
AJAX
Introduzione ad AJAX
AJAX (Asynchronous Javascript and XML1) è il nome con cui viene chiamata la funzione che usa Javascript nel browser per comunicare con servizi Internet, ed aggiornare quindi i contenuti visualizzati senza ricaricare la pagina.
Per capire il funzionamento di Ajax vediamo prima di tutto il funzionamento di un sito web tradizionale:
- Il browser richiede al server la pagina corrispondente alla URL
- Il server elabora la richiesta e restituisce una pagina HTML e tutti i suoi documenti collegati (CSS, JS, video, audio, ecc.) che insieme costituiscono una risorsa detta statica;
- Il browser riceve la risorsa e la elabora per mostrarla all’utente.
Il server è propriamente un server Web, cioè una applicazione che ha come scopo ricevere richieste da Internet e restituire risposte.
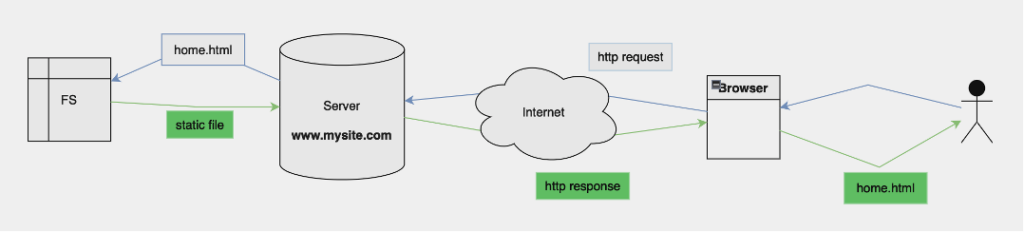
Una volta scaricata la pagina la connessione col server si chiude, e il contenuto viene gestito localmente dal browser. Se si vogliono aggiornamenti sui contenuti (ad esempio ricevere nuove notizie da un sito di informazione, nuovi post da un social, ecc.) bisogna necessariamente ricaricare di nuovo l’intera pagina. Lo stesso vale se si vogliono inviare contenuti (ad esempio un nuovo post, una email, ecc.) Questo significa che:
- l’utente sperimenta una interruzione dell’attività del browser, mentre viene ricaricata la pagina;
- bisogna riscaricare anche risorse che in realtà sono già presenti nella pagina precedenti (css, immagini, ecc.).
AJAX è una tecnologia che è stata introdotta per risolvere questo problema, infatti il meccanismo cambia perché per aggiornare/inviare contenuti la pagina non viene più ricaricata interamente, ma solo la porzione che deve cambiare. Il principio di funzionamento è questo:
- il browser la prima volta scarica la pagina web completa di HTML/CSS/JS ed altre risorse.
- Quando diventa necessario comunicare col server (perchè si richiedono nuovi dati o si devono inviare dati) viene aperta una connessione senza bloccare la pagina.
- Il server riceve la richiesta e risponde inviando o la porzione di pagina richiesta (metodo in realtà ormai obsoleto) oppure direttamente i dati.
- Al centro di tutto c’è l’applicazione Javascript, che gestisce l’intera comunicazione e l’aggiornamento della pagina Web.
Questo meccanismo rende completamente autonoma la pagina Web, che diventa una vera e propria applicazione, che gira interamente all’interno del contesto applicativo del browser e non richiede aggiornamenti di pagina. Questo tipo di applicazione assume il nome di RIA (Rich Internet Application).
Un esempio di RIA è Gmail. L’intera gestione delle mail è gestita da una applicazione Javascript nel browser, che si connette ad Internet solo per inviare e ricevere le mail, come una vera e propria applicazione stand alone. Altri esempi analoghi sono Google Docs, social come Instagram/Facebook/X, o anche applicazioni per la produttività come Canva o Lightroom, applicazioni di streaming video (Netflix, Amazon Prime Video, ecc.) ed infine molti videogiochi (va detto però che alcune di queste applicazioni utilizzano internamente librerie scritte in altri linguaggi, come C++ per migliorare le prestazioni).
Grazie ad AJAX, Javascript è in grado di sostituire la maggior parte delle applicazioni desktop e grazie a questa tecnologia vengono abbattute le barriere che esistono tra un pc, un tablet ed uno smartphone in termini di potenza di calcolo ed operazioni possibili. Questa tecnologia è così avanzata che anzi alcune applicazioni desktop e mobile sono in realtà delle RIA, come ad esempio il popolare IDE Visual Studio Code, scritto interamente in Javascript.
Protocollo HTTP
Per poter sviluppare con AJAX occorre comprendere bene il protocollo HTTP. Il protocollo HTTP è un protocollo di comunicazione a livello applicazione dello stack TCP/IP, che sta alla base di tutta la tecnologia del Web.
Questo protocollo prevede una comunicazione tra un client (cioè il browser) ed un server. Ma cosa è il server? Il
Il protocollo prevede che il client generi una richiesta HTTP (Http Request) e il server risponda con una risposta HTTP (Http Response).
Esso ha le seguenti caratteristiche distintive:
- Request e Response sono in formato testo, ma possono contenere dati binari codificati nel corpo della richiesta;
- è una connessione punto-punto: in altre parole solo due sono i nodi (host) coinvolti, il client ed il server;
- il client ha un ruolo attivo: solo il client può originare la richiesta verso il server, e ne attende la risposta.
- Il server è invece in attesa passiva di richieste dal client. Il Web service resta in attesa di richieste e ed elabora le risposte. Non è possibile inviare dati al client senza una richiesta.
- http è senza sessione. Ogni richiesta-risposta è sempre indipendente dalle altre. Non c’è modo, col solo protocollo http, sapere se la richiesta è parte di una sequenza oppure no.
- è opzionalmente previsto uno strato di sicurezza tramite protocollo TLS (che esegue la criptazione dei dati): combinati insieme danno origine al protocollo https.
HTTP Request
Il protcollo prevede una struttura predefinita per la richiesta.
La Request comprende 3 parti:
– una intestazione iniziale, che contiene la URL il protocollo e il metodo della chiamata. Il metodo indica il tipo di rhciesta. Le più comuni sono GET (ricezione dati), POST (invio di nuovi dati), PUT (modifica dei dati), DELETE (cancellazione dati), ma ne sono previsti anche altri.
– l’header della chiamata: contiene delle coppie chiave-valore che contengono informazioni di servizio della chiamata (es. dati autenticazione, formato dei dati della richiesta, cookies, ecc.).
– il body della chiamata: è un campo utilizzato per alcuni metodi (POST-PUT) e contiene i dati inviati al server.
La URL
La URL (Uniform Resource Locator) rappresenta in una stringa di testo che server per identificare in modo univoco le risorse richieste.
La URL identifica il protocollo (http, https), il server (cioè il nome della macchina, comprensiva di dominio e sottodominio), la porta (non obbligatorio indicarla se 80), il path della risorsa (identificata come un filesystem virtuale, non è obbligatorio e dipende dalla configurazione del server) ed eventuali richieste aggiuntive opzionali sulla risorsa stessa (detta query string, non obbligatoria nemmeno questa).
Qui la struttura della stringa:
http[s]://[thirdleveldomain.]secondlevel.firstleveldomain[:port]/[path/to/resource][?ke1=value1][&key2=value2]...
Le parti tra parentesi quadre sono opzionali
Qui qualche esempio di url con tutti gli elementi
http://www.myserver.org/path/to/resource.html?p1=1&p2=ciao
https://www.google.com
https://cipiaceinfo.it/docs/programmazione/javascript/ajaxHTTP Response
Una volta che il server elabora la request, prepara la Response, che contiene 3 parti:
– l’intestazione: essa indica con un codice di status l’esito della risposta (alcuni codici sono 200 OK, 401 non autorizzato, 404 non trovato, 500 errore, ecc.);
– l’header della risposta: contiene delle coppie chiave-valore che contengono informazioni di servizio (es., indica il formato dei dati inviati, regole di sicurezza, codici di autenticazione, cookies, ecc.) in modo analogo a quanto avviene con la richiesta
– il body della risposta con i contenuti inviati.
Web Service e API
Per poter funzionare, lato server viene implementata una speciale applicazione, detta Web Service, che fornisce al Web Server le funzionalità per interagire con l’applicazione client.
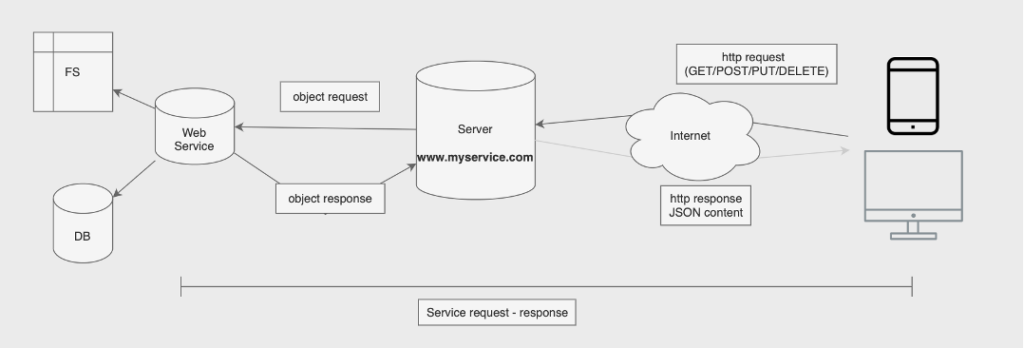
Un Web Service è descritto da una WEB API, ovvero un “contratto di utilizzo” che lo descrive tecnicamente.
Il concetto di API è comunque estremamente ampio e si usa estensivamente in qualsiasi ambito della programmazione e con qualsiasi paradigma. Per API si intende qualsiasi interfaccia/contratto che indica come deve essere utilizzato un deterninato oggetto software “remoto” da parte di un qualsiasi altro oggetto software, anche localmente ed anche nello stesso applicativo.
Nello specifico una Web API è definita da:
- URL
- metodo (GET, POST, ecc.)
- eventuali header richiesti (come l’autenticazione)
- struttura della URL della richiesta
- formato dati richiesta (ad esempio JSON) e sua struttura nel body per le POST/PUT
- formato dati risposta (ad esempio JSON) e sua struttura nel body di risposta
La struttura dei dati della risposta (come anche della richiesta per le richieste con body) sono chiamate tracciato di risposta (o richiesta) e sono un elemento fondamentale per capire come sono strutturati i dati ricevuti (o da inviare).
Le API possono essere descritte in modo formale, con opportuni linguaggi descrittivi.
Nel mondo Web sono previste due grandi famiglie di API:
- SOAP: fa uso del formato dati XML e specifiche definite dal linguaggio WSDL, usato per applicazioni commerciali di grandi dimensioni (enterprise) per Web Services scritti di norma in Java EE o .NET Framwork (C#);
- REST: fa uso del formato JSON (ma anche XML) e specifiche definite con vari sistemi (come Swagger OpenAPI), utilizzato di norma in tutto il resto del Web.
In questa sezione useremo soprattutto API REST, in formato JSON, con applicazioni Javascript.
Fetch
JS dispone di una funzione del BOM, chiamata fetch, che svolge le operazioni AJAX, ovvero gestisce richieste e risposte HTTP.
In realtà non è Javascript ad eseguire direttamente la chiamata: per farlo si appoggia ad una funzione interna del browser, che a sua volta effettua la chiamata e riceve la risposta.
Il meccanismo è descritto in questa figura.

Va tuttavia tenuto conto di un aspetto importante: la velocità di elaborazione di un computer è molto superiore alla velocità di una connessione Internet. In altri termini, in un secondo un computer moderno può elaborare decine o centinaia di migliaia di istruzioni per secondo. Invece la chiamata HTTP richiede tempo per la connessione di richiesta, l’elaborazione, la connessione di risposta, con tempi nell’ordine di 50-500ms, equivalenti a (molte) migliaia di istruzioni Javascript.
Javascript di norma non è progettato per fermarsi ad attendere la risposta.
Questo perché è un linguaggio di una pagina web che interagisce con l’utente, e se si bloccasse per ogni chiamata per mezzo secondo, darebbe la percezione all’utente di essere un sistema “lento”.
Il meccanismo che invece usa Javascript è invece asincrono, ovvero resta attivo mentre il browser esegue la richiesta HTTP. Se l’utente quindi interagisce con la pagina, Javascript può reagire senza bloccare la pagina, secondo il modello “evento-azione-reazione”.
Quando poi sarà ricevuta la risposta, Javascript la gestirà come un evento, elaborerà i dati e li restituirà all’utente.
Questo meccanismo è spiegato in dettaglio nella programmazione asincrona.
In questa sezione useremo il meccanismo di async-await, che rende la lettura del codice molto semplice, ma va ricordato che la fetch è una Promise.
GET
Per fare una richiesta GET occorre eseguire fetch con i parametri della richiesta (URL e talvolta anche alcuni parametri in Header). Qui un esempio:
(async () => {
const response = await fetch("https://dummyjson.com/users/filter?key=firstName&value=Sophia");
const data = await response.json();
console.log(data);
})();L’oggetto response contiene l’intera HTTP response. Nella stragrande maggioranza dei servizi Web, in particolare quelli presenti in queste lezionu, il formato di risposta è JSON. Occorre quindi estrarre dalla risposta il JSON con una seconda operazione await response.json() che estrae il body della risposta e lo converte da JSON ad oggetto Javascript (esegue cioè una JSON.parse())
La stampa del risultato è lasciata per esercizio.
POST
La chiamata POST serve per inviare una richiesta HTTP per inviare dati al server, ad esempio per inserire un nuovo dato inserito dall’utente, per eseguire una login ad un sito, per fare l’upload di immagini o video, per eseguire una ricerca dati complessa, ecc.
La struttura di una chiamata post sarà con la seguente sintassi:
(async () => {
const response = await fetch(url, {
method: "POST",
headers: {
"key": "value",
... // altre chiavi
},
body: content // deve essere una stringa
});
const data = await response.json();
console.log(data);
})();Vediamo un esempio:
(async () => {
const response = await fetch('https://dummyjson.com/users/add', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
firstName: 'Paolo',
lastName: 'Rossi',
age: 25
})
});
const data = await response.json();
console.log(data);
})();Questa fetch esegue una richiesta di invio dati (nel body) al servizio indicato.
PUT
La chiamata PUT serve per inviare una richiesta HTTP per modificare dati al server, ad esempio per modificare un dato presente sul server.
La struttura di una chiamata PUT sarà con la seguente sintassi (molto simile a POST).
(async () => {
const response = await fetch(url, {
method: "PUT",
headers: {
"key": "value",
... // altre chiavi
},
body: content // deve essere una stringa
});
const data = await response.json();
console.log(data);
})();In realtà cambia anche la URL, che va ad identificare la risorsa che si vuole modificare.
(async () => {
const response = await fetch('https://dummyjson.com/users/2', {
method: 'PUT',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
age: 26
})
});
const data = await response.json();
console.log(data);
})();Questa fetch esegue una richiesta di invio dati (nel body) al servizio indicato.
DELETE
La chiamata DELETE serve per inviare una richiesta HTTP per eliminare dati dal server.
La struttura di una chiamata DELETE sarà con la seguente sintassi (non è previsto body):
(async () => {
const response = await fetch(url, {
method: "DELETE",
});
const data = await response.json();
console.log(data);
})();La URL di norma identifica la risorsa da eliminare:
(async () => {
const response = await fetch('https://dummyjson.com/users/1', {
method: 'DELETE',
});
const data = await response.json();
console.log(data);
})();Riassunto
Fetch è la funzione che permette di comunicare tra l’applicazione Javascript e i servizi su Internet che forniscono e ricevono dati. La richiesta prevede una URL, un metodo, degli headers e un body. In base al metodo alcuni parametri sono obbligatori, altri sono facoltativi o vietati:
- Con GET si deve inviare la URL, opzionalmente anche gli headers, ma il body non è consentito. Si usa in generale per richiedere una risorsa identificata dalla URL.
- Con POST invece si inviano la URL, opzionalmente gli headers, ma è previsto l’invio anche del body. Si usa in generale quando dall’applicazione si vogliono inviare dei dati, ad esempio inseriti dall’utente.
- Con PUT si esegue una modifica dei dati presenti sul server
- Con DELETE si esegue una cancellazione dei dati presenti sul server
Gli headers sono delle coppie nome-valore che servono per mandare al server un insieme di informazioni ad esempio sul formato dati e sulla sicurezza. Gli headers sono fondamentali anche per gestire, in molti casi, anche la sicurezza, per esempio inviando un codice di sicurezza per autenticare il client.
Il body della richiesta contiene i dati da inviare al server. In queste lezioni useremo solo il formato JSON sia per i dati inviati che per quelli ricevuti, ma si ricorda che sul web sono presenti molti altri formati, come ad esempio XML.
La fetch è una funzione asincrona, che crea un oggetto promise. In alternativa come in questa lezione si può usare anche async-await.
[1] Asyncronous Javascript and XML (inizialmente si usava solo con il formato XML).
[2] la conversione è asincrona perché può richiedere un tempo significativo che potrebbe bloccare la richiesta.
[3] questo doppio passaggio della fetch potrebbe essere gestito con una sola promise. Nelle prossime lezioni scriveremo un metodo per gestire tutto con una sola promise.
- Si chiama così perché il formato di interscambio dati era, inizialmente, XML. Oggi il formato prevalente è JSON. ↩︎