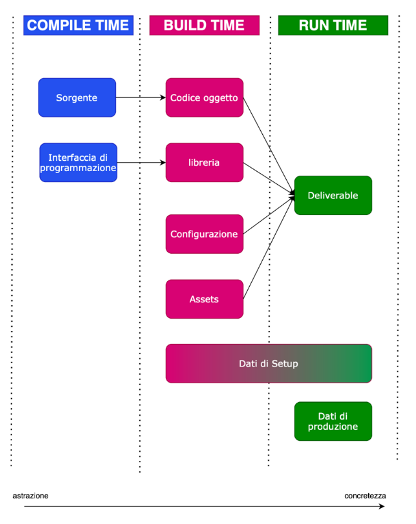
Deliverable, ambienti, dati
Deliverable
I deliverable sono tutti gli artefatti necessari per realizzare la build ovvero il pacchetto applicativo eseguibile in un ambiente di esecuzione,
Una build comprende quattro tipologie di deliverable: codice, assets, configurazioni e librerie. Analizziamoli in dettaglio:
| Descrizione | Dipendenze | |
| Codebase | l’insieme di tutti e soli i sorgenti di un progetto scritti dal programmatore, indipendenti dal contesto di esecuzione. Ogni sorgente rilasciabile (dopo test) è etichettato con una versione, per distinguerlo dagli altri sorgenti precedenti e futuri. | Il codice non deve dipendere da nessun contesto di esecuzione. Esso è per definizione generale ed astratto. Il codice per essere eseguito ha bisogno di librerie, configurazioni ed asset, ma per essere scritto non dipende da loro. |
| Librerie | l’insieme di librerie di terze parti, comprensive delle interfacce di programmazione. Ogni libreria è un software, e ogni versione di codebase dipende da una versione specifica delle librerie. | Sono usate dalla codebase, ma la scelta di quali librerie dipende dalle scelte fatte dal programmatore. |
| Configurazioni | L’insieme di informazioni che servono per far funzionare il codice in un determinato ambiente. Questo significa che sul pc del programmatore il codice ha bisogno di una configurazione, su un server invece si ha bisogno di un’altra. | Le configurazioni dipendono dall’infrastruttura hardware e software dove viene fatto girare il software. La codebase non deve dipendere da una specifica configurazione. |
| Asset | Tutte le risorse digitali a supporto del prodotto software: immagini, font, icone, ecc. ovvero qualunque artefatto che “non è codice”. | Sono usate dalla codebase, sotto forma di simboli a compile time, e sotto forma di risorse digitali a runtime. |
Nel loro insieme queste risorse, che finiscono tutte nel pacchetto applicativo, vengono definite deliverable (in italiano “rilasciabili”) e sono parte del pacchetto che verrà rilasciato per l’installazione per l’esecuzione da parte dell’utente finale.
Ambiente di esecuzione
L’ambiente di esecuzione gioca un ruolo fondamentale nella fase di runtime: il test può essere influenzato da parametri hardware (cpu, memoria, rete, periferiche, ecc.), software (sistema operativo, tipologia di browser nelle web applications, ecc.) ed infine dai dati. Ad esempio il pc del programmatore dove eseguiamo il test della nostra applicazione web non ha le stesse caratteristiche hardware e software dei sistemi dove verrà eseguita dall’utente finale.
Come vedremo più avanti nei progetti più grandi possono essere previsti inoltre degli ambienti intermedi, via via più complessi, per gestire fasi diverse dello sviluppo del prodotto software.
Per capirlo facciamo l’esempio dell’applicativo di registro elettronico che si usa nelle scuole. E’ una applicazione che quando viene sviluppata dal team di sviluppo utilizzerà un ambiente piccolo e con limitate capacità di calcolo. Quando sarà rilasciata invece sarà installata su un server di grande potenza e capacità, adatto a servire molti utenti in contemporanea.
Dati
Per poter sviluppare una applicazione il programmatore progetta anche la struttura dei dati su cui dovrà lavorare il software. Essi assumono quindi una particolare rilevanza sia nel design dell’applicazione, sia nel ciclo di vita di sviluppo, perché per capire e verificare se il software funziona senza difetti è necessario predisporre opportunamente non solo una struttura dei dati, ma anche dei set di dati significativi. Vanno gestiti in particolare sia i casi dove i dati sono quelli che ci si aspetta, sia i casi in cui i dati non sono completi, o nella forma corretta, o in qualche altra situazione non prevista.
Le applicazioni elaborano dati provenienti da molte fonti (database, servizi web, file, ecc.) e quindi la gestione dei dati è dipendente da aspetti sia tecnologici (dove si trova il dato, se è in un file, in un database, in un servizio remoto, ecc.) che di design (la struttura che il programmatore ha dato ai dati). Nonostante ciò è fondamentale comprendere che qualsiasi sia la fonte dati e la struttura dei dati stessi essi possono essere classificati in due grandi categorie: i dati di setup ed i dati di produzione, che hanno scopi e ruoli diversi.
| Setup | Sono i dati che sono inseriti dall’amministratore (o comunque una utenza che non corrisponde all’utente finale) PRIMA dell’esecuzione della applicazione e servono a fornire informazioni necessarie al corretto funzionamento dell’applicazione. Ad esempio nell’applicazione che gestisce il registro di una scuola, i dati di setup sono la composizione delle classi, i nomi degli alunni, le materie e gli insegnanti. | I dati di setup possono essere predisposti a build time o anche a runtime, ma separatamente e prima della normale operatività di utilizzo dell’applicazione. |
| Produzione | Sono i dati elaborati dall’applicazione, direttamente per mezzo o dagli utenti finali. . Ad esempio nell’applicazione di registro elettronico sono i dati sulle presenze alle lezioni, i voti, le informazioni sulle lezioni svolte, le pagelle. | I dati di produzione sono prodotti solo a runtime tramite interazione con l’utente finale. |
La regola generale è che Il codice deve essere indipendente dai dati, ovvero non devono essere mai fatte ipotesi sui dati stessi.
Ad esempio una applicazione di registro elettronico non deve fare ipotesi su quanti alunni avrà una classe o su quali saranno le materie, anzi deve gestire situazioni limite, come classi senza alunni o alunni senza classi. Occorre fare attenzione al fatto che i dati non sono un deliverable ma sono una risorsa esterna al software. Anche in questo caso e proprio per questo, nei progetti più grandi, i set di dati a disposizione per verificare il funzionamento del software possono variare, di solito (ma non sempre) contestualmente al tipo di ambiente di esecuzione del software.
Nello schema seguente si vede in sintesi come e quando appaiono questi oggetti nel ciclo di sviluppo.