
Applicazioni distribuite
Per seguire questa lezione è fortemente raccomandato di aver approfondito il concetto di architetture visto in questa lezione.
Applicazione monolitica vs applicazione distribuita
Prendiamo prima di tutto la definizione di questi due approcci alla realizzazione di applicazioni.
- Applicazione monolitica: applicazione che in fase di build va a distribuire un unico eseguibile che girerà su una unica macchina.
- Applicazione distribuita: applicazione che è costituita da diversi eseguibili che girano su macchine differenti connesse tra loro in rete (Internet o intranet).
Il modello di una applicazione distribuita è ad esempio quello della seguente figura (applicazione con architettura client-server SOA) .
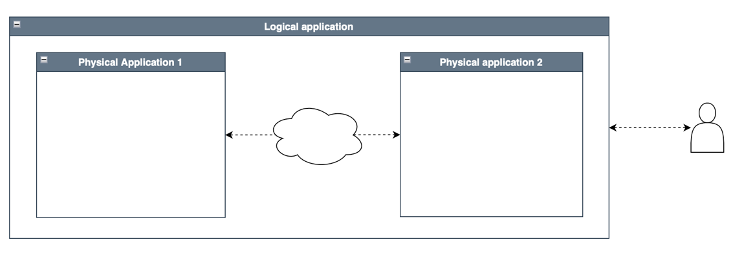
La scelta che guida se una applicazione deve essere distribuita o monolitica è legata alla gestione e la manipolazione dell’informazione, ma anche esigenze di sicurezza (dove collocare i dati), prestazioni delle macchine (il carico di lavoro più pesante viene dato alla macchina più costosa ma anche prestazionale), scalabilità (accrescere le risorse senza toccare tutta l’applicazione).
Se l’intera applicazione risiede su una sola macchina locale, si ha una applicazione monolitica locale. Un esempio di questo tipo di applicazioni è la suite Office, oppure un videogioco offline. E’ il modello tradizionale di applicazione che di norma si trova sui personal computer.
Se l’applicazione risiede invece interamente su una macchina remota, e l’utente interagisce con essa esclusivamente con un terminale (anche web) che non svolge nessuna attività di manipolazione dati, allora l’applicazione è detta monolitica remota. Un esempio di questo tipo di applicazioni sono i siti web.
Se invece l’applicazione per funzionare necessita di risorse software (cioè moduli applicativi) presenti su più macchine, ad esempio sia sulla macchina locale che su quella remota, o su più macchine remote, allora l’applicazione è distribuita. Un esempio di questo tipo di applicazioni sono le web applications, i videogiochi online, i motori di ricerca, le applicazioni di IA.
Le due architetture più importanti di applicazione distribuita il modello “client-server” (un server che eroga e riceve dati, un client che interagisce con l’utente) ed il modello “peer-to-peer (più macchine che lavorano insieme per un unico obiettivo, come ad esempio i motori di ricerca, i software di blockchain, gli LLM, ecc.). Questi due modelli replicano gli approcci di programmazione parallela “domain decomposition” e “functional decomposition”.
Ecco tre scenari di utilizzo distribuito in un contesto client-server:
- Poter gestire processi/informazioni/algoritmi complessi su una macchina remota e le logiche di interazione e visualizzazione sulla macchina dell’utente: un esempio di questo sono le applicazioni di home banking.
- Poter gestire grandi moli di dati su una macchina remota, e l’intera logica applicativa sulla macchina dell’utente: un esemp-io di questo sono applicazioni di posta elettronica online (ad esempio Gmail);
- Poter eseguire applicazioni molto complesse su server, e lasciare al terminale utente il solo compito di gestire la visualizzazione dei dati e l’interazione con l’utente: un esempio di questo è il terminale Bancomat o siti di ecommerce come Amazon.
Sono possibili però anche scenari peer-to-peer;
- Più componenti che collaborano tra loro per distribuire una operazione di calcolo complessa, o condividere grandi moli di dati: ad esempio i motori di ricerca;
- Più componenti che collaborano tra loro per gestire molti utenti: ad esempio i server web.
In questa sede ci concentreremo in particolare sulle applicazioni distribuite basate su architettura client-server su Internet.
Client-server multilayer
Per capire come funziona una applicazione distribuita bisogna tenere ben presenti i concetti chiave di architettura del software. Come abbiamo già visto la maggior parte delle applicazioni sono oggi progettate in componenti e moduli che si basano sul concetto di layer e di separazione delle responsabilità.
Questo concetto consiste nel dividere l’applicazione in strati di componenti omogenei (detti layer) ognuno con un proprio ruolo ben definito e con la capacità di comunicare limitatamente con gli strati adiacenti.
L’obiettivo quello di è semplificare lo sviluppo e suddividere la complessità secondo il modello di programmazione “divide et impera”.
Tra i modelli basati su layer uno dei più diffusi è basato sui seguenti layers:
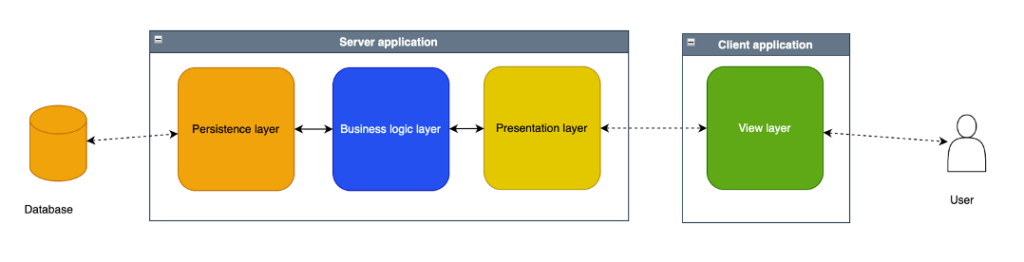
- Un layer di accesso ai dati/documenti, denominato “data access”, che contiene le funzioni di accesso ai dati, e il loro adattamento al media utilizzato (ad esempio la trasformazione del modello dati in una query SQL o in un tracciato XML). Siccome l’obiettivo è gestire il salvataggio su strutture di dati persistenti (database) si parla di “persistence layer”.
- un layer di manipolazione dei dati, denominato “business logic”, che contiene il modello concenttuale dei dati (ad esempio tramite classi ed oggetti) e le logiche applicative. Questo layer si occupa di creare un modello concettuale e manipolarlo, e si usa anche il termine “Domain Model” che rappresenta il “dominio” dell’informazione.
- Un layer di presentazione dei dati all’utente, che elabora le informazioni, le filtra e le adatta alla visualizzazione/consumo dell’utente. Inoltre le azioni dell’utente che vengono dall’interfaccia di visualizzazione vengono preelaborate, validate e filtrate. Questo layer fa da tramite tra il livello logico e quello di visualizzazione.
- Un layer di visualizzazione dei dati, che in genera ha poca o nessuna logica, e si occupa di mostrare all’utenti i contenuti ed interagire con loro (ad esempio tramite una pagina web).
In figura la schematizzazione di questo modello, in una applicazione monolitica.
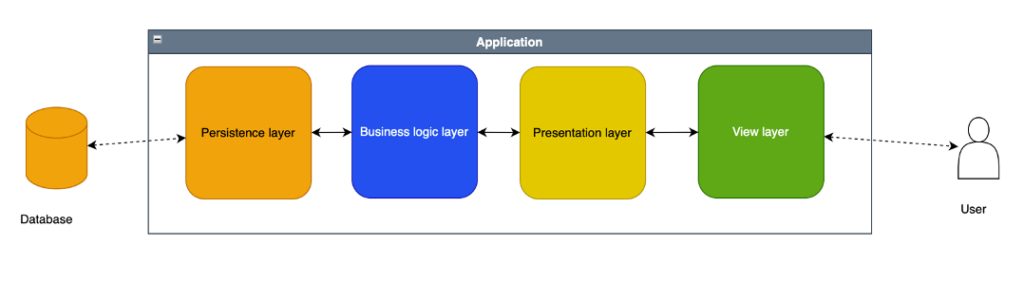
Modelli di architetture distribuite a layer client-server
Con questa tipologia di divisione interna è possibile progettare una versione distribuita, semplicemente separando uno o più layer in applicazioni separate connesse tra loro in rete.
Qui i tre esempi descritti in precedenza:
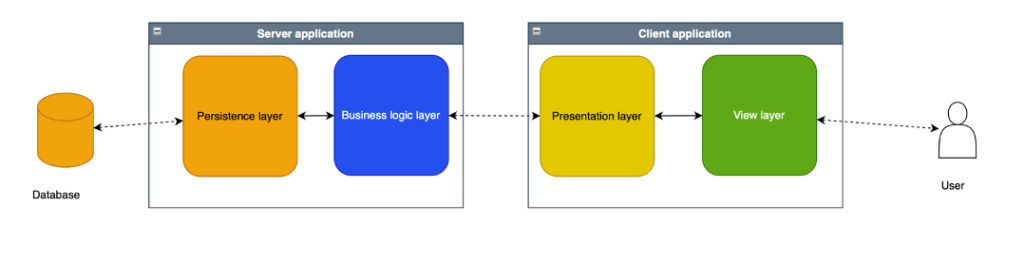
- Caso home banking: la gestione dei dati e le business logic sono interamente lato server, mentre la presentazione e la visualizzazione sono a carico del client.
- Caso Gmail: in questo caso anche la logica di business è sviluppata lato client.
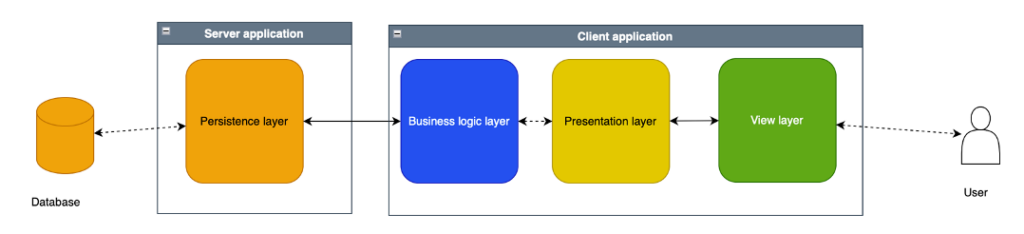
- Caso Amazon/CMS/Web dinamico: l’applicazione lato client contiene poco o nulla a livello di codice ad alto livello se non la semplice validazione dei dati e poco altro.
Quali sono i vantaggi delle applicazioni distribuite?
- È possibile suddividere il lavoro assegnando due team che possono operare in parallelo sui due prodotti;
- È possibile scrivere una applicazione anche con logiche molto sofisticate che gira correttamente anche su client poco potenti, perché l’elaborazione avviene altrove;
- È possibile centralizzare la sicurezza;
- E’ possibile modificare una porzione dell’applicazione in modo indipendente dall’altra;
- E’ possibile usare tecnologie differenti;
- E’ possibile utilizzare team differenti in luoghi differenti
Quali sono gli svantaggi?
- Aumenta la complessità;
- Va scritto un middleware (vedi sotto) per ogni connessione
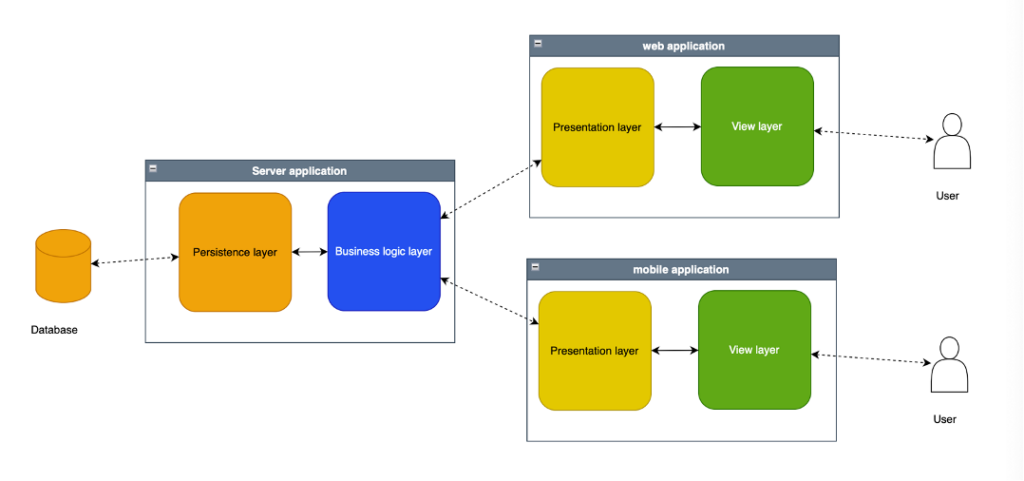
Una applicazione distribuita permette di realizzare scenari più articolati dove allo stesso backend possono corrispondere più frontend.
Qui un esempio in stile “home banking” dove però abbiamo un client web e un client mobile.
Il middleware
Il middleware è un (piccolo) layer software che rende possibile la collaborazione tra due componenti remoti della stessa applicazione distribuita. Il middleware è formato da componenti che insieme svolgono il ruolo di:
- intermediazione tra componenti software differenti, e non necessariamente sulla stessa macchina
- strumento attraverso sui avviene la comunicazione di comandi e dati
- metodi e strumenti per l’interrogazione, la risposta e lo scambio dati.
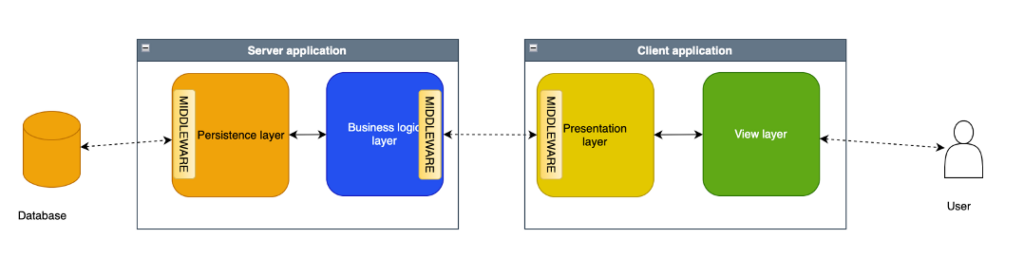
Qui un esempio
L’obiettivo del middleware è fornire una interfaccia di programmazione (detta API) che simula il comportamento del componente esterno come se fosse interno.
Nell’esempio sopra indicato:
- il middleware che connette il persistence layer al database fornisce una API per interrogare il database, cioè un insieme di classi ed oggetti che internamente implementano la chiamata al database e le operazioni come query di inserimento o caricamento;
- il middleware che connette il budiness logic layer al presentation layer crea lato server una API tramite connessione http che permette al client, di interagire con lo strato adiacente che però si trova sul server;
Il middleware è efficace quando riesce a “nascondere” l’esistenza di una applicazione esterna e a garantire allo sviluppatore la medesima coerenza di sviluppo che avrebbe interagendo con un componente locale.
Architettura a microservizi
Le applicazioni multilayer prevedono moduli sono organizzati in layer ognuno responsabile di una parte dell’applicazione, come l’interfaccia API, la presentazione delle informazioni, la gestione dei dati, ecc.
Ad esempio un applicativo di ecommerce prevede una funzione per gestire l’autenticazione utente, una funzione per gestire il catalogo ed una per gestire gli ordini. Ma l’applicativo, anche se distribuito, resta concettualmente solo uno: tutte le funzionalità “attraversano” i layer applicativi e ogni layer (middleware, presentazione, business logic) implementerà tutte le funzioni per la parte che compete loro.
Questo modello prevede quindi un unico ciclo di sviluppo, rilascio e supporto. Se ad esempio si scopre che la gestione ordini ha un bug, quando viene sistemato bisogna rilasciare l’intera applicazione. Non solo, ma se è necessario che le risorse a disposizione siano previste per l’applicazione nella sua interessa.
Questa cosa detta in questo modo, può apparire strana. Facciamo però questa considerazione: non è detto che date le N funzionalità di una applicazione, queste abbiano pari importanza e carico di lavoro una volta in esecuzione. Ad esempio una applicazione di ecommerce riceve molte più richieste di ricerca prodotti che di acquisti veri e propri, mentre la login è l’operazione che che si fa meno spesso.
Ha senso quindi senso invece un approccio dove invece di implementare tutte le funzioni nello stesso applicativo, si crea un applicativo indipendente per ciascuna delle funzioni, ognuno coi suoi layer, il suo sviluppo, test e rilascio.
Certo, per il programmatore non è pratico suddividere l’applicazione in tante mini applicazioni perchè obbliga sicuramente a duplicare alcune parti dell’applicazione (ad esempio classi astratte, interfacce, ecc.) Inoltre per ogni funzione andrebbero realizzate altrettanti pacchetti di build in parallelo, da testare e rilasciare separatamente. Tuttavia con l’avvento della automazione dei rilasci e degli ambienti container questo problema è in gran parte risolto, perchè è più semplice gestire molte mini applicazioni al posto di una sola.
In ogni caso ci sono scenari dove i vantaggi superano gli svantaggi di una soluzione di questo tipo. Un esempio sono le applicazioni SOA dove i servizi sono suddivisi in mini applicazioni dette microservizi.
Nel nostro esempio avremo quindi un microservizio di autenticazione, uno di catalogo ed uno di ordini. Questo significa che ogni applicazione ha un suo ciclo di sviluppo/rilascio indipendente, anche se poi in esecuzione essi vengono eseguiti comunque in modo interdipendente e collegato tra loro.
Ma allora a cosa servono?
- viene gestito meglio il “basso accoppiamento”: ogni servizio comunica con gli altri solo con API remote; bugfix ed evoluzione sono indipendenti, una modifica non richiede di verificare tutta l’applicazione;
- si ottiene una scalabilità molto più granulare: come detto sopra un microservizio può essere singolarmente potenziato senza dover aumentare le risorse necessarie per gli altri meno utilizzati.
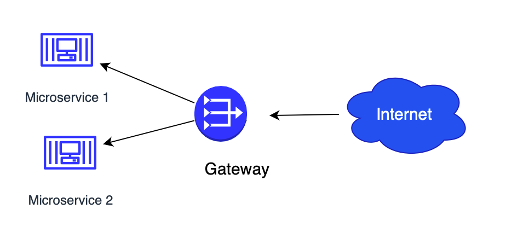
Qui uno schema di una architettura con due microservizi.
Nelle applicazioni più complesse può diventare complicato gestire il rilascio di gruppi consistenti di microservizi e per questo è necessario predisporre strumenti per la loro gestione.
Ad esempio uno dei prodotti più noti è Kubernetes, uno strumento che permette di gestire, attivare e avviare molti microservizi insieme, e tramite configurazione mantenere funzionante il sistema attivando e disattivando cluster di microservizi in modo dinamico.
I microservizi, come tutte le grandi innovazioni, rischiano tuttavia di essere utilizzati in modo improprio. Non vanno mai dimenticati i costi connessi all’uso degli stessi:
- una maggiore complessità progettuale (molti componenti software vanno replicati, con relativo debito tecnico);
- una maggiore complessità nei rilasci e nella manutenzione di molti applicativi indipendenti.
Come sempre in ingegneria del software vanno valutati pro e contro di queste soluzioni.