
Ciclo di vita dello sviluppo
Compile time e runtime
Possiamo facilmente renderci conto che nello sviluppo del software, qualsiasi sia il linguaggio di programmazione ed il tipo di applicazione da realizzare, l’attività di programmazione (coding in inglese) consiste, per la natura stessa dei sistemi di sviluppo, di due fasi alternate
La prima fase è la codifica. In questa fase il programmatore scrive il codice e per farlo svolge una attività di tipo astratto e concettuale: fa una serie di ipotesi sui dati, sui flussi del programma, sulle variabili, sugli input, ecc. e poi scrive codice su un editor di testo sotto forma di formalismi e simboli.
Non c’è modo, mentre si scrive il codice nell’editor di testo, di capire se quello che sta facendo è corretto.
Fino a quando non viene eseguito il programma non si può verificarne il comportamento e quindi capire se ci sono errori nella sua progettazione e/o nello sviluppo.
La seconda fase è l’esecuzione. In questa fase vengono eseguiti tool che validano il codice, eventualmente lo compilano e lo impacchettano in una qualche modalità eseguibile, predispongono un ambiente di esecuzione ed infine eseguono il codice. Durante l’esecuzione l’elaboratore esegue le istruzioni, memorizza le variabili ed accede alle risorse reali.
Non c’è modo, fino a quando si è in esecuzione, di modificare il codice mentre si è in esecuzione.
L’esecuzione è una specie di “scatola nera” (una blackbox in inglese) che ci consente di vedere cosa fa ma non di correggere “al volo” eventuali problemi. Il programmatore deve quindi prendere nota del comportamento, capire cosa va e cosa non va, e poi tornare di nuovo al codice per sistemare problemi o effettuare migliorie, dove però torna a lavorare in astratto e per formalismi.
La programmazione è in sostanza quindi una alternanza di fasi di codifica-esecuzione in cui lo sviluppatore scrive codice, collauda, sistema ricollauda in un ciclo di aggiunta e perfezionamento fino a quando non ottiene il risultato ottenuto ed esegue quindi il rilascio (deploy).
In realtà le fasi sono quattro, ne vanno aggiunte altre due:
1) il codice che scrive il programmatore prima dell’esecuzione viene validato (verificata la correttezza formale) e poi tradotto in codice eseguibile (mediante compilazione o interpretazione). Inoltre il programmatore fa uso di risorse statiche (immagini, testi, icone, font. ecc. dette asset) e di librerie esterne (tramite API, ovvero interfacce di programmazione), sia di infine di configurazioni che dipendono da un preciso contesto di esecuzione (il nome del file da aprire, la password per accedere alla cache remota, ecc.). Queste risorse sono, dal punto di vista della scrittura del codice, dei semplici simboli (appunto il nome di un file, la url di un webservice, la password di un database, ecc.).
E’ necessaria una fase intermedia, il build time, in cui la macchina procede sia alla validazione si all’integrazione delle librerie, degli asset e delle configurazioni nel pacchetto applicativo.
2) E’ poi spesso presente una modalità di esecuzione speciale che consente al programmatore di fermare l’esecuzione in un punto preciso e vedere – ma solo ad esecuzione interrotta – lo stato della memoria e delle variabili: questa modalità viene chiamata “debug“, e sebbene non consenta di modificare “al volo” il codice, consente almeno di vedere cosa succede passo passo.
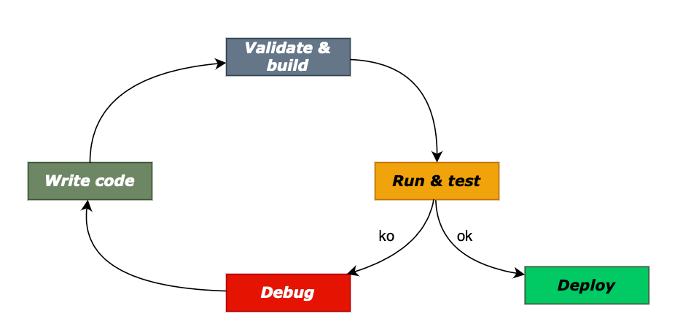
Rivediamo quindi in sintesi tutto il ciclo di sviluppo:
A compile time il programmatore analizza e scrive il codice sulla base di modelli, algoritmi ed ipotesi. In questa fase la programmazione è un processo astratto che è solo frutto di un ragionamento del programmatore che fa uso esclusivamente di simboli e formalismi.
A build time il codice e gli altri simboli, nonché tutte le risorse necessarie vengono accorpate in un unico pacchetto pronto ad essere eseguito. In questa fase l’ambiente di sviluppo fa uso di automatismi per verificare la correttezza formale del codice (errori di sintassi, variabili nulle, ecc.). Tuttavia il codice anche se formalmente corretto non è ancora testato, quindi potrebbero comunque esserci errori visibili solo in esecuzione, dovuti a errori concettuali o ad una risoluzione non corretta dei simboli in valori reali (es. configurazioni sbagliate). Va osservato che alcuni linguaggi di programmazione ad alto livello, proprio perché dotati di molti formalismi, sono in grado di intercettare molti errori di tipo concettuale già in fase di compilazione (Java o C#). Altri linguaggi invece sono molto tolleranti con gli errori, come Javascript o Python, col risultato di richiedere più attenzione a runtime su errori imprevisti.
A runtime il software viene eseguito, corredato di tutte le librerie, configurazioni e asset. Non solo ma entra in gioco per l’esecuzione anche un nuovo elemento, il contesto di esecuzione (cpu, memoria, filesystem ecc.) detto environment. A runtime è opzionalmente possibile fare debug, che permette di fermare l’esecuzione ad una certa istruzione, vedere le variabili in esecuzione ed eseguire passo passo l’applicazione per vedere in dettaglio dove si trova l’errore, che però dovrà essere sistemato a compile time.
Come si può vedere lo sviluppo è una attività ciclica che termina solo quando l’esecuzione porta ad un test soddisfacente. A sviluppo completato si procede col rilascio, ovvero quell’insieme di attività che hanno come obiettivo l’installazione del software nella macchina dove sarà eseguito dagli utenti e poi alla realizzazione della funzionalità successiva.
E’ consigliabile, data la particolare complessità che ha lo sviluppo di software, procedere alla realizzazione di una (piccola) funzionalità per volta, da testare e correggere individualmente, onde evitare molti cicli di sviluppo-test su software troppo complesso.