
Architetture
Architettura del software
Abbiamo già visto due obiettivi dell’ingegneria del software: studiare e proporre dei processi di sviluppo del software efficaci ed efficiente, e definire un insieme di caratteristiche di qualità misurabili che definiscono un buon software. C’è un terzo ed ultimo obiettivo: quello di definire una buona struttura del software, in modo tale che possa garantire gli obiettivi di qualità richiesti, rispettare i requisiti non funzionali (scalabilità, modificabilità, estensibilità e sicurezza) e che sia in grado di adattarsi sia ai processi di realizzazione ed alle persone coinvolte nello sviluppo.
Per raggiungere questo obiettivo fin dagli albori dell’informatica sono stati proposti diversi paradigmi di programmazione (strutturato, ad oggetti, funzionale) e negli ultimi decenni è nata una vera e propria sotto-area dell’ingegneria del software, ovvero lo studio delle architetture software, disciplina che si è andata sviluppando di pari passo con l’evoluzione delle tecnologie e delle applicazioni del software.
Ma cosa è una architettura software?
Una architettura è un modello che definisce la struttura di un software mediante la sua scomposizione in componenti, definisce il loro ruolo ed il modo in cui comunicano. Ad esempio l’architettura client-server è una architettura a due componenti, il client ed il server, dove il server ascolta delle richieste ed il client le invia, come si vede l’architettura ne definisce i componenti, il ruolo e la comunicazione.
L’architettura e le tecnologie del software (linguaggi, ambienti, infrastrutture, ecc.) sono discipline informatiche che si sviluppano in parallelo, che spesso sono collegate ma che rivelano comunque due anime distinte. Le seconde si evolvono tramite lo sviluppo ed i risultati della tecnica e della tecnologia, mentre la prima ne coglie i frutti per il programmatore (e tutta la filiera) a scrivere applicazioni di qualità, qualsiasi sia la tecnologia sottostante, con l’obiettivo di permettere flussi di gestione dell’informazione e dell’interazione con l’utente realmente efficaci, così come garantire i requisiti non funzionali sopra indicati.
Va però fin da subito chiarito che mentre la progettazione si occupa di definire cosa fanno i componenti di un sistema software, l’architettura ha lo scopo di supportare la progettazione, non sostituirsi ad essa. Essa è quindi strumento, non fine del progetto, e quindi si pone al servizio del risultato, esattamente come il linguaggio, la tecnologia, il paradigma di programmazione, ecc.
In questa lezione definiremo delle regole generali per costruire una buona architettura software e successivamente esamineremo alcune architetture di largo successo.
I componenti: i mattoncini di ogni applicazione.
In qualsiasi progetto non banale non è pensabile progettare un numero ridotto di componenti “enormi” che fanno tante cose diverse. Si rischia di creare codice troppo complesso da capire, da mantenere e da sistemare. In particolare si rivelano particolarmente inefficaci i componenti che fanno molte diverse cose non correlate, detti anche “God objects”, perchè ogni volta che si interviene per sistemarli, modificarli o abbellirli si rischia di toccare troppe cose contemporeaneamente, e romperne qualcuna che prima funzionava.
Il primo principio che deve guidare la progettazione è il seguente:
Principio di singola responsabilità (SRP):
ogni componente progettato deve essere responsabile di una ed una sola cosa.[1]
In altri termini ogni componente (cioè un oggetto/classe/funzione) deve avere un solo scopo preciso ed univoco. Se abbiamo bisogno di eseguire un insieme di operazioni, le scomponiamo in singoli componenti, e poi ne creiamo uno che li utilizza. La scomposizione in componenti ci offre manutenibilità (si ripara solo il singolo componente che si rompe), estensibilità (si sostituisce un componente con un altro che fa le cose meglio), sicurezza (è più facile capire dove sta l’errore quando ogni singolo componente fa una sola cosa).
Dal concetto di componente deriva poi quello di dipendenza: un componente delega ad altri aspetti specifici, in quanto si occupa di una cosa soltanto. Alcuni componenti sono delegati poi a raccordarne altri, sempre secondo il principio che ogni componente è responsabile di una sola cosa.
Nella programmazione ad oggetti i componenti in genere sono oggetti, e quando ad esempio si usa il polimorfismo, la dipendenza non è espressa da un oggetto ad un altro, ma tramite la sua interfaccia pubblica[2]. Questo permette di sostituire un qualsiasi componente con un altro, purchè abbia la stessa interfaccia, con ancora vantaggi in estensibilità e sicurezza[3]. Un sistema simile si può adottare anche nei linguaggi funzionali, dove funzioni generali sono specializzate in funzioni specifiche con la stessa firma, ovvero è possibile trasformare una funzione con più argomenti in una sequenza di funzioni con un solo argomento (quindi una sola responsabilità).
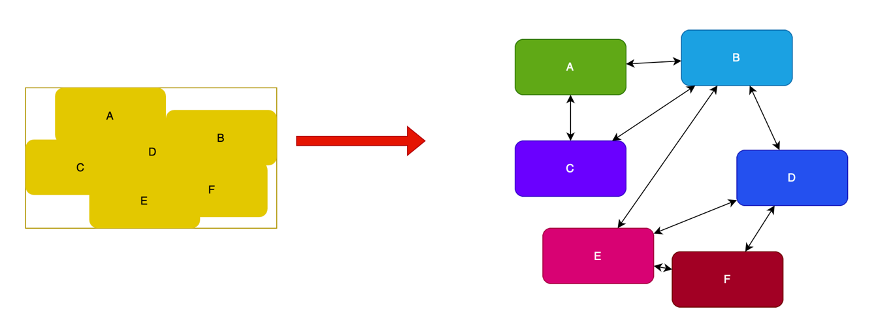
La struttura dell’applicazione
Una applicazione è quindi rappresentabile come un grafo di componenti collegati tra loro. Inoltre questo grafo è:
- orientato: ogni componente dipende da uno o più altri (o se “a monte” da nessuno), da un componente dipendono altri componenti (o se “a valle” da nessuno). Questo vuol dire che ad esempio la UI di una applicazione è a valle, perché dipende dalle logiche applicative e dal modello dati, mentre le entità che compongono la base dati del progetto è a monte, perché da esse dipendono le funzioni e gli algoritmi che costituiscono la logica del programma.
- aciclico: è una condizione legata al fatto che siccome ogni componente ha una sola responsabilità, non potrà mai dipendere da altri componenti che dipendono anche indirettamente da lui, altrimenti vorrebbe dire che hanno la stessa responsabilità.
Si può inoltre osservare inoltre che ogni componente del grafo ha due proprietà:
- il rischio di cambiamento: indica quanto è probabile, che con l’evoluzione del progetto, il componente possa cambiare. Ad esempio una UI è soggetta ad un alto rischio di cambiamento, perché si può desiderare di modificare l’interfaccia grafica di una applicazione per renderla più semplice ed usabile.
- la stabilità: quanto quel componente è facilmente riusabile in contesti differenti, perché abbastanza astratto o generico. Ad esempio una classe che salva o carica file è abbastanza stabile e quindi riusabile.
Obiettivo del progettista è fare in modo che i componenti con alto rischio di cambiamento siano più a valle possibile. Viceversa fa in modo che i componenti stabili siano più a monte possibile.
Una buona architettura è una architettura a plugin
Abbiamo capito come suddividere una applicazione in più oggetti/classi/funzioni e dare loro una struttura e delle relazioni chiare e semplici da implementare. Questo compito però diventa molto complesso quando i componenti cominciano ad aumentare. Questo perché inevitabilmente si crea una “ragnatela” di componenti fittamente collegati tra loro che rende molto complicato capire dove sta un bug o aggiungere una funzione.
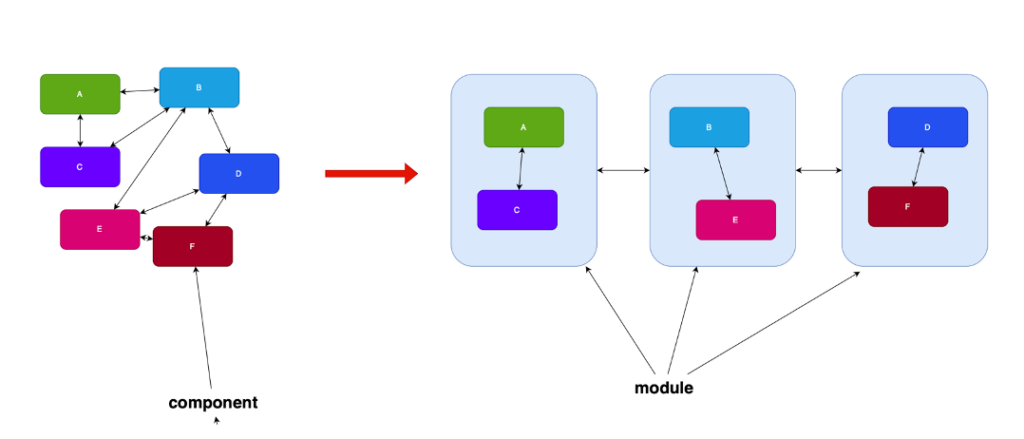
Per questa ragione è necessario raggruppare i componenti in gruppi ad alto livello chiamati moduli. Ciascun modulo ha un ruolo chiaro, una specie di macro-obiettivo all’interno dell’applicazione. Quindi contiene componenti omogenei tra loro, e comunica con gli altri moduli mantenendo chiara la distinzione da una parte riducendo i collegamenti tra moduli allo stretto necessario e mantenendo invece ben collegati i componenti dello steso modulo.
I due principi che guidano la progettazione modulare sono:
Alta coesione:
ogni componente progettato deve fare una, ed una sola cosa
Basso accoppiamento:
i componenti di moduli distinti hanno un accesso limitato a componenti di altri moduli
Così, come nella programmazione ad oggetti si incapsulano negli oggetti sia i dati che le funzioni e si creano delle interfacce tra oggetti, nell’architettura modulare si raggruppano diversi componenti in un modulo e si crea una interfaccia tra moduli. Quindi anzichè far coesistere tutti i componenti in un unico gigantesco modulo, si suddivide l’applicazione in moduli, più semplici da gestire, suddividere tra i programmatori, aggiustare se hanno difetti, e ampliare se sono richieste più funzioni. Questo permette di ottenere gli obiettivi oltre che di sicurezza, manutenibilità e di estensibilità anche di scalabilità, in quanto i moduli sono veri e propri “plugin” sostituibili, estensibili e modificabili anche in base all’ambiente di esecuzione.
A questo punto occorre capire però in base a quali criteri suddividere l’applicazione in moduli. Per capirlo introduciamo il concetto di layer.
Le applicazioni sono composte da strati
Esistono due criteri principali per suddividere il software in moduli:
– dividere per casi d’uso, e per ciascuno scrivere un modulo specifico. Ad esempio si potrebbe dividere una applicazione web in tante pagine html, ognuna con il suo Javascript che svolge un compito specifico. Oppure dividere un web service in tanti microservizi ognuno che svolge un compito specifico.
– dividere per astrazioni: consiste nel creare moduli in base al ruolo che hanno nell’applicazione, includendo tutti i componenti, anche di use case diversi, che però hanno delle caratteristiche tecniche comuni.
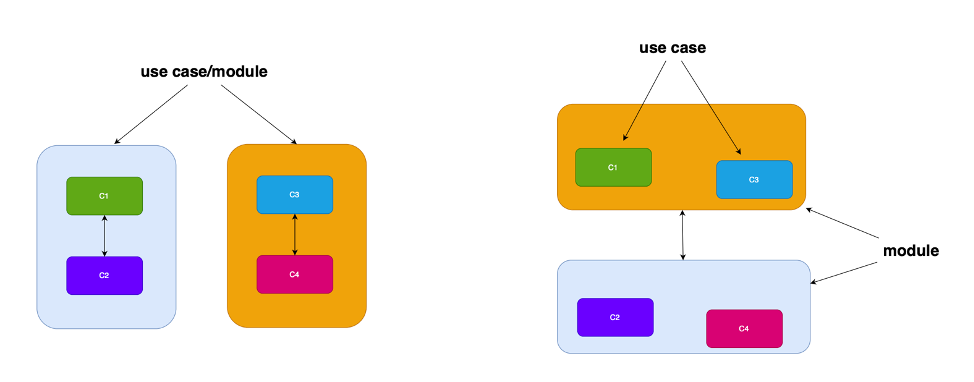
In generale la maggior parte delle applicazioni web e la quasi totalità delle applicazioni utente (quindi web, mobile, desktop), si utilizza la suddivisione per astrazioni. Se infatti in ogni layer sono gestiti diverse funzionalità o casi d’uso, è possibile però per il programmatore mettere a fattor comune un insieme di componenti del layer condivisi che sono usati in più di un caso d’uso. Con l’altro sistema invece ogni modulo, proprio per mantenere un basso accoppiamento, dovrebbe implementare una copia identica di componenti altrimenti comuni.
Inoltre la suddivisione in layer permette di suddividere in modo efficace l’architettura dell’applicazione in quattro layer in base al loro livello di astrazione e di distanza rispetto all’utente. Vediamoli:
– View: esso organizza i dati in un formato leggibile ed usabile dall’utente, e mostra anche le azioni possibili. In questo layer viene mostrata solo quella porzione dei dati significativa per l’utente e con una formattazione comprensibile dall’utente. Nel mondo web la visualizzazione è quindi principalmente html, eventualmente con un template che traduce i dati da visualizzare in codice html.
– Presenter/Interactor: questo layer ha lo scopo sia di predisporre i dati grezzi per la visualizzazione da parte dell’utente (vengono create le tabelle o le liste) sia di gestire le azioni dell’utente (analizzare i contenuti delle form, gestire la pressione di pulsanti, validare le informazioni, ecc.) trasformandole in dati utilizzabili dal core applicativo.
– Domain Model/Business Logic: questo layer è il core applicativo: è qui che i dati vengono effettivamente gestiti, dove vengono implementati gli algoritmi di calcolo, ricerca, ecc. Contiene le logiche applicative, ed è strutturato in modo tale da non tenere conto della loro rappresentazione (ad esempio in html) e nemmeno del modo in cui verranno salvate (ad esempio in Json/XML) cose di cui si occupano moduli specifici. Questo modulo contiene il “Domain Model” ovvero l’astrazione software dell’architettura dell’informazione applicativa, non solo dei dati ma anche di tutti gli oggetti/classi/funzioni che li manipolano, ovvero la cosiddetta “Business Logic”.
– Data Access: in questo layer i dati vengono inviati/ricevuti da un server remoto, oppure salvati nella memoria locale. È in questo layer che i dati vengono trasformati nei formati adatti per la trasmissione/ricezione/caricamento/salvataggio. Nelle applicazioni web client è costituito dai componenti che eseguono le operazioni AJAX, nelle applicazioni server sono costituiti dai componenti DAO, o nelle applicazioni più recenti il compito è svolto da un ORM.
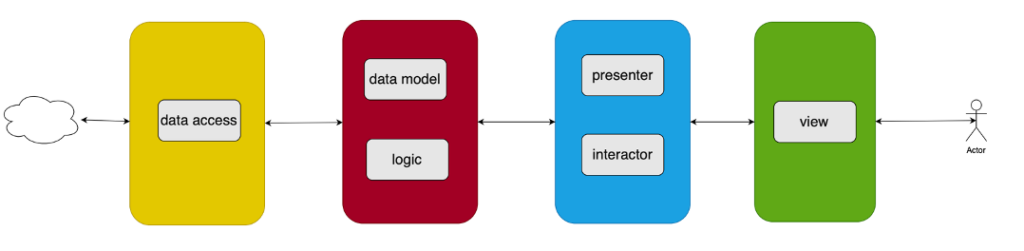
Nelle applicazioni più grandi ad un layer può corrispondere più di un modulo, tuttavia la suddivisione concettuale rimane questa. Vedremo come questo modello concettuale viene replicato anche nelle applicazioni distribuite.
Alcune architetture molto diffuse
Naturalmente questo schema generale va poi declinato per l’applicazione specifica, ma questa struttura modulare è molto comune e con alcune varianti è presente nella grandissima maggioranza delle applicazioni web e viene utilizzata da moltissimi framework presenti in quasi tutti i linguaggi di programmazione per realizzare applicazioni utente. Alcune delle più note applicazioni sono:
MVC, Model-View-Controller: in questo caso il modulo View incorpora il componente presenter ed ha un ruolo attivo, mentre il componente logic è incorporato insieme all’interactor nel modulo Controller. Il Model contiene solo i dati ed ha un ruolo passivo. Inoltre il model comunica direttamente con la View secondo uno schema triangolare. È probabilmente l’architettura più famosa, ed è usata dalla maggior parte dei framework per applicazioni Web 2.0 quindi PHP (tutti i framework), Java (Spring), Ruby (Rails), C# (ASP.NET MVC), al punto che i framework web hanno come “marchio di fabbrica” l’architettura MVC. Lato client Javascript è usato da Angular e VueJs.
MVP, Model-View-Presenter: questo modello ricalca abbastanza fedelmente quello presente in figura. Il modulo View ha un ruolo passivo, mentre Presenter e Model hanno ruoli più attivi. È una architettura usata in ambito desktop da numerosi framework come Java Swing, Windows Forms, e alcuni frameworks PHP (come Laravel). È infine alla base del modello React/Redux (JS) ma anche Angular può usare MVP.
MVVM: Model-View-ViewModel: questo modello si differenza dallo schema soprastante perchè pur mantenendo una struttura lineare come MVP i componenti di logica ed una porzione significativa di dati sono spostati nel ViewModel. MVVM è il modello architetturale ufficiale di Android ma di fatto è quello che ricalca meglio iOS (dove il ViewModel si chiama ViewController). Merita una menzione anche l’architettura VIPER (View Interactor Presenter Entity Router) molto usata in iOS dove sono presenti 5 layer, quattro coi ruoli sopra descritti, mentre il servizio Router gestisce i collegamenti tra le pagine dell’applicazione.
Come si vede nessuna delle architetture popolari fa cenno al layer di data access. In alcune implementazioni il data access è inglobato nel modulo Model (specie se si usa DAO), in altre si usano gli ORM. Va poi considerato che nelle applicazioni distribuite il layer “data-access” è spesso un middleware. Va comunque considerato come un layer concettualmente separato: il modo in cui si manipolano i dati di un Domain Model rappresentano una astrazione che può differire dal modo in cui i dati sono effettivamente salvati in un database (es. SQL) o trasmessi (es. XML).
[1] in realtà i principi che regolano la realizzazione di componenti sono 5, che formano l’acronimo SOLID, dove appunto la S è solo il primo ma il più importante. Gli altri sono Open/Close (aperto all’estensione, chiuso alla modifica, un corollario della SRP), Liskov (una sottoclasse può sostituire una classe padre, che è il principio generale di una architettura a plugin insieme alla Dependency Inversion), Interface Segregation (suddividere le interfacce in microinterfacce in modo da spezzare le responsabilità), e Dependency Inversion (le dipendenze sono sempre verso Interfacce, non oggetti).
[2] Questo principio si chiama principio di segregazione delle interfacce (la I di SOLID).
[3] Questo principio è il principio di sostituzione di Liskov (la L di SOLID).