzione corrisponde una rigida organizzazione tramite un piano preordinato e studiato nei dettagli, al modello Agile corrisponde invece flessibilità e miglioramenti incrementali, con un piano iniziale solo generale.
[2] L’inventore del test automatico è Kent Beck. Anzi più propriamente Beck ha inventato una vera e propria metodologia di sviluppo, l’Extreme Programming, che si basa proprio sui test automatici.