
Ambienti di esecuzione del software
Introduzione
Nella lezione su DevOps abbiamo introdotto alcuni concetti fondamentali:
– il rilascio è parte integrante del processo di produzione del software, e come tutte le altre fasi richiede una progettazione preliminare non può essere improvvisato a valle dello sviluppo;
– il rilascio richiede la collaborazione di soggetti con competenze e responsabilità differenti: sviluppatori, sisemisti e QA: dalla loro collaborazione nasce la metodologia DevOps, che si basa sul principio di responsabilità condivisa, rilasci incrementali ed automazione.
In questa lezione ci concentriamo invece sulle tematiche di rilascio che sono sia progettuali che tecnologiche, quindi ci concentreremo nel fare una analisi delle tecnologie a disposizione per permetterci quale sia l’ambiente di esecuzione più adatti, e l’attenzione sarà rivolta principalmente alle applicazioni lato server, in particolare per il web, visto che sono le applicazioni di gran lunga più diffuse. Ma un discorso analogo vale per le applicazioni web client, mobile, tv e desktop, anche se in tutti questi casi l’analisi è più semplice, come risulterà evidente proprio in questa lezione.
Partiamo con una domanda: se con DevOps è possibile automatizzare sia il rilascio (dello sviluppatore) che il test (del Q/A) riducendo l’intervento umano, non è possibile automatizzare anche la gestione degli ambienti?
Per rispondere a questa domanda è necessario approfondire diverse tematiche tra loro intrecciate:
- la stima del carico di lavoro;
- le tecnologie e le infrastrutture oggi disponibili;
- l’architettura del software.
Le stime di carico e la scalabilità
Per ogni rilascio deve essere previsto un ambiente adeguato al software che verrà rilasciato e ai dati che dovrà elaborare. Un ambiente non deve essere sottodimensionato rispetto al carico di lavoro che dovrà gestire. Il progettista del software pertanto dovrà definire le caratteristiche di tutti gli ambienti previsti e per tutte le versioni previste (per quei casi per cui è previsto lo sviluppo di più versioni in contemporanea). Per ognuno di questi ambienti è pertanto necessaria una stima di carico[2] per dimensionare correttamente l’infrastruttura hardware software minima sufficiente.
Ad esempio una applicazione di registro elettronico dovrà tenere conto del numero di studenti ed insegnanti, del numero di materie, e quindi del numero di accessi contemporanei e del tipo di carico medio per ogni attività. Una attività sicuramente non complessa in quanto il numero di studenti è conosciuto a priori. Più complessa la gestione di un ecommerce: va analizzato il tempo di utilizzo medio per ogni utente, quali risorse utilizza e quanti utenti presumibilmente useranno il sistema, ma vanno effettuati calcoli anche per i periodi e gli orari più intensi (es. Natale). Ancora più complesso stimare il carico di un servizio di streaming, perché bisogna fare delle ipotesi sulla capacità di calcolo dei sistemi client (se ad esempio usano il 4k o il full HD, se hanno fibra ottica o connessione 4G, ecc.) e sui picchi (durante la finale di Champions ci saranno molti più utenti collegati che in una mattinata di un giorno feriale). Un errore in questa previsione può portare, in caso di sovrastima, a sprecare risorse. In caso di sottostima, ad un blocco dei sistemi e quindi ad una negazione del servizio erogato.1
Come si può vedere nei casi più complessi la realtà si può facilmente discostare da queste stime, specie quando le stime non vengono nemmeno fatte, col risultato di avere ambienti sottoutilizzati (spreco di risorse) o sovrautilizzati (col rischio quindi di un Denial Of Service con perdita di disponibilità)[3].
Abbiamo quindi due problematiche: riuscire a stimare a priori in modo corretto il carico, e gestire situazioni di picco di carico temporanee. Per questa ragione la maggior parte dei progettisti tende a sovrastimare le risorse necessarie, onde evitare inutili rischi, ma il problema di fondo è che restano ragionamenti di buon senso, e abbiamo imparato che non si progetta il software col buon senso, ma con metodi ingegneristici.
Per questa ragione la stima delle prestazioni di un sistema non viene fatta col “buon senso” ma seguendo due strade:
- metodo sintetico: si fa un test di carico sul sistema utilizzando degli strumenti appositi su un ambiente di collaudo e poi si dimensiona opportunamente il carico stimato in proporzione ipotizzando gli utenti del sistema a partire da rilevazioni di applicazioni con simile numero di utenti. Ad esempio una applicazione di ecommerce fa un collaudo con 100 utenti in contemporanea, analizza il carico medio, e poi ipotizza di avere 10000 utenti in contemporanea e dispone una infrastruttura adeguata a quella stima;
- metodo analitico: utilizzando strumenti stocastici si calcola analiticamente il carico per utente e per numeri di utenti. La stima analitica è in generale se ben progettata altrettanto valida di quella sintetica, anche in questo caso comunque si fa sempre una ipotesi sul numero di utenti, ipotesi che può sempre essere smentita dalla realtà.
Resta irrisolvibile con la sola progettazione il tema della stima del numero di utenti a priori. In questo senso come vedremo che con la tecnologia si possono valutare delle soluzioni a posteriori, ovvero prevedere delle tecnologie che permettono la cosiddetta “scalabilità“: la capacità di un ambiente di adattarsi al carico di lavoro, dedicando poche risorse quando ci sono pochi utenti, e molte risorse quando ce ne sono tanti. Questo problema è senz’altro importante almeno quanto l’automatizzazione del rilascio.
Infrastruttura 3 tiers e cluster
Nel mondo web una soluzione comunemente adottata è quella di utilizzare una infrastruttura a tre livelli:
- un primo livello è costituito dal server web, che gestisce le richieste HTTP;
- un secondo livello è costituito dall’applicazione web: che elabora le richieste, svolge l’attività logico/applicativa, e predispone la risposta da restituire al server web;
- il terzo livello è il database, che gestisce la persistenza dei dati.
Davanti a questi è posto un bilanciatore di carico, una macchina che in base ad un algoritmo molto semplice (un round robin di solito) smista il traffico in entrata ai server web che a loro volta lo passano ai livelli interni.
In figura una implementazione semplice di questa infrastruttura, con un bilanciatore e due nodi. Ogni coppia di nodi (web server, application server, database server) è una copia identica dell’altra. In particolare il cluster di database ha i database perfettamente identici. Possono essere previste varianti anche più complesse con molti web server, ed anche all’interno possono essere previsti altri bilanciatori.

Questa infrastruttura punta a risolvere molte delle problematiche sopra descritte:
– è relativamente semplice adeguare il carico carico a posteriori: basta aggiungere nodi ai bilanciatori;
– si evita il rischio di down: le risorse sono ridondate, in modo che se una macchina ha un crash, ci sono altre macchine che la replicano mentre si ripara il guasto;
– separa la parte di interazione web, con quella applicativa, e questa dai dati, secondo il principio “una macchina – un software”.
Questa infrastruttura, ancora oggi estremamente diffusa nella maggior parte dei siti web, riesce a risolvere bene molte delle problematiche sopra descritte, ed in modo indipendente dalla tecnologia hardware utilizzata (che vedremo sotto), ma ha una forte dipendenza dalle tecnologie software. Se ad esempio si adatta bene al mondo Java/C# (che appunto prevedono un web server ed un application server separato) è un po’ meno per mondo PHP (dove il web server usa PHP come plugin e quindi i layer sono due) e del tutto inadatta per altre tecnologie come NodeJS e Python (dove il web server è un plugin della web application). C’è da dire che ad oggi il 90% dei siti web sono basati su Java, C# e PHP quindi questa infrastruttura resta molto diffusa.
Principali tecnologie di ambienti
La macchina fisica
Per gran parte della storia dell’informatica l’unico modo per dare un ambiente di esecuzione al software è stato quello di predisporre una macchina fisica, ad esempio un server fisico.
Il software che gira su una macchina fisica ha come limite massimo di prestazioni quelel fornite dalle risorse hardware di quella macchina. Se servono più risorse, è necessario predisporre una macchina più potente, reinstallare il sistema operativo, le librerie e il software e rimetterla online.
Quindi possiamo dire che le macchine fisiche sono limitate dal punto di vista della scalabilità.
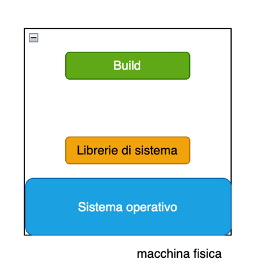
Nel mondo server in alcuni contesti questo è un vantaggio: una società che ha l’accesso fisico alle proprie macchine (in gergo on-premise “nell’edificio”) ne può controllare fisicamente l’installazione, l’accensione, il collegamento, ecc. anche e soprattutto per ragioni di sicurezza. Si pensi alle banche e alla gestione del denaro. Un discorso analogo vale per le telecomunicazioni, i servizi essenziali come acqua ed energia, e le pubbliche amministrazioni chiave. L’accesso on-premise, ovviamente costosissimo, ha anche un valore psicologico importante per il management e per chi amministra le macchine, ed è forse l’ultimo totem inviolabile della cultura informatica del XX secolo: “il server sta qui e da qui non si muove”!
In alternativa la macchina fisica può anche essere posta off-premise, “da remoto”, in una struttura dedicata, chiamata server farm, un edificio opportunamente realizzato con locali climatizzati, connessioni a larga banda, personale dedicato, ecc. attività che riduce i costi di gestione di una server farm locale.
La virtualizzazione
La virtualizzazione consiste nell’emulare via software un’intera macchina hardware in un’altra macchina, detta host, tramite un software di virtualizzazione.[4] Nella macchina virtuale (detta guest) viene quindi installato un sistema operativo compatibile che non ha alcun modo di capire se sta venendo eseguito su una macchina fisica o virtuale, e quindi di conseguenza tutte le applicazioni si comporteranno come su una macchina fisica.
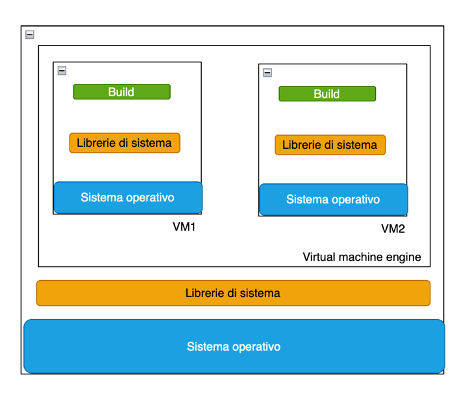
La virtualizzazione è resa possibile dai processori multi-core e dalla presenza hardware o software di un hypervisor[5] che gestisce l’astrazione delle risorse hardware dell’host verso le macchine guest.
Con la virtualizzazione è possibile:
– definire dinamicamente la memoria o la cpu virtuale di una macchina virtuale, espandere/contrarre dischi, ecc. senza mai mettere fisicamente mano alla macchina ospitante (host) purché abbia risorse sufficienti.
– duplicare una macchina guest in modo automatico;
– creare una rete locale virtuale tra macchine guest nello stesso host.
– sospendere o spegnere una macchina virtuale quando non serve.
– installare un sistema operativo guest diverso rispetto a quello della macchina host[6] anche in modalità “seamless” (usando la stessa interfaccia utente).
La virtualizzazione quindi garantisce un insieme di vantaggi :
– indipendenza dall’hardware fisico, è sufficiente un host abbastanza potente;
– indipendenza dal luogo fisico: non è necessario sapere dove si trova l’host;
– compatibilità piena: si può garantire che a partire dal pc dello sviluppatore alla produzione si possa utilizzare copie della stessa macchina virtuale, eliminando quindi rischi di incompatibilità hardware/software.
– viene garantito l’isolamento completo della macchina virtuale e quindi delle sue applicazioni, e quindi una forte predicibilità delle prestazioni.
Grazie alla virtualizzazione la server farm assume un ruolo più significativo, perchè centralizza la gestione delle risorse hardware dei sistemi host. Questo permette di razionalizzare i guest per diversi progetti e/o clienti[7]. In altri termini anzichè avere un server dedicato, con costi molto inferiori è possibile avere un sistema virtuale. Diventa quindi conveniente per la piccola e media industria affittare macchine virtuali da gestire (come le VPS, Virtual Private Server) con proprie risorse come se fossero macchine fisiche. Macchine che restano virtuali e che quindi possono ricevere upgrade o downgrade in base alle esigenze commerciali.
Prendiamo come esempio una società di ecommerce che possiede una VPS (Virtual Private Server) su cui installa il proprio web server di ecommerce. Questa società nota che in alcuni periodi dell’anno, come per Natale, il traffico aumenta parecchio. Grazie alla virtualizzazione può semplicemente raddoppiare la memoria e la CPU della macchina virtuale, ed avere (con un semplice riavvio) il doppio delle risorse per il tempo della promozione, per poi tornare alla configurazione meno costosa iniziale. Con un server fisico sarebbe stato più complicato perchè avrebbe richiesto un intervento tecnico manuale, ed in alcuni casi la reinstallazione del software.
Per l’utente anche amministratore della macchina virtuale l’accesso è sempre a basso livello, quindi tramite tecnologie come SSH, Desktop Remoto, FTP. Il sistema operativo Guest installato (di solito Linux per PHP/Java/.NET core o Windows per .NET) è completo e quindi fornisce le stesse funzionalità, e quindi è di fatto impossibile capire se la macchina è virtuale o fisica.
Containerizzazione
La virtualizzazione punta a replicare via software le caratteristiche di una macchina fisica. Questo come abbiamo visto garantisce flessibilità da una parte, e pieno controllo dall’altra da parte dei sistemisti. Eredita quindi dalla macchina fisica un modello concettuale secondo il quale prima si “crea” la macchina, e poi si installa un software che “gira” sulla macchina.
Questo modello, in ottica DevOps, rappresenta però anche una serie di svantaggi che andiamo ad analizzare.
1) Come visto nell’esempio se è vero che l’ecommerce può ridimensionare la macchina virtuale alla bisogna, questa operazione non è immediata e richiede comunque una stima, una verifica, la duplicazione della macchina, ed il riavvio. Non c’è modo di gestire un ridimensionamento dinamico in tempo reale in base al traffico.
2) Una macchina virtuale, poiché virtualizza un sistema operativo intero, è sovradimensionata per l’esecuzione di uno specifico software. Molte librerie del sistema operativo servono a far funzionare la macchina virtuale ma non servono all’applicazione che si sta facendo eseguire.
3) La macchina virtuale ha bisogno di tempo per avviarsi e fermarsi, ha quindi una ridotta efficienza operativa specie per quelle situazioni in cui si ha bisogno di usarla per poco tempo (es. test o collaudo).
4) Un software in esecuzione, quindi un processo, per funzionare non ha bisogno di una intera macchina dedicata ma solo di tempo di sistema operativo, di un isolamento di memoria e dati e di librerie di sistema operativo con accesso esclusivo. Non serve un computer dedicato con un intero sistema operativo (fisico o virtuale) per fornire queste risorse.
Il concetto di container nasce proprio da questo. Esso consiste in un pacchetto che contiene sia la build dell’applicazione, tutte le librerie e le risorse di ambiente per farla funzionare (i runtime dei linguaggi, le risorse di rete, ecc.).
Il container garantisce di fornire tutte le risorse necessarie per essere eseguito in modo isolato da un “container engine“[8], che si occupa di eseguire il container, a garantirne i servizi e l’isolamento. Il container va quindi pensato come se fosse una specie “bolla” in cui verrà eseguito il software, all’interno non di una macchina host, ma un container engine host. Sarà il container engine a decidere se serve una macchina virtuale dedicata, oppure una condivisa tra più container o anche nessuna macchina virtuale. Per eseguire la bolla in ogni caso non vengono usate risorse dedicate apposta: sarà l’engine a decidere cosa usare in base alla configurazione e le necessità effettive.
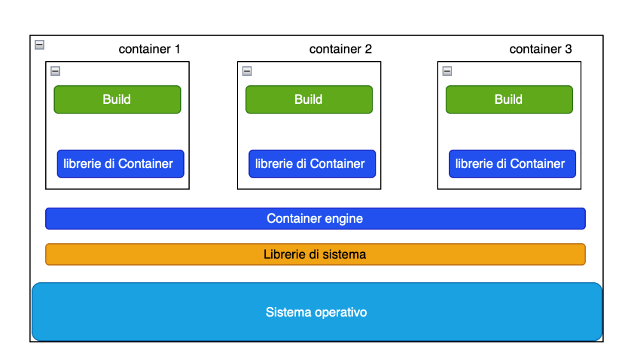
Il modello basato su una macchina (fisica o virtuale) su cui gira del software viene superato con un modello si crea una ambiente di esecuzione intorno al container, e si decide in base al contesto che tipo di macchina usare, se virtuale o reale, in modo dinamico. I container quando vengono eseguiti richiedono molte meno risorse, ed infine è più facile automatizzare la creazione e l’esecuzione dei container, in quanto sono in tutto e per tutto puri artefatti software.
La metodologia tradizionale di rilascio come abbiamo visto consiste nei seguenti passaggi:
– creazione della build;
– installazione della stessa su una macchina preconfigurata;
– esecuzione.
Col modello a container i passaggi diventano questi:
– creazione della build e del relativo container;
– esecuzione del container;
– esecuzione dell’applicazione.
Con questo sistema è possibile automatizzare anche il rilascio includendolo nella metodologia DevOps. Inoltre grazie ai container si ottiene una più facile separazione di responsabilità tra sviluppatori e sistemisti: i primi creano i container e quindi riescono a fornire ad operations non solo la build ma anche tutte le informazioni necessarie per far funzionare l’applicazione, tramite la configurazione dei container. I secondi lavorano ad un livello più alto: predispongono un ambiente adeguato in cui far eseguire i container engine, configurare lo stato generale del sistema e delle applicazioni tramite strumenti di monitoraggio e contro. I container gireranno nel contesto del loro engine, che fornirà le risorse necessarie in modo dinamico, a differenza della macchina virtuale.
Il software che gira dentro il container continuerà a lavorare come se si trovasse su una macchina fisica, in modo del tutto trasparente per chi sviluppa il software.
La containerizzazione infine spezza il legame tra software ed hardware. Per il programmatore il contesto di esecuzione del software diventa praticamente irrilevante, sul suo computer non deve nemmeno creare la macchina virtuale, è sufficiente creare il container. Per il sistemista la tecnologia con cui è sviluppato il prodotto (es. Java, PHP, Node, Python, ecc.) diventa irrilevante, perché questa è installata dal container in base alle necessità, e può quindi occuparsi dell’infrastruttura generale senza occuparsi di aspetti di dettaglio.
Grazie a questi sistemi si risolve quindi il grande problema della scalabilità in modo dinamico ed in tempo reale. Siccome tutti i sistemi di deploy sono del tutto automatizzati, in base al traffico è possibile definire degli algoritmi che scalano la capacità lato server semplicemente attivando nuovi container quando necessari, e reagendo immediatamente a picchi di traffico o di richieste.
il Cloud
Le server farm con i servizi di containerizzazione compiono un ulteriore salto evolutivo perché rende possibile separare del tutto lo sviluppo/test dalle attività di Operations, e quindi per una società che produce software è possibile esternalizzare presso aziende specializzate tutti i possibili servizi di rilascio e infrastruttura che si occuperanno direttamente e in modo indipendente di tutte le operazioni a basso livello, installazione, configurazione, sicurezza, ecc. Il carico di responsabilità di Operations diventa quindi ad alto livello, in gran parte automatizzato e gestibile da dashboard visuali e configurazioni.
Questo salto evolutivo che fa evolvere la server farm da semplice fornitore di macchine fisiche o vituali ad offrire vere e proprie dashboard di supporto al rilascio viene oggi commercialmente chiamato Cloud, dove il concetto di “nuvola” vuole rendere l’idea estrema di delocalizzazione e dematerizzazione.
Il Cloud consiste in un insieme di servizi ad alto livello in cui sono nascosti al cliente del servizio (cioè al programmatore, al sistemista, al tester, fino all’utente finale) i dettagli implementativi, l’infrastruttura sottostante e perfino la localizzazione geografica di questa infrastruttura.
Sempre commercialmente oggi sono universalmente individuati tre tipi di servizio che vanno ad identificare, in base al tipo di astrazione, la tipologia di servizio offerto:
| Tipologia | Descrizione | Utilizzo |
| IaaS (Infrastructure as a Service) | E’ il nome dato ai servizi di virtualizzazione, quindi con una macchina virtuale, con accesso a basso livello. | E’ utilizzato dai clienti che hanno una propria infrastruttura di Operations e che vogliono avere il pieno controllo delle proprie macchine remote, pur non disponendo di una infrastruttura fisica. |
| PaaS (Platform as a Service) | E’ il nome dato ai servizi che prevedono containerizzazione, quindi con servizi ad alto livello per il rilascio e gestione di applicazioni. | E’ utilizzato da clienti che hanno una ridotta (o nessuna) infrastruttura di Operations e/o che preferiscono avere un ecosistema di gestione dei rilasci e della produzione gestibile tramite dashboard e strumenti automatici. |
| SaaS (Service as a Service) | E’ il nome dato a servizi già pronti, che forniscono applicativi che non vanno installati ma sono usabili da remoto con interfacce locali (in particolare Web ma anche videogiochi o app dedicate). | E’ utilizzato da clienti che non hanno alcuna infrastruttura tecnica (nè di sviluppo nè Operations) ma hanno bisogno di di servizi e applicazioni accessibili su Internet da qualunque client. |
Cambia anche il modello di commercializzazione: a fianco al tradizionale modello di affitto su base mensile/annuale, viene introdotto il modello basato sul “pay per use” ovvero quello dove il sistema non ha costi fissi, ma si paga solo quando è utilizzato e per quanto viene utilizzato, utile per le piccole aziende che possono gestire un investimento minimo iniziale.
Il Cloud offre una grande opportunità ed è alla base del successo dello sviluppo di servizi Internet nell’ultimo decennio, specie alle piccole aziende e sviluppatori, ma nella valutazione degli innegabili pro non vanno anche dimenticati i possibili rischi:
– riduce l’autonomia tecnica dell’azienda di sviluppare una propria infrastruttura (specie con PaaS e SaaS) che deve quindi dipendere, commercialmente ma anche tecnicamente, dal fornitore di servizi;
– comporta dei rischi nella gestione dei dati, del backup, della migrazione ed anche di sicurezza sulla privacy dei dati stessi;
– comporta un insieme di problematiche di natura economica e politica: la presenza di dati privati in server cloud non garantisce che questi dati non siano poi messi a disposizione, non sempre in modo lecito, di organizzazioni di controllo e di governi di altri Paesi, sia per spionaggio industriale che politico. In questo senso esistono numerose legislazioni recenti che vanno proprio ad intervenire proprio su questo aspetto, obbligando i fornitori di servizi a tenere i server in una determinata area territoriale o in un determinato Stato.
– aumenta il digital divide, perchè il Cloud presuppone banda larga illimitata, una risorsa non disponibile in parte dei paesi industrializzati ed in gran parte dei paesi meno industrializzati.
– infine favorisce le grandi Corporations, che centralizzano, con grandi investimenti in hardware e software servizi di cui diventano di fatto monopolisti impedendo di fatto di trovare alternative valide ed in definitiva riducendo l’evoluzione tecnologica.
Nella scelta quindi dell’infrastruttura tecnologica bisogna quindi soppesare pro e contro della scelta di una infrastruttura cloud ponendo quindi la massima attenzione sia ai vantaggi che ai rischi che tale scelta comporta.
[1] Si ricorda che il progettista (o architect) ha 3 obiettivi: definire l’architettura dell’informazione, del software e dell’infrastruttura su cui girerà, attività poi realizzate e verificate proprio dai team di sviluppo, operations e QA.
[2] L’analisi della stima di carico è una attività ingegneristica che fa uso (nei progetti più grandi) di analisi stocastica analitica e numerica, concettualmente simile a quella che si fa per stimare il traffico di una strada o il carico di un edificio.
[3] La disponibilità di un sistema software è un fattore critico di successo. Ad esempio un “down” (mancata disponibilità) di un sistema bancario, o un sito di informazione, o una pubblica amministrazione non solo provoca disservizio ma può generare per le applicazioni più importanti conseguenze come crollo di azioni in Borsa, allarmi antiterrorismo, intervento delle autorità e della magistratura, ecc. oltre ad avere evidenti ripercussioni commerciali.
[4] I più comuni software di virtualizzazione sono VMWare o Virtualbox.
[5] l’hypervisor che agisce come un intermediario tra hardware fisico e macchine virtuali, con prestazioni quasi identiche ad una macchina fisica.
[6] Anche se ad oggi sussistono limiti relativi ad architetture di cpu differenti. Il codice anche se virtualizzato deve girare su un processore compatibile o essere tradotto in real time.
[7] Sono diverse le società operanti anche in Italia che offrono questo servizio, come Aruba, Tiscali,
[8] Il primo e più noto container engine si chiama Docker, un software del 2013 che permette di creare anche in automatico container a partire da script.
- E’ noto l’esempio del sito dell’INPS che durante la pandemia del 2020 andò in DOS (Denial of Service) per un picco di carico non previsto, quando i progettisti non seppero prevedere che milioni di utenti si sarebbero collegati per cercare di ottenere un rimborso dal governo per le partite IVA. ↩︎